In this article I describe how to load data from recurring full snapshots with Delta Live Tables relatively easily and elegantly into a bronze table without the amount of data exploding.
Introduction
In many data integration projects, it is not always easy to efficiently read data from source systems. Ideally, we would access the source system’s Change Data Capture (CDC) directly in order to capture only the actual changes since the last retrieval. This means that the source system indicates which records are new (insert), which records have changed (update) and which records have been deleted (delete). This significantly reduces the amount of data to be processed and enables almost real-time synchronisation. However, CDC mechanisms are not available in all systems. Older ERP systems, proprietary databases or external APIs in particular often only offer one way to retrieve the data: via periodic full snapshots.
This means that the entire relevant dataset, whether a few megabytes or several gigabytes in size, is exported as a complete copy at regular intervals.
A full snapshot always contains the current status of the data at a specific point in time. There is no differentiation between newly added, changed or deleted data records. Instead, you simply receive a snapshot of the entire table, hence the name snapshot.
This brings with it several challenges:
Large amounts of data: The entire table is exported each time, even if only a small part of the data has changed. This can lead to high memory consumption and long loading times.
No change tracking: Because it is always a complete copy, there is no direct information about which rows are new, which have changed or which have been deleted.
Efficient processing required: In order to get a grip on the volume of data, strategies must be developed that only save relevant changes and avoid redundancies.
The bad news first: The data volume of the raw data cannot be reduced. The full snapshots still have to be saved and processed, as we have no way of retrieving only the changes directly from the source.
But there is also good news: we can save storage space and compute in the next steps of the Medallion architecture. By cleverly processing the full snapshots with Delta Live Tables, we can simulate a change data capture approach. This means that we only save the actual changes in the Silver and Gold layers and avoid redundant data - which leads to significantly more efficient memory and performance utilisation.
Databricks as a platform and Delta Live Tables (DLT) as a framework
I use Databricks as the platform in this example. Databricks is a unified, open analytics platform for building, deploying, sharing, and maintaining enterprise-grade data, analytics, and AI solutions at scale. The Databricks Data Intelligence Platform integrates with cloud storage and security in your cloud account, and manages and deploys cloud infrastructure on your behalf. More information about Databricks can be found here: https://docs.databricks.com/aws/en/introduction/
DLT is a declarative framework designed to simplify the creation of reliable and maintainable extract, transform, and load (ETL) pipelines. You specify what data to ingest and how to transform it, and DLT automates key aspects of managing your data pipeline, including orchestration, compute management, monitoring, data quality enforcement, and error handling.
DLT is built on Apache Spark, but instead of defining your data pipelines using a series of separate Apache Spark tasks, you define streaming tables and materialized views that the system should create and the queries required to populate and update those streaming tables and materialized views.
More information about Delta Live Tables can be found here: https://learn.microsoft.com/de-de/azure/databricks/dlt/
Simulation of full snapshots: How to create test data
Before I can get down to the actual processing, I first need a realistic data basis. This means that I will generate periodic full snapshots, i.e. complete table copies that are exported at regular intervals. I have created a notebook for this purpose. I use the Python package faker to create the fake data: https://faker.readthedocs.io/
No large cluster is needed to create the test data; I create a small single node, which is relatively inexpensive. Alternatively, you could also use serverless.
Faker is not installed on the cluster by default and must therefore be installed first.
|
|
In the subsequent code, I need various other libraries, which I import and then I create an instance of Faker.
|
|
I use dbutils to create a widget that can be used to pass user input. I use this so that I can define a catalogue, which I use for my example. I also need a start date for the first snapshot.
|
|
In the next step, I define the volume in which I want to save the snapshots, as well as a table in which I write the test data. This table simulates the source system, i.e. a table from an OLTP source system.
A snapshot is to be created for each execution of the notebook. I want to simulate that a full snapshot is taken every day. To do this, I have to simulate a mechanism in my notebook that each run of the notebook should take place on a subsequent day. To do this, I use a CSV file in which I write the date. During the following run, the last date is read out, incremented by one and written back again. If I want to start the test again, I can simply delete the CSV file.
|
|
Now I create a function that creates the snapshot timestamp and returns the number of the iteration. The iteration is the number of times this notebook has already been executed. I derive the iteration from the row number in the CSV file.
The remaining logic of the function is relatively simple. If the CSV file does not exist, take the date from the widget, create the timestamp and save the timestamp in the CSV. If the CVS file already exists, read the last timestamp, increase the date by one day and add the new timestamp to the file.
|
|
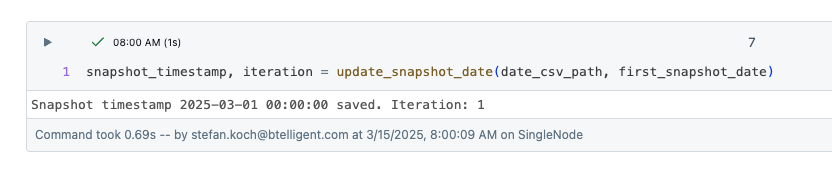
If I now call the function, I get the snapshot timestamp and the iteration.
It has created a CSV file in the volume.
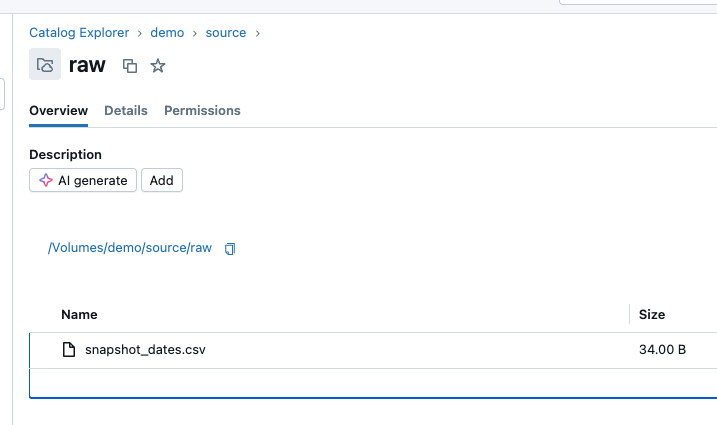
The contents look as expected.
The catalogue already exists in my environment, the remaining resources must be created if they do not already exist.
|
|
I now use Faker to generate the test data and save it in a dataframe. For the test data, I select personal data, which should simulate a customer table. I generate 5 data records, which is sufficient for my example.
|
|
The generated data then looks like this:
| primary_key | name | surname | date_of_birth | age |
|---|---|---|---|---|
| 36021eba-01cf-4c98-9020-4494069484c4 | Seth | Mendez | 2009-04-04 | 36 |
| 685951da-6ac0-4833-9b19-6c08156a73e5 | Steven | Mcdaniel | 2002-08-17 | 23 |
| 1dec1d8c-3631-490a-813e-85b4fb88547a | Amanda | Miller | 1972-05-14 | 97 |
| f1cdc2e5-062c-41bb-9e35-c49bd53600e8 | Kimberly | Johnson | 1918-07-10 | 23 |
| fd479292-c69a-4cd0-b066-e0b1731b6164 | Gregory | Wilson | 1924-04-18 | 92 |
I have deliberately refrained from creating many columns so that it is not confusing. An important column is ‘primary_key’, which is the unique key with which a customer can be identified.
The data is still in the dataframe, i.e. in the memory of the Spark Cluster. I now write this to the customer table. To make it easier to compare certain data later, I will generate an additional 5 data records and write them to the table. However, this only happens during the first run; this should not happen during the subsequent runs of the notebook. I use the variable of the iteration for this.
|
|
As you can see, I did not generate this data with Faker, but defined it myself. For the sake of simplicity, I have not used a GUID for the primary keys, but simple strings. I have also entered the planned operation for the name and surname columns. An update is to be performed on PK1, a delete on PK2, and so on.
I will simulate updates and deletes for later loads. In the 2nd run, an update is to be made, for this I have created the following code:
|
|
Then one run later comes a Delete:
|
|
For the next two runs, an update and a delete are built in. But more on this later.
The content of the source table now looks like this.
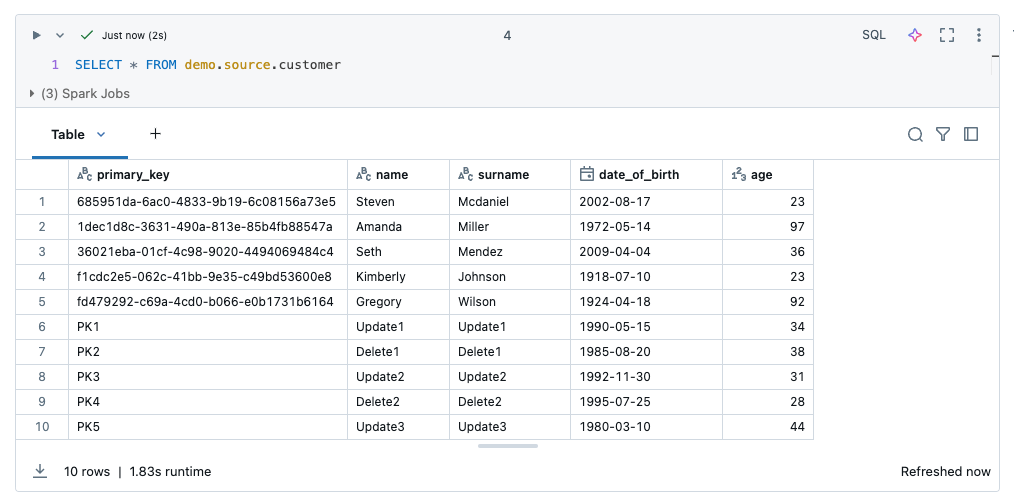
I now want to write the contents of this table to a volume as a snapshot. To do this, I read the data into a dataframe.
|
|
I will use Parquet as the file format for the snapshots. If I were to write this myself using the Spark method, it would generate a folder with several Parquet files, as Spark is optimised for parallelisation. With Pandas, I can write this as a single file, so I convert the PySpark dataframe into a Pandas dataframe. In addition, I create a partitioning in the target directory according to year, month and day, just as it would be done in practice. The current timestamp is entered as a string in the file name of the file so that the file name looks like this: customer_snapshot_20250301000000.parquet. This allows you to recognise later when a snapshot was created.
|
|
The result in the volume then looks like this:
Loading data with Delta Live Tables
Raw data in a volume can be stored relatively easily in a streaming table using Delta Live Tables. At the beginning I will show you how not to do it, i.e. simply save all data from the source in a Bronze Table. I call the table ‘customer_append’ because it is append only. This way, the amount of data explodes over time and the processing of the pipeline becomes slower with each execution.
