In data engineering in the Azure Cloud, a common setup is to use Azure Data Factory to orchestrate data pipelines. If you wanted to orchestrate Databricks pipelines, you had a powerful tool at hand with Data Factory to schedule and orchestrate the Databricks pipelines. In this article, I will show you the other way around: how to start and monitor Data Factory pipelines from Databricks workflows.
Intro
With Databricks Workflows, Databricks offers a powerful ETL orchestration suite that can be used to orchestrate and trigger all data pipelines in Databricks. The functionalities of workflows have been continuously expanded in recent months.
If I now implement a data platform in Azure with Azure Databricks, I will have two different options as to where I want to implement my orchestration. Two years ago, that would have been a decision you didn’t even have to think about; that would have been the Data Factory because it simply offered all the functionalities. Nowadays, my decision is different. If my data platform is realized with Databricks and 95% of the pipelines are created with Databricks, then I also want to have the orchestration in Databricks. Of course, it would be nice if I could create 100% of the pipelines with Databricks, but there are still certain situations in which the Data Factory is more suitable, for example, if I need to copy large amounts of data or integrate data sources from on-prem networks. Databricks Lakeflow Connect is on the way, but not yet GA. I’ll have to be patient a little longer. As soon as Lakeflow Connect is ready for use, you have to go back over the books.
You could now go and create a few Data Factory pipelines and orchestrate them in Data Factory. All Databricks pipelines would then be orchestrated in workflows. However, this would be a sub-optimal setup. There may be dependencies between the pipelines. For example, I have to copy data from an on-prem system to the data lake with an ADF pipeline (ADF = Azure Data Factory) and then start a Databricks pipeline. How do I know that the data factory is ready? I can make a schedule that starts the ADF pipeline at 04:00 in the morning. I know from experience that the ADF job takes around 30 minutes, so I plan a little reserve and start the Databricks pipeline at 05:00. It’s bad because I lost 30 minutes. It’s also bad because if there are problems, the pipeline fails. For example, the ADF pipeline may take longer for some reason, i.e., it may not be ready at 05:00. This then leads to conflicts. You could then say that instead of scheduling the Databricks pipeline as well, you use a different trigger, e.g., a file trigger. The destination of the ADF pipeline, where the files are written to the Datalake, can be monitored with Databricks workflows; as soon as a file is written, the Databricks pipeline is started first. This allows me to start processing the files in Databricks straight away. However, it must be remembered that the files are only being written. So, I can’t start Databricks when the first file is being written. You have to use a trick to write a kind of control file after the copy job in ADF when everything runs successfully. This is then the trigger for Databricks to start its job. But that doesn’t sound good either. Another possibility would be to execute a task after the copy job in ADF, which then triggers Databricks. Somehow, however, the possibilities are limited. I can execute Databricks Notebooks, Databricks Jar, or Databricks Python code in ADF.
This means that I would have to write code in one of these three tasks to trigger the actual Databricks job. Another possibility that makes more sense would be to trigger the job in Databricks workflows from ADF via REST API. But what I don’t like about this setup is that I have two different orchestrators. What if something goes wrong? I have to look in Databricks Workflows to see what happened, as well as in ADF. The logic also has to be created, operated, and managed in both places.
So, my goal is to do the central orchestration exclusively with Databricks workflows. All scheduling and triggering take place in Databricks. The Data Factory is only used to execute simple pipelines and to use the Self Hosted Integration Runtime. The pipelines are written generically and started from Databricks with parameters. The aim is that the pipelines have to be created once and do not have to be adapted and deployed for each new data source. All logging should then also be fed back to Databricks.
Data Factory Pipeline
In my example, I have created a simple ADF pipeline.