I create a new notebook for the Delta Live Table Pipeline. I create a new streaming table and read in the Parquet files as a stream using Databricks Autoloader. The schema should adapt to the source data, so I set the ‘mergeSchema’ option to true.
|
|
When I start the DLT for the first time, I get the following result:
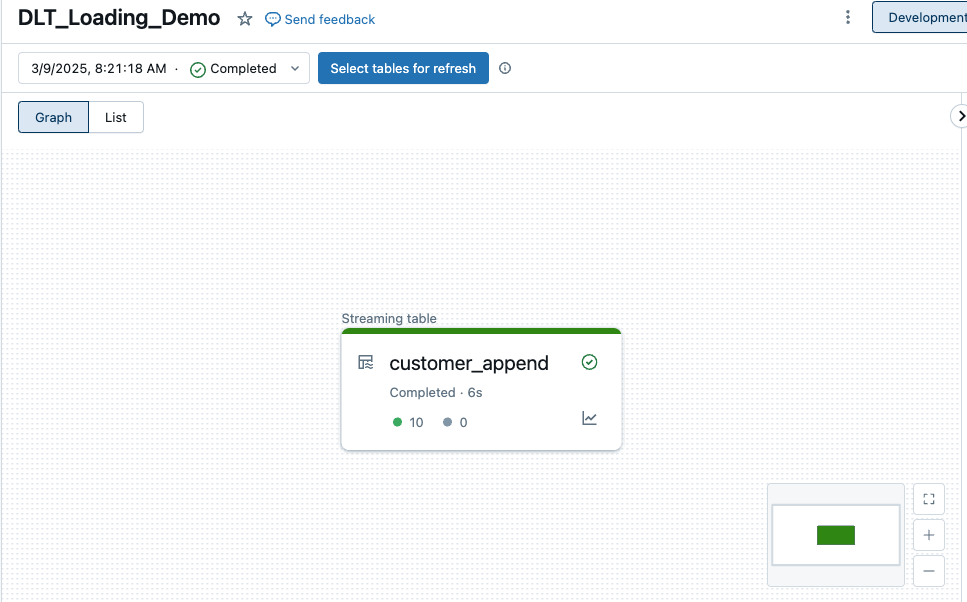
It has loaded all 10 rows from the Parquet file. The content of the Bronze table now looks like this:
| primary_key | name | surname | date_of_birth | age | Year | Month | Day | _rescued_data |
|---|---|---|---|---|---|---|---|---|
| 685951da-6ac0-4833-9b19-6c08156a73e5 | Steven | Mcdaniel | 2002-08-17 | 23 | 2025 | 3 | 9 | null |
| 1dec1d8c-3631-490a-813e-85b4fb88547a | Amanda | Miller | 1972-05-14 | 97 | 2025 | 3 | 9 | null |
| 36021eba-01cf-4c98-9020-4494069484c4 | Seth | Mendez | 2009-04-04 | 36 | 2025 | 3 | 9 | null |
| f1cdc2e5-062c-41bb-9e35-c49bd53600e8 | Kimberly | Johnson | 1918-07-10 | 23 | 2025 | 3 | 9 | null |
| fd479292-c69a-4cd0-b066-e0b1731b6164 | Gregory | Wilson | 1924-04-18 | 92 | 2025 | 3 | 9 | null |
| PK1 | Update1 | Update1 | 1990-05-15 | 34 | 2025 | 3 | 9 | null |
| PK2 | Delete1 | Delete1 | 1985-08-20 | 38 | 2025 | 3 | 9 | null |
| PK3 | Update2 | Update2 | 1992-11-30 | 31 | 2025 | 3 | 9 | null |
| PK4 | Delete2 | Delete2 | 1995-07-25 | 28 | 2025 | 3 | 9 | null |
| PK5 | Update3 | Update3 | 1980-03-10 | 44 | 2025 | 3 | 9 | null |
I see 4 additional columns. The columns Year, Month and Day have been automatically taken over by Spark from the partitioning in the source directory. When Auto Loader infers the schema, a rescued data column is automatically added to your schema as _rescued_data. The rescued data column ensures that columns that don’t match with the schema are rescued instead of being dropped.
What happens now if I load in a 2nd snapshot? For this reason, I will run the notebook with the test data generation again and start the Deltas Live Table Pipeline immediately afterwards. To automate this a little, I will put the two steps into one job.
The append table now looks like this:
| primary_key | name | surname | date_of_birth | age | Year | Month | Day | _rescued_data |
|---|---|---|---|---|---|---|---|---|
| 7e7ff14e-b060-45f3-96ca-d7318be16f77 | Andrea | Robinson | 2005-12-29 | 32 | 2025 | 3 | 9 | null |
| 2c5405f2-1a42-4eec-ad6b-b997dc94952e | Marvin | Roberts | 1991-02-12 | 47 | 2025 | 3 | 9 | null |
| bc092322-8b80-4f00-9050-3bd5bc4a5745 | Russell | Davis | 2005-02-11 | 24 | 2025 | 3 | 9 | null |
| 685951da-6ac0-4833-9b19-6c08156a73e5 | Steven | Mcdaniel | 2002-08-17 | 23 | 2025 | 3 | 9 | null |
| 1dec1d8c-3631-490a-813e-85b4fb88547a | Amanda | Miller | 1972-05-14 | 97 | 2025 | 3 | 9 | null |
| 713e5490-7d36-48ee-b3ef-8b0e4ed86244 | Jason | Proctor | 1909-05-15 | 46 | 2025 | 3 | 9 | null |
| ca02e59f-7800-4bf5-abee-9655ecb764c2 | Susan | Allen | 1925-09-06 | 38 | 2025 | 3 | 9 | null |
| 36021eba-01cf-4c98-9020-4494069484c4 | Seth | Mendez | 2009-04-04 | 36 | 2025 | 3 | 9 | null |
| f1cdc2e5-062c-41bb-9e35-c49bd53600e8 | Kimberly | Johnson | 1918-07-10 | 23 | 2025 | 3 | 9 | null |
| fd479292-c69a-4cd0-b066-e0b1731b6164 | Gregory | Wilson | 1924-04-18 | 92 | 2025 | 3 | 9 | null |
| PK2 | Delete1 | Delete1 | 1985-08-20 | 38 | 2025 | 3 | 9 | null |
| PK3 | Update2 | Update2 | 1992-11-30 | 31 | 2025 | 3 | 9 | null |
| PK4 | Delete2 | Delete2 | 1995-07-25 | 28 | 2025 | 3 | 9 | null |
| PK5 | Update3 | Update3 | 1980-03-10 | 44 | 2025 | 3 | 9 | null |
| PK1 | UPDATED | UPDATED | 1990-05-15 | 34 | 2025 | 3 | 9 | null |
| 685951da-6ac0-4833-9b19-6c08156a73e5 | Steven | Mcdaniel | 2002-08-17 | 23 | 2025 | 3 | 9 | null |
| 1dec1d8c-3631-490a-813e-85b4fb88547a | Amanda | Miller | 1972-05-14 | 97 | 2025 | 3 | 9 | null |
| 36021eba-01cf-4c98-9020-4494069484c4 | Seth | Mendez | 2009-04-04 | 36 | 2025 | 3 | 9 | null |
| f1cdc2e5-062c-41bb-9e35-c49bd53600e8 | Kimberly | Johnson | 1918-07-10 | 23 | 2025 | 3 | 9 | null |
| fd479292-c69a-4cd0-b066-e0b1731b6164 | Gregory | Wilson | 1924-04-18 | 92 | 2025 | 3 | 9 | null |
| PK1 | Update1 | Update1 | 1990-05-15 | 34 | 2025 | 3 | 9 | null |
| PK2 | Delete1 | Delete1 | 1985-08-20 | 38 | 2025 | 3 | 9 | null |
| PK3 | Update2 | Update2 | 1992-11-30 | 31 | 2025 | 3 | 9 | null |
| PK4 | Delete2 | Delete2 | 1995-07-25 | 28 | 2025 | 3 | 9 | null |
| PK5 | Update3 | Update3 | 1980-03-10 | 44 | 2025 | 3 | 9 | null |
As is easy to see, we have a multiplication of the amount of data. It is also not clear when which record was loaded into the table. It is also not clear that the record with the primary key ‘PK1’ has changed. I set this in the first notebook so that the name and surname are changed.
As this is a Bronze table, I do not change any columns. But what I do in Bronze is to enrich the data. For example, I want to know which raw file a data record came from so that I can trace it later. For this reason, I add the system metadata as an additional column. This can be done relatively easily by adapting the function for the streaming table. After the load, I make a select where I use * to select all columns and also the _metadata column:
|
|
After this change, I have an additional column _metadata, which provides me with the following information:
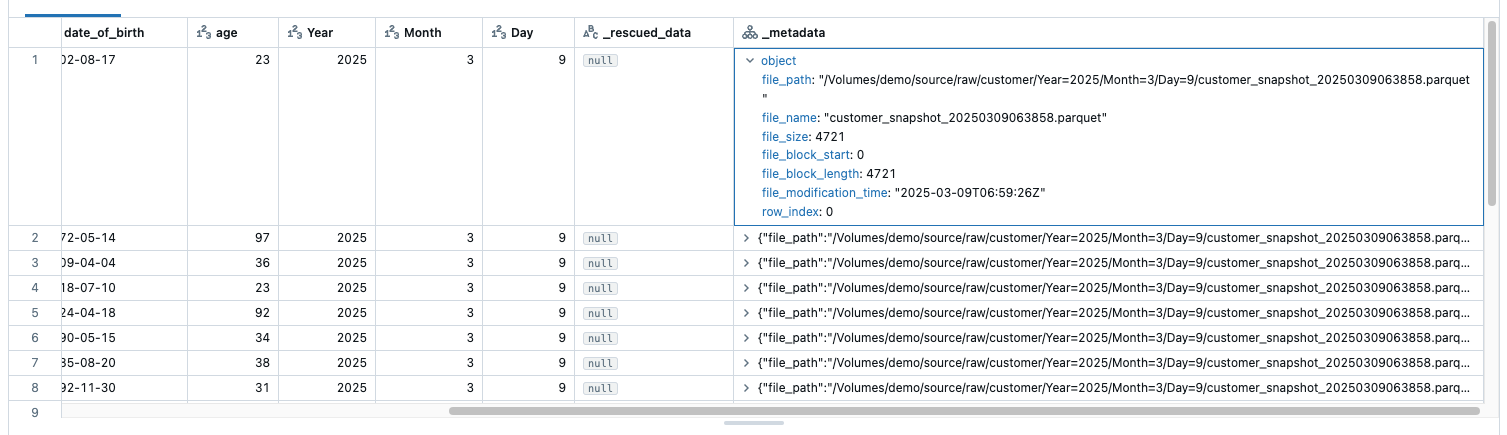
This metadata is file-specific metadata such as path, name, modification time. this is already very helpful. However, I would still like to know when the snapshot was created.
The timestamp of file_modification_time does not necessarily have to match the time when the snapshot was created. If the snapshot was created by another system and the files were subsequently loaded into the data lake, for example using Azure Data Factory, we already have a discrepancy. What happens if the snapshots are created, but for some reason the files cannot be copied to the data lake? If the copy pipeline for the delivery is then patched, the missing snapshots must be reloaded at the same time. If several snapshots are copied to the datalake at the same time, do they all have the same file_modification_time timestamp? Or only small differences? Even worse, the files may not be loaded onto the datalake in the correct order, depending on how the copy pipeline is set up. For this reason, I need the timestamp of the snapshot and cannot rely on the file modification timestamp.
I have saved the snapshot timestamp as a string in the file name. I will add this as an additional column to the dataframe.
|
|
Using regex, I extract only the part of the name that contains the timestamp and convert it to a timestamp type in a second step.
|
|
In addition, I would like to have a timestamp that tells me the time at which the DLT pipeline was executed. This can be realised using the function current_timestamp().
|
|
I needed the filename_timestamp_str and file_name columns for the intermediate steps. I no longer need them, as I can find this information in the metadata, so I delete them from the dataframe.
|
|
The complete code now looks like this:
|
|
I do a full refresh on the DLT and load the data in again. Then I have the following additional columns, which give me the corresponding insights:
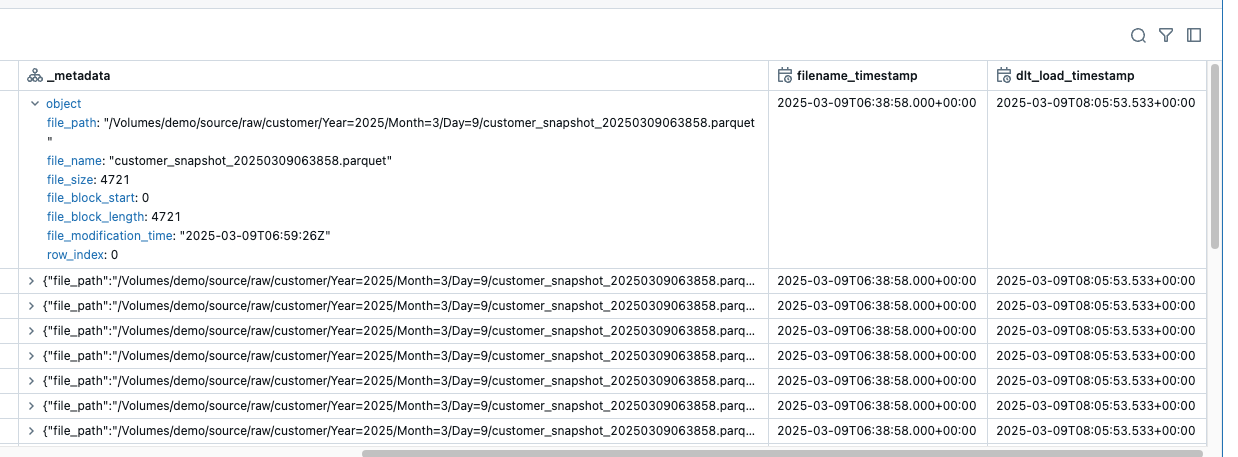
The dlt_load_timestamp column now has the same value for all rows, as I have performed a full refresh. However, if the pipeline is executed after each delivery of the snapshots, then it is correct.
I now run the job 3 times in a row so that the data is generated and loaded immediately via DLT. But more about the timestamps and why they are important for the final solution later.
I have combined these two steps into one job so that I don’t have to manually run the notebook first and then start the DLT.
In total, I have loaded data from 5 snapshots.
And the bronze table now has a correspondingly large number of duplicates.
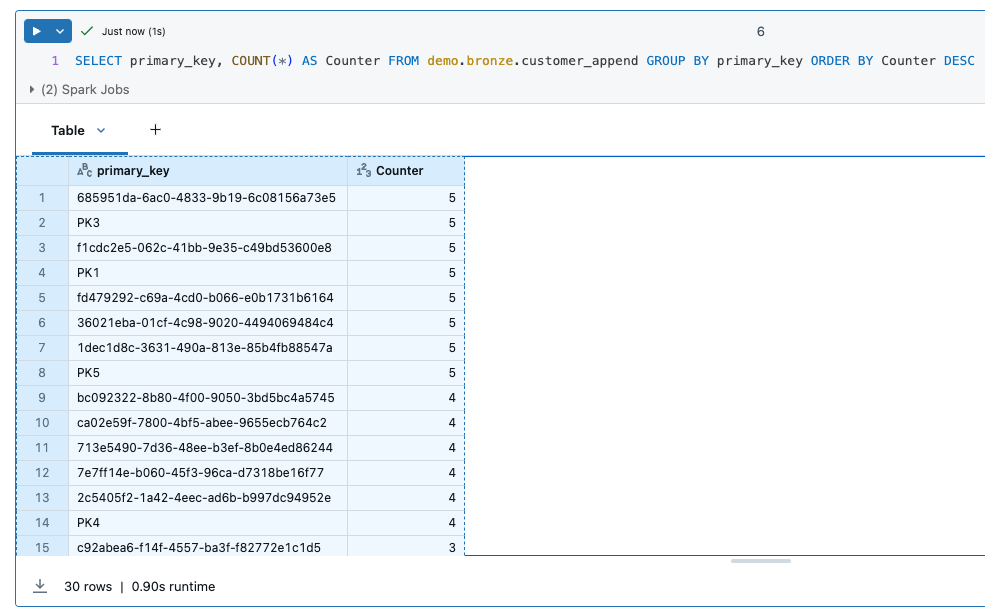
The question now is whether it makes sense to load all snapshots 1:1 into a bronze table. You generate a lot of data and still have to create a mechanism to filter out the updates and deletes from the huge data set. On the other hand, you can argue that if the data is in the bronze table, then the raw files can be archived and deleted.
From Append-Only to Latest-Records-Only
I can remember situations with customers where there were heated discussions about how to implement historisation. Various options were presented that were either costly, required a lot of computer resources and so on. Until it was discovered that historisation was not a business requirement at all. They would simply be happy if they could analyse the latest status of the data. So no over-engineering if the requirements are very simple.
This now means that we want to start the pipeline every day and overwrite the content of the bronze table with the last snapshot. This could actually be done relatively easily with 2 lines of SQL like this:
|
|
What remains is to recognise the path dynamically so that I can recognise the last Parquet file. I would also have problems with schema changes, as I would have to delete the table and recreate it. From my point of view, this is not a solution that I would like to pursue further.
From Latest-Records-Only to Change Tracking (CDC SCD1)
So that I don’t have to load every single record into the Bronze table, I have used merge functions in SQL in the past. Merge compares two data sets, inserts new records or updates records that have changed. However, some of these merge statements were quite complex, especially if you wanted to implement Slowly Changing Dimensions (SCD2). More information on Slowly Changing Dimensions can be found here: https://en.wikipedia.org/wiki/Slowly_changing_dimension
In Delta Live Table there is a simpler option than Merge, namely the functions of the APPLY CHANGES APIs. These functions can be used to realise Change Data Capture, more information can be found here: https://docs.databricks.com/aws/en/dlt/cdc
I would also like to use the Databricks autoloader with the CDC functionality. For this purpose, I create a view instead of a streaming table on the raw files and give it the same loading functionality as the streaming table. This means that the data is loaded using the autoloader when the view is called, but is not persisted. This means that the autoloader checkpoints are used.
The definition of the view looks like this:
|
|
If I now start the DLT pipeline again, I see the new view.
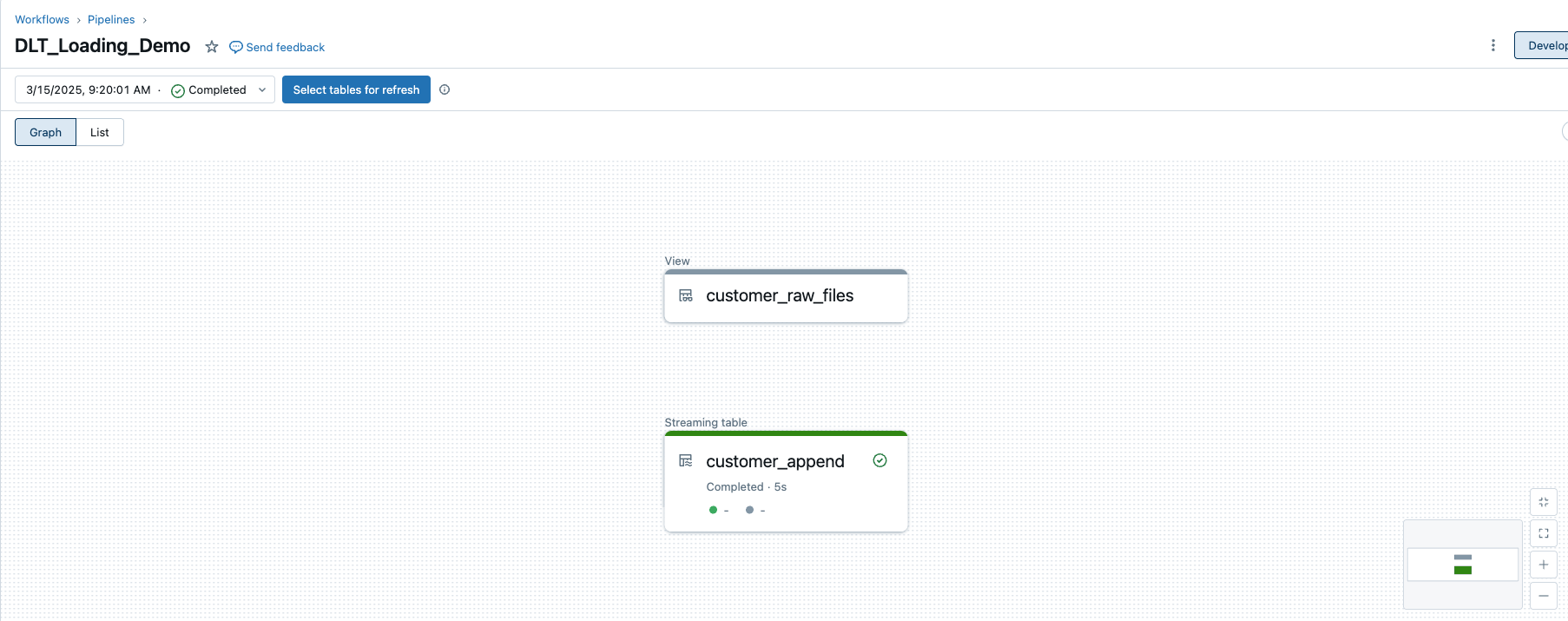
However, the view is not persisted, i.e. it is only visible within the DLT pipeline and cannot be queried externally, for example in the Unity Catalogue. It does not appear in the Bronze Catalogue.
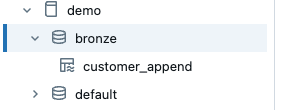
But we can use the view as a source for the CDC function. The definition for the new streaming table is very simple.
|
|
What we need here is the key with which the records can be compared, analogous to a merge statement. This can be a single column, such as the ‘primary_key’ column in my example. However, it can also be a list of columns if it is a composite key, i.e. a key that is made up of several columns.
The function must now have the information on how the respective records can be differentiated. In order for the data to be compared, the primary keys must be unique, as is the case with the merge statement. This differentiation is realised with a sequence. As I am loading data from different snapshots in my example, the filename_timestamp is a good choice. This allows the function to differentiate between different records with their primary key and the time.
Finally, we specify the SCD type, in our example it is type 1, which means that changes are overwritten and there is no historisation.
The extended DLT pipeline now looks like this.
So that we can now understand the whole thing, I delete all snapshot data and the customer table and start from the beginning. I run the process a total of 5 times in succession. I have to do the first run manually. This means using the notebook to generate the data and then triggering a full_refresh in the DLT pipeline so that we no longer have the old data in it.
The job can then be executed 4 times.
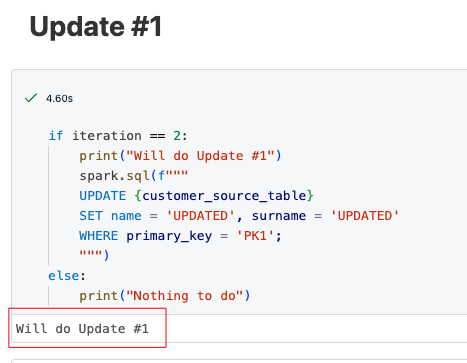
As I described at the beginning, update and delete operations are also carried out in the notebook runs in addition to the inserts. The following is an extract from the update run.
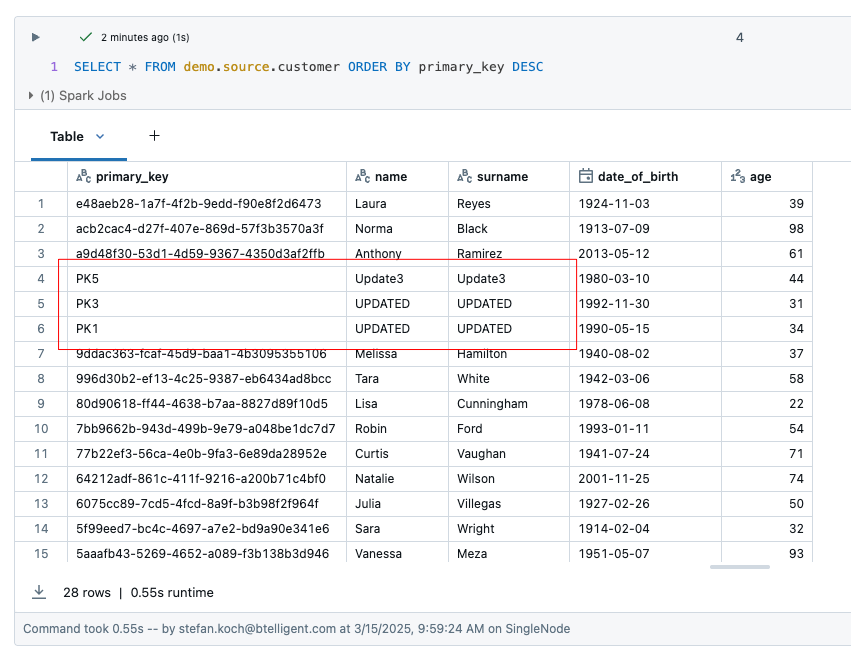
Now let’s take a look at the result. The source table customer has 28 rows. 2 rows were deleted, namely those with the primary key ‘PK2’ and ‘PK4’. The rows ‘PK1’ and ‘PK2’ were updated.
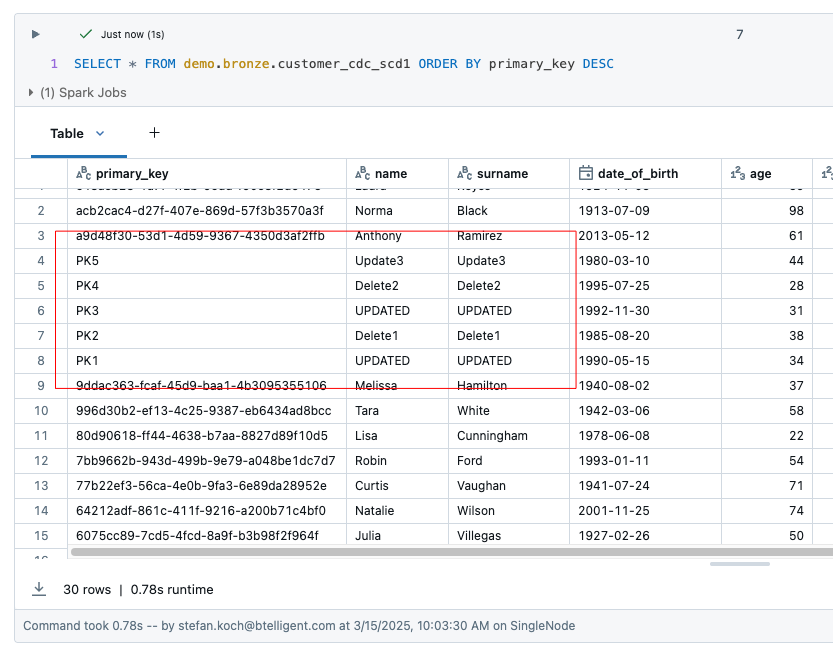
The table customer_cdc_scd1 has a total of 30 rows. You can see that the changes to PK1 and PK2 have been adopted, but the deletes have not been adopted. This means that PK2 and PK4 are still present in this table.
The deletes cannot be easily detected. According to the Databricks documentation, the source system would have to provide this information in order to recognise the deletes. This means that the dataset would have to contain an additional ‘Operation’ column in which the deletion process is flagged. The parameter apply_as_deletes would have to be defined in this way, as the following example shows.
|
|
From Change Tracking (CDC SCD1) to Change Tracking (CDC SCD2)
In addition to the streaming table with SCD1, I create one with SCD2. I change the parameter stored_as_scd_type to the value 2. The definition of the column now looks like this:
|
|
As you can see, there is another parameter that I define, namely the ability to exclude columns from the comparison. As apply_changes checks all columns to see if there have been any changes, I have to exclude the columns that contain the metadata. Otherwise it would recognise an update with every run, even though nothing has changed in the source data.
Before I start the pipeline, I clean up the test setup again by deleting all files in the volume and the customer table.
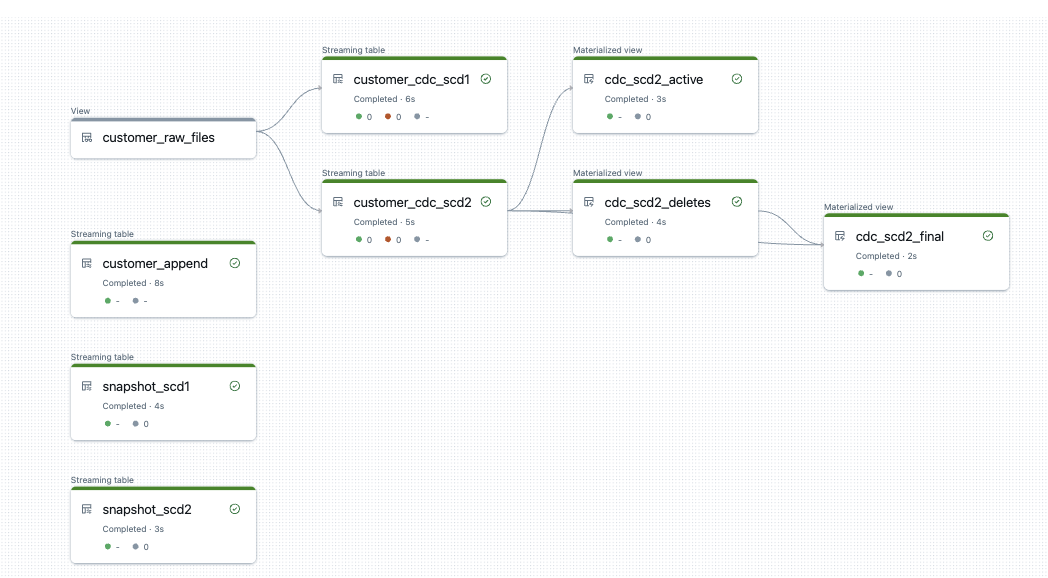
The generated DLT pipeline now looks like this. I use the same view customer_raw_files for both SCD1 and SCD2.
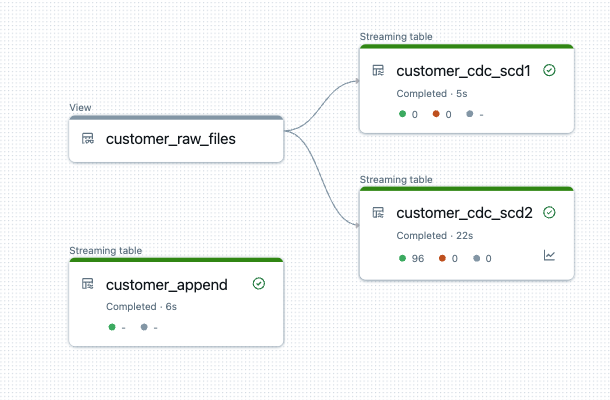
Now let’s take a look at the result of the table. After 5 runs, we have a total of 96 rows. As we are loading with SCD2, two additional columns START_AT and END_AT are added to the bronze table. These are used to define the validity of the rows. In other words, if a record has been deleted, it is not deleted from the Bronze Table, but the __END_AT date is set to indicate that it is no longer valid from the time of loading. During an update, the end time is also set and the new, changed value is added in a new row with a start date but without an end time. This means that all records that do not have an end time are valid values. So much for the theory…..
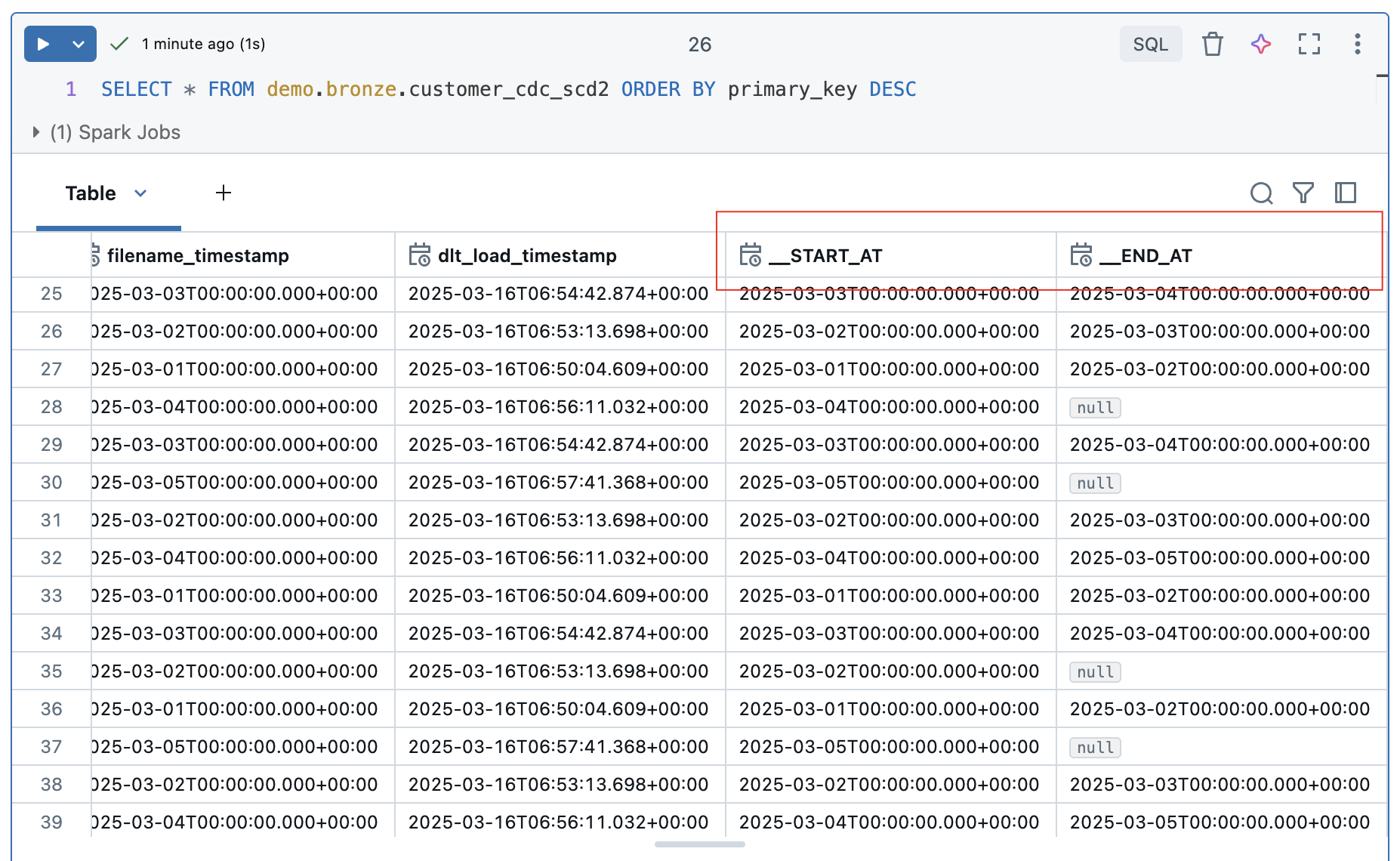
Let’s take a closer look at the rows that have been updated, i.e. the customers with the keys PK1 and PK3.
The updates were recorded correctly. Both values each have a valid entry without an end time at the start of the 5th iteration. The values in the 4 previous iterations were terminated with an end time.
The deleted values of customer PK2 and PK4 are different. PK2 was deleted in the 3rd iteration and PK4 in the 5th iteration. However, these values are still entered as valid in the table.

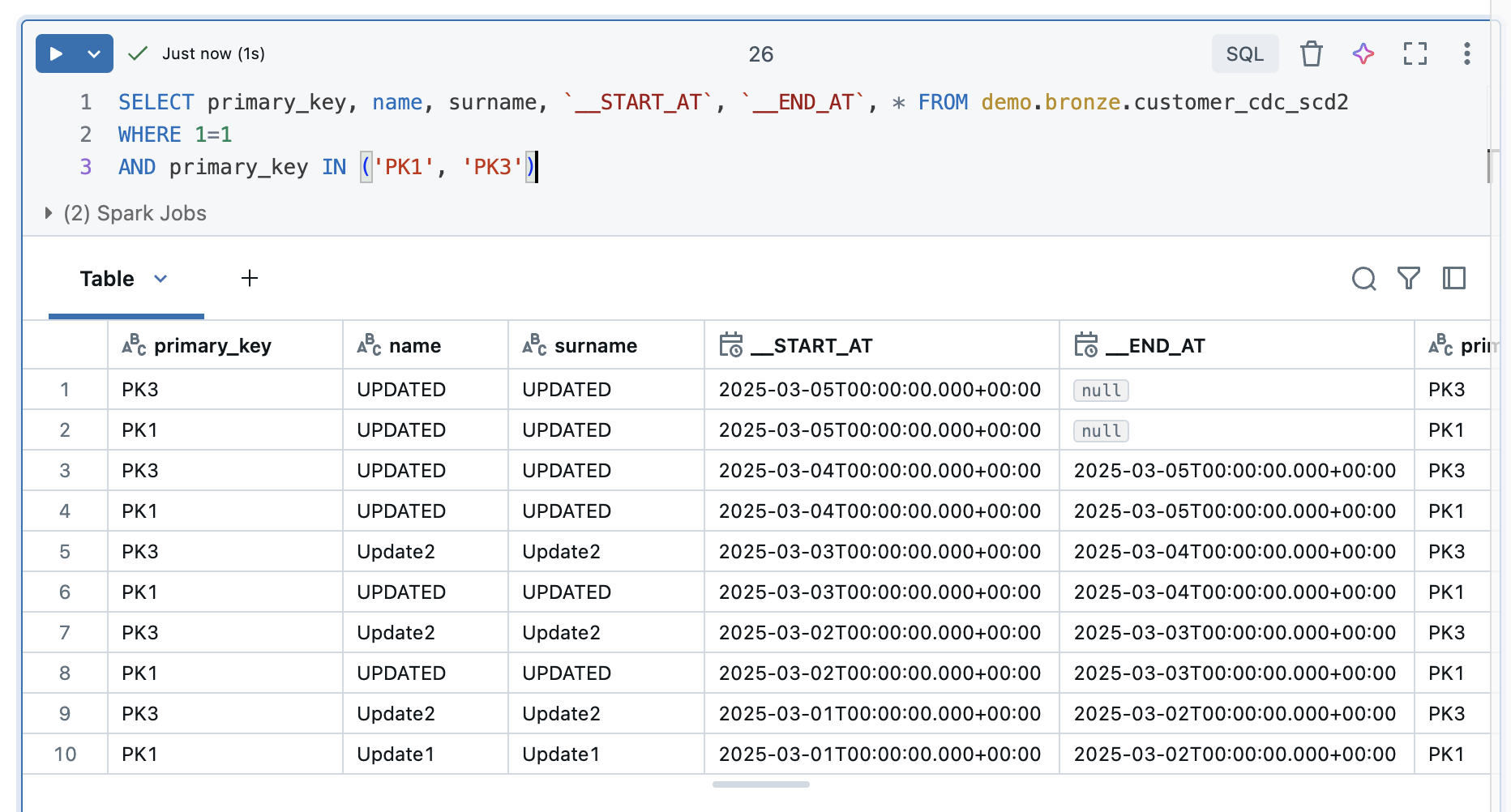
This is understandable, as the function requires an operation column to recognise these deletes. However, you can recognise a pattern for deleted values. The start time is reset for each iteration. This means that current values and those that have been changed always have the last start time. However, as the deleted records are no longer delivered, they remain in the table without an end time and without the start time being adjusted. If you filter according to these two criteria, the Deletes.
|
|
The result looks correspondingly good, PK2 and PK4 are now displayed.
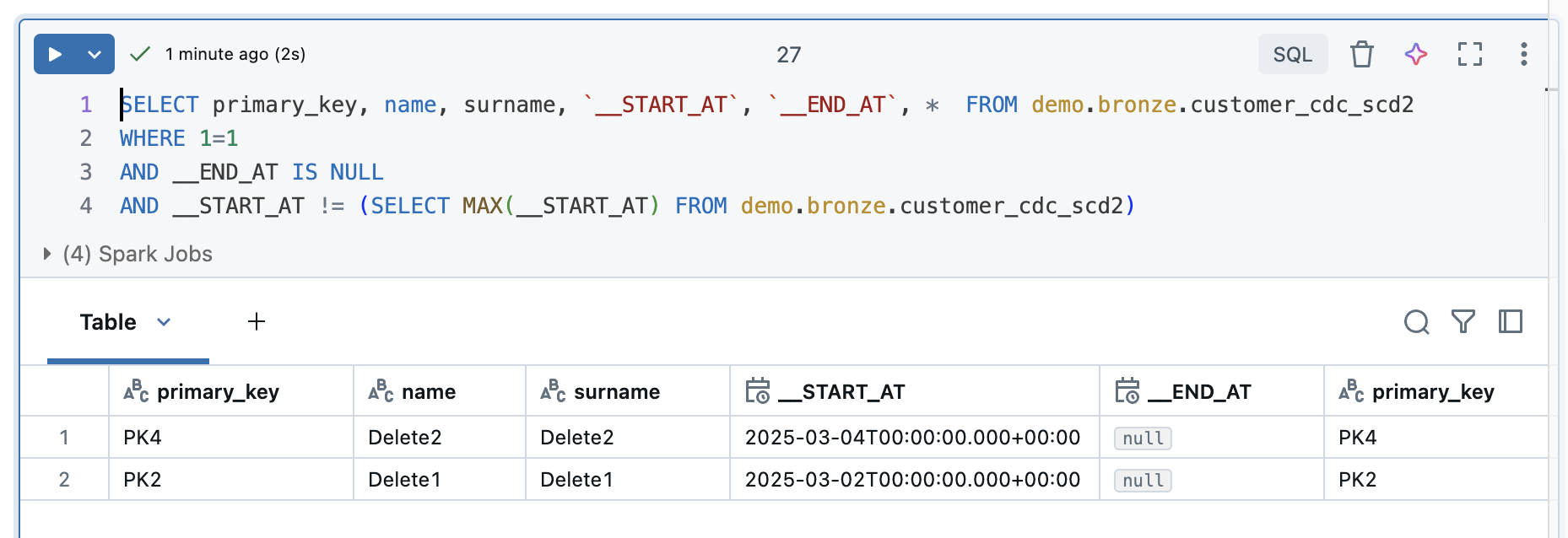
But what happens if I have to do a full refresh? To show this, I will do a full reflesh all to the Delta Live Tables and then take another look at the result.
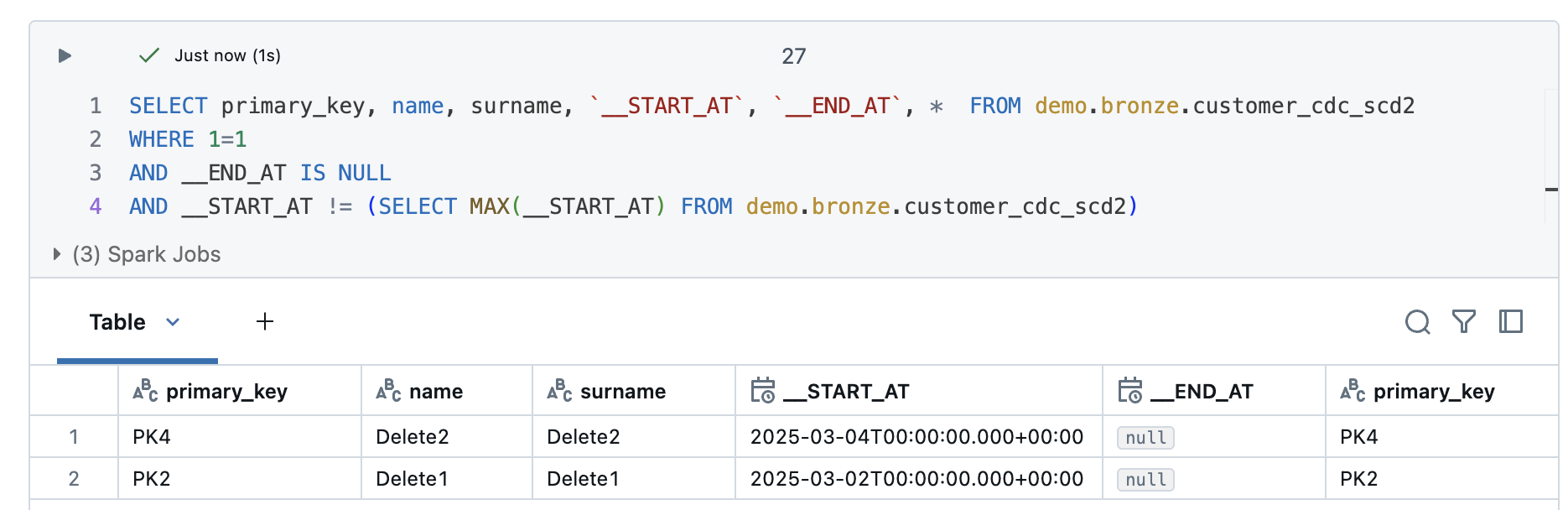
Even with a full reflesh, the deletes are still recognised correctly.
Theoretically, you could now adapt the DLT pipeline and add a second step in which the deleted records are detected with this query and then removed from the bronze table or at least flagged as deletes.
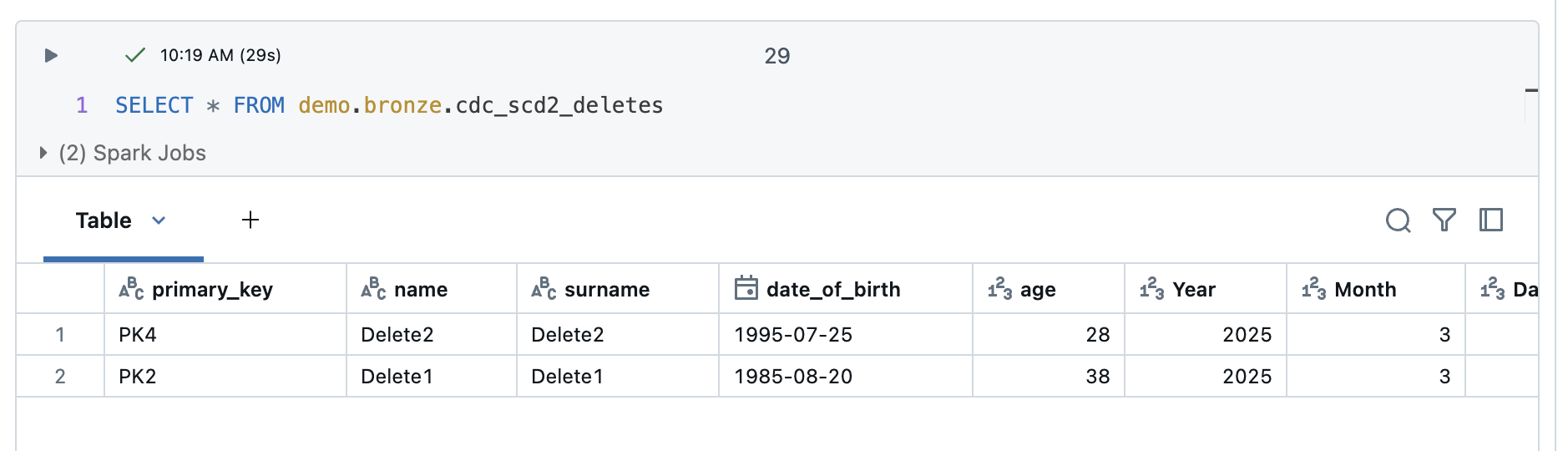
For this purpose, I create a materialised view that reads the data from the SCD2 table and only displays the deleted records. I take the logic from the SQL query.
|
|
At the same time, I create a view that only contains the active records without deletes.
|
|
And why not another view that shows the SCD2 table without deletes but with history. Here the definition is a bit longer, as I first have to find all records with an end date and then those that appear in the deletes.
|
|
The DLT pipeline now looks like this.
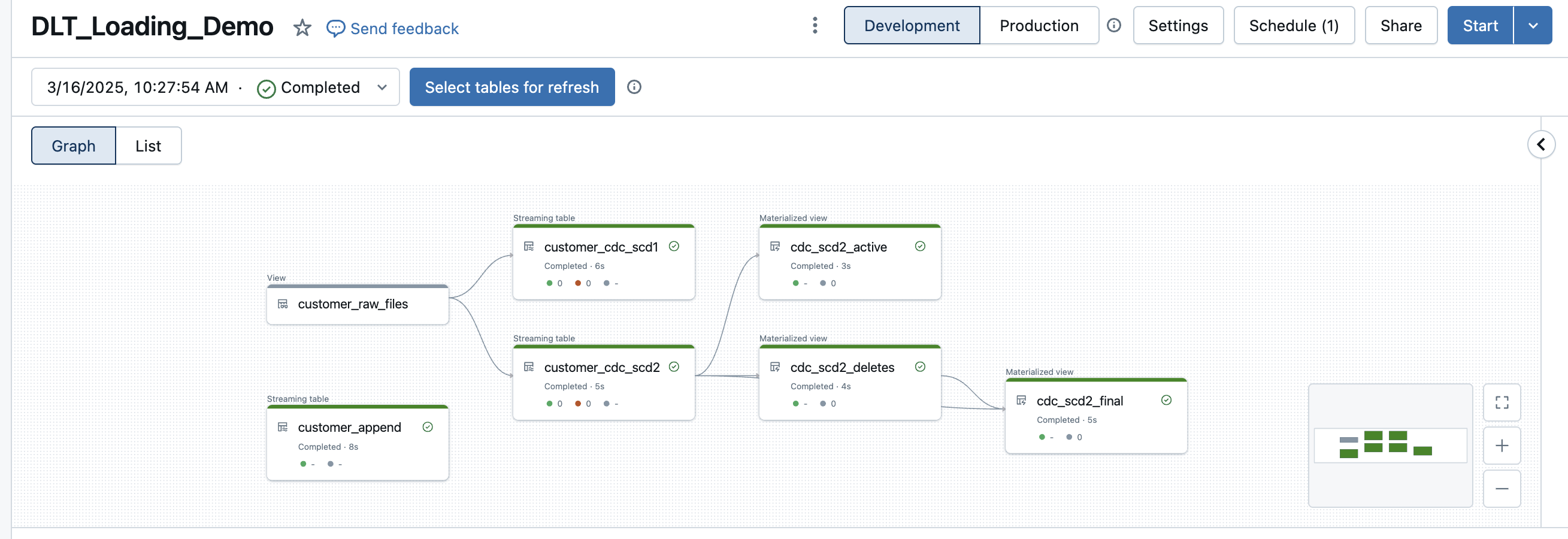
The view with the deletes correctly returns only the deleted records.
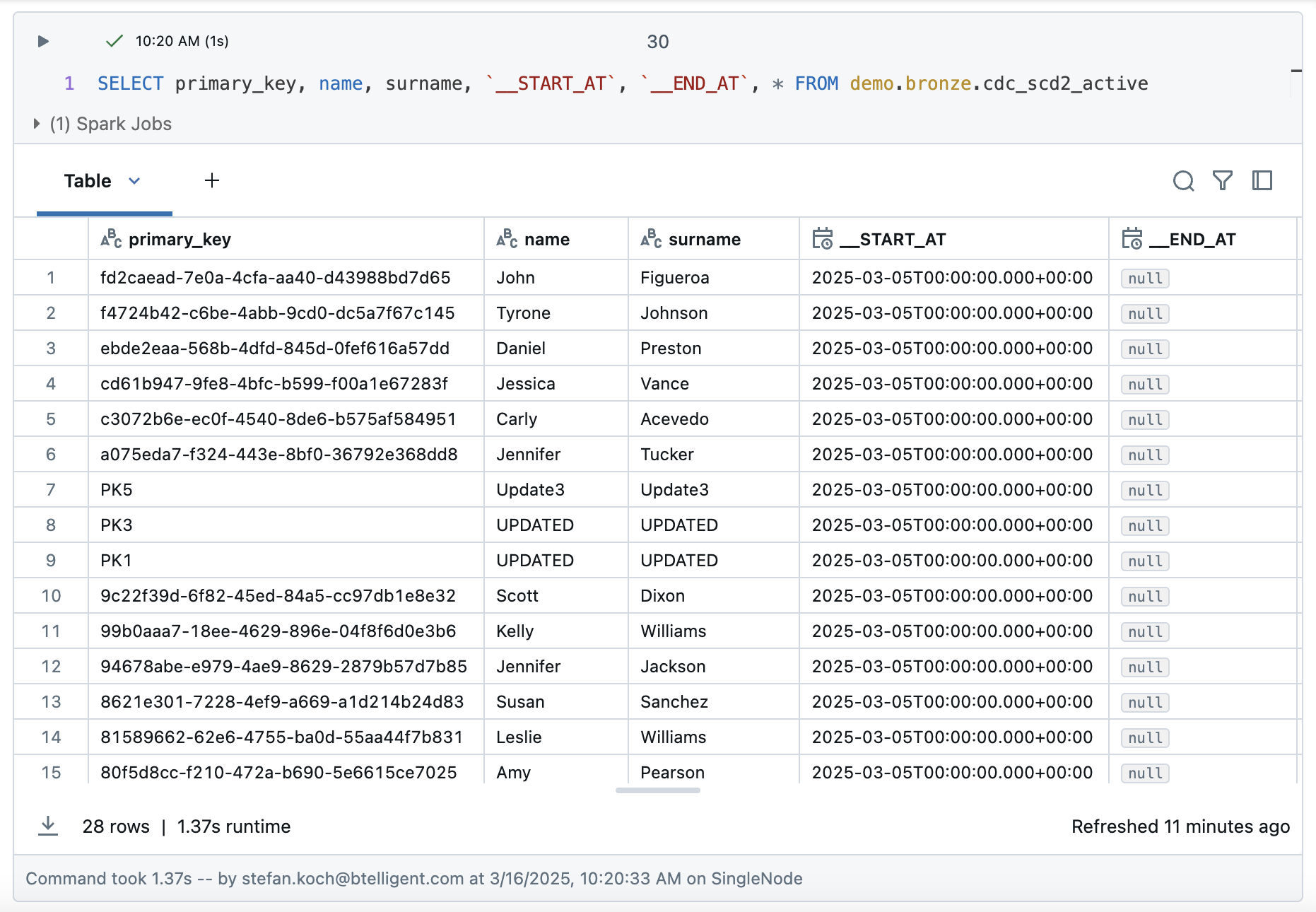
The view with the active records also looks good. I only get those that are actually active.
And lastly, the final view, which should show me both the history, but please filter out the corpses of the deleted ones.
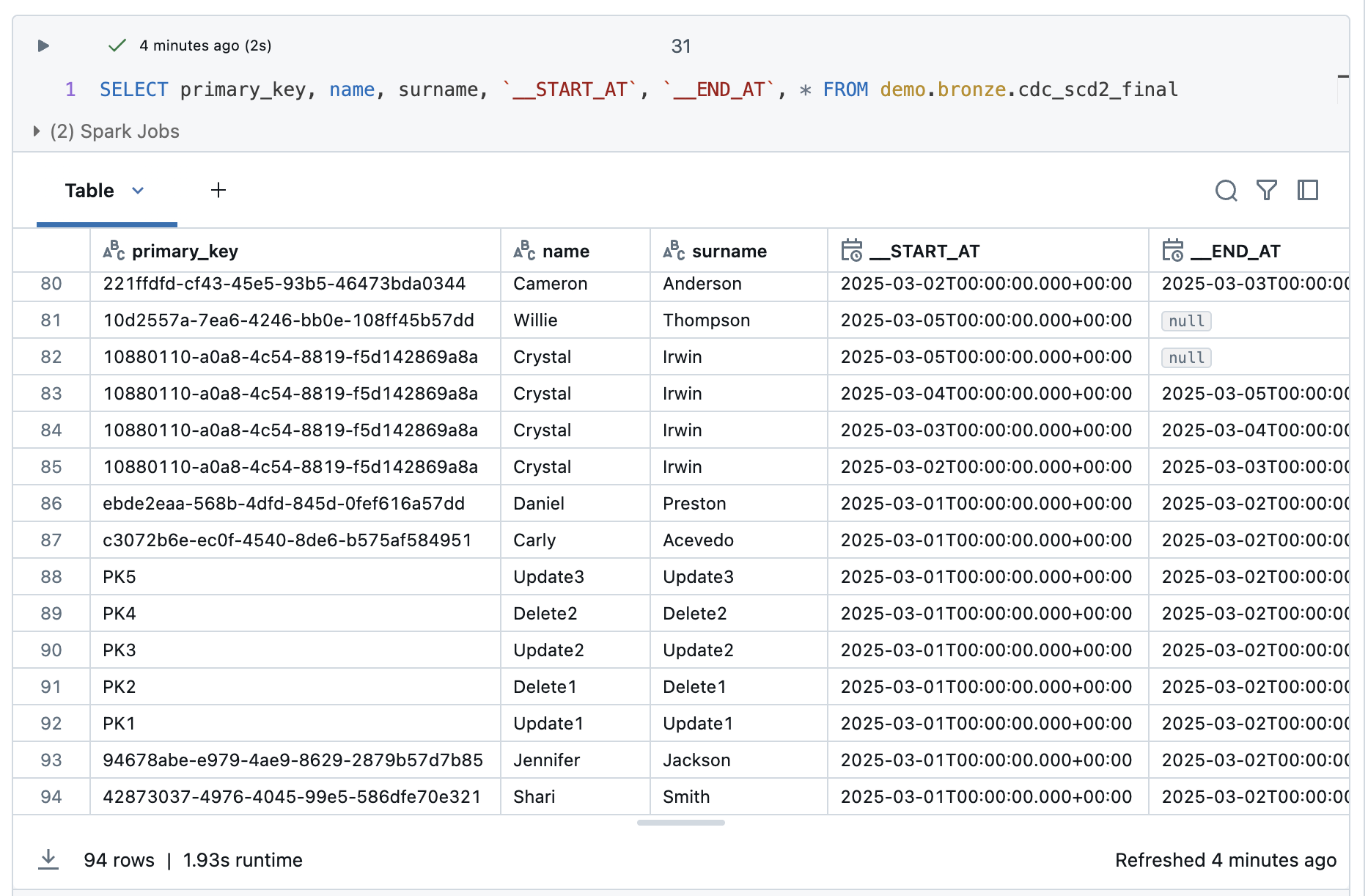
I have 94 rows, which is 2 rows less than in the SCD2 table. These are probably the deletes. I check this with a small query to look at the PK2 and PK4 rows.
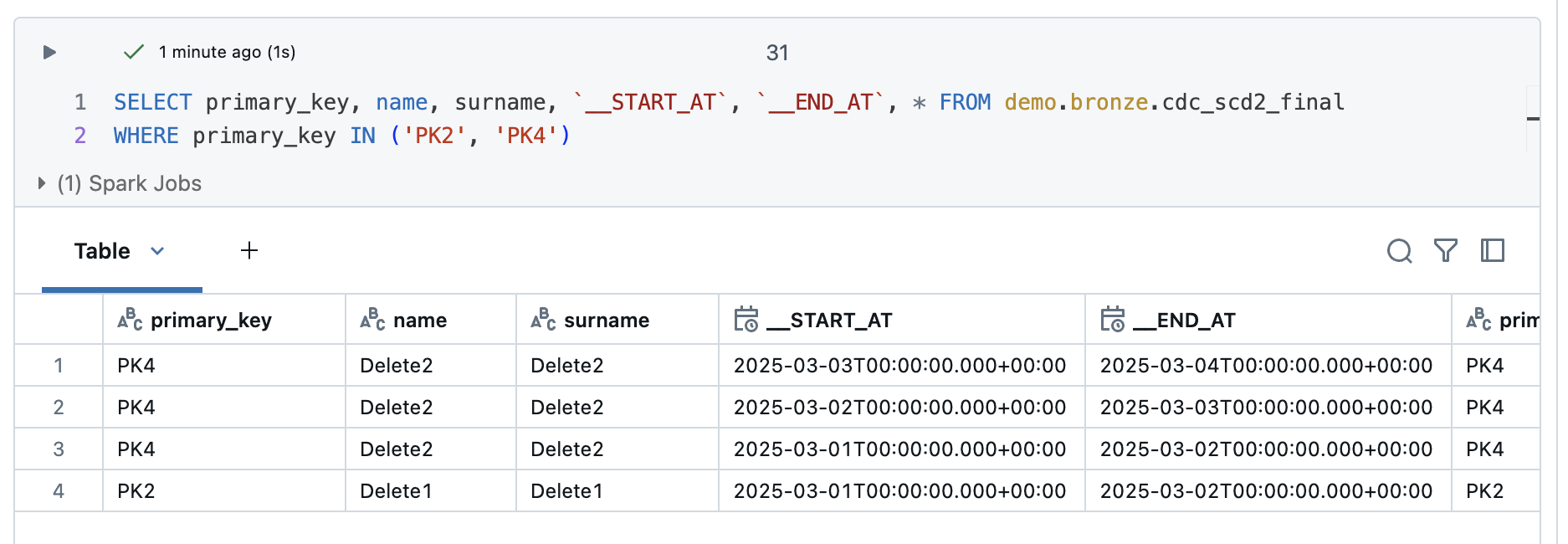
Looks good, because we now have the history, but no more corpses with entries without an end time.
But is there an easier solution? Yes, it is possible with the apply_changes_from_snapshot function.
From Change Tracking (CDC SCD2) to Change Tracking Snapshot SCD1
The apply_changes_from_snapshot function is designed precisely for processing snapshots with Delta Live Tables. Here is the documentation: https://docs.databricks.com/aws/en/dlt/python-ref#change-data-capture-from-database-snapshots-with-python-in-dlt
But, unfortunately, I cannot use the Databricks autoloader here. This means that I now have to implement a function that provides me with the exact path of the snapshot file and then another function that provides the next file. In the official documentation, this was realised with an increment if the snapshot file has a version number. I cannot do this as I simply have a snapshot by date. What I can do, however, is to increment the date. In my example setup, I get a new snapshot every day, so I increase the increment by one day.
Again, I start with the version of SCD1. The definition of the DLT looks like this.
|
|
Firstly, the exist() function is used to check whether a specific directory exists. To do this, dbutils.fs.ls() is used, which returns a list of the directory contents. If the directory does not exist, an exception is caught and False is returned.
To determine the next available snapshot, the date of the last snapshot is used. If no previous snapshot exists, a specified start date is used, otherwise the date of the last snapshot is incremented by one day. This date is then converted into a numerical version number in order to manage the snapshot history. this is hard-coded in my example. This would have to be solved dynamically in a productive pipeline. However, I will not do this in my example.
After the next possible snapshot date has been determined, the system checks whether the corresponding data exists. If so, it is read in as a DataFrame, whereby metadata is loaded in addition to the actual data. The additional metadata is handled in exactly the same way as the other tables.
The customised DLT pipeline now looks like this.
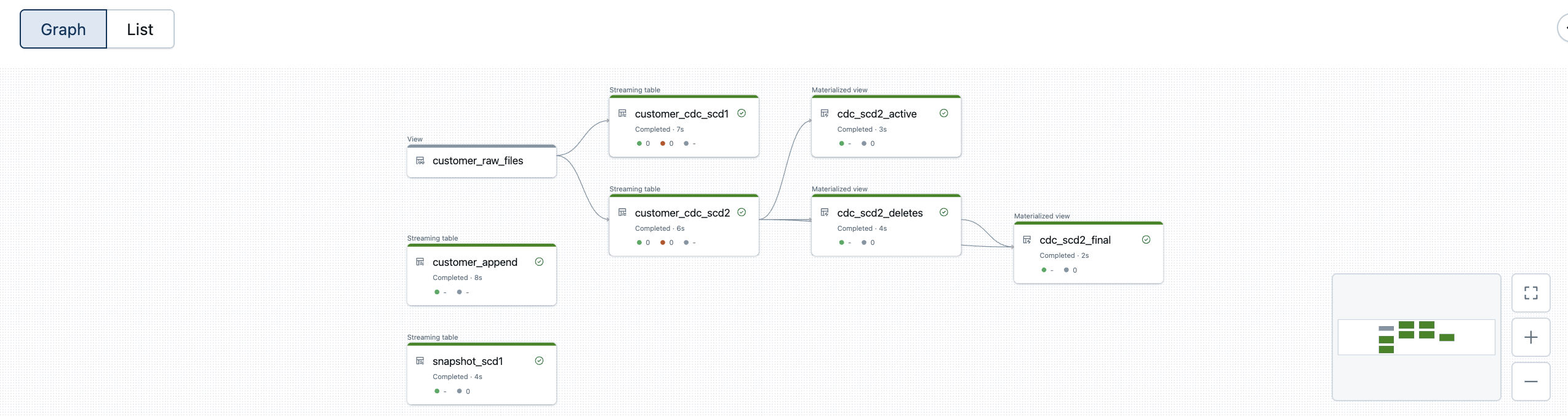
Instead of several steps, this new streaming table can process the data directly. Since we have SCD1, it is a current image of the source table and we do not find any information about the history.
We have exactly the same information as in the source table. Both the content and the number of rows are identical.
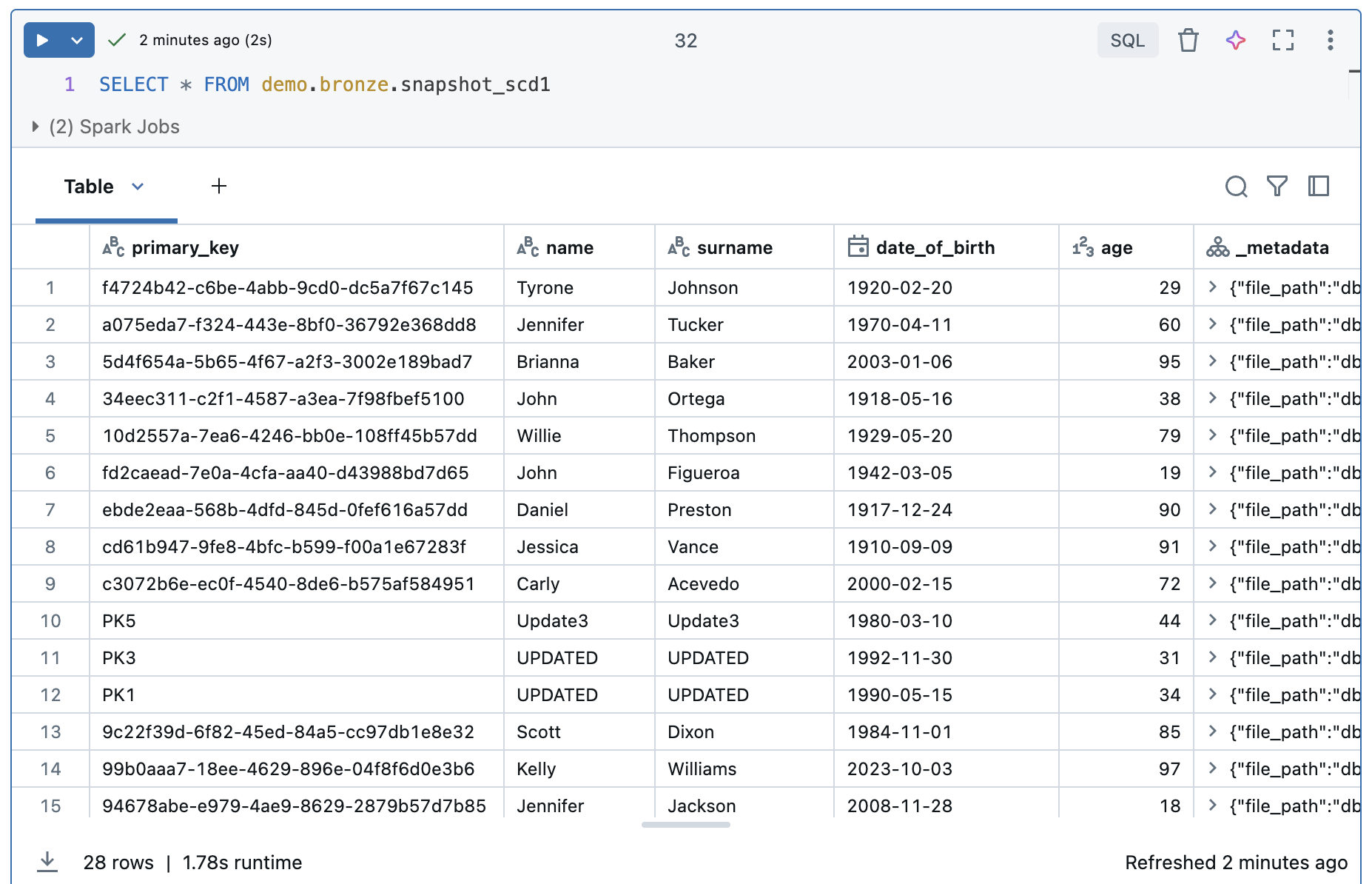
It looks like deletes are also recognised automatically.
Let’s take a look at the SCD2 case when we implement apply_changes_from_snapshot with SCD2.
From Change Tracking Snapshot SCD1 to Change Tracking Snapshot SCD2
The implementation with SCD2 is relatively simple. The logic is almost the same as for SCD1, but we still have to specify which columns we do not want to compare, namely all columns with additional meta information. The last lines are therefore different to SCD1:
|
|
The whole code then looks like this:
|
|
And the customised version of the DLT pipeline.
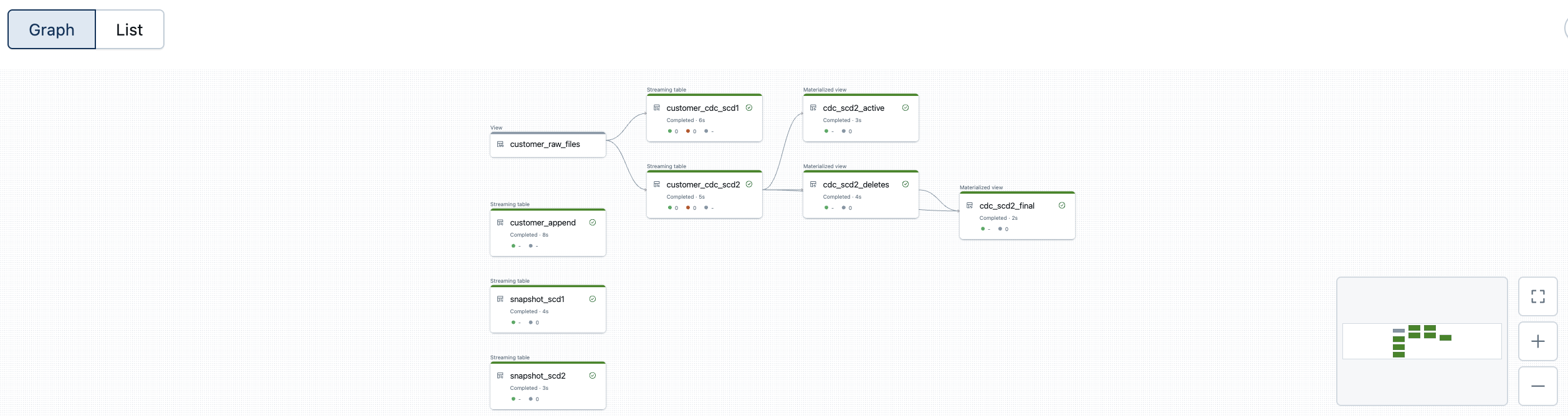
The data looks correspondingly good. The data is fully historicised thanks to the implementation of Slowly Changing Dimension Type 2, which also recognises deleted entries. The function automatically checks whether data records with a specific primary key exist in the target table but no longer appear in the source data record. Such entries are marked as deleted and recorded accordingly in the history.
Conclusion
With the APPLY CHANGES APIs, Delta Live Tables provide a powerful tool with which data from sources with full snapshots can be easily and efficiently integrated into the data platform. There are several approaches that can be followed.
The Append Only method is not recommended because the amount of data explodes here and the data cannot be processed further without further ado.
Latest Record only makes sense if, according to the requirements, no historisation is needed.
Apply Changes SCD1 makes no sense, as you lose the deletes and the historisation. You can go straight back to Latest Record.
The advantage of Apply Changes SCD2 is that you can use Databricks Autoloader. Ingestion is therefore relatively simple. However, additional views must then be installed in order to recognise the deletes.
Apply Changes From Snapshot SCD1: Here too, I doubt that the effort is worth it. You can recognise the deletes, but there is no historisation. You can go straight back to Latest Record.
Apply Changes From Snapshot SCD2: Here I have the complete historisation including delete detection. The ingestion is a bit more complex because you can’t use autoloaders, but the result is a single bronze table.
In conclusion, it can be said that the two methods Apply Changes SCD2 and Apply Changes From Snapshot SCD2 are the most suitable. Depending on how the ingestion is to be suspended, one or the other method is more suitable.
The code for these examples can be found in my public Github repository: https://github.com/stefanko-ch/Databricks_Dojo/tree/main/DLT_Snapshot_Loading
There you can recreate the whole setup 1:1.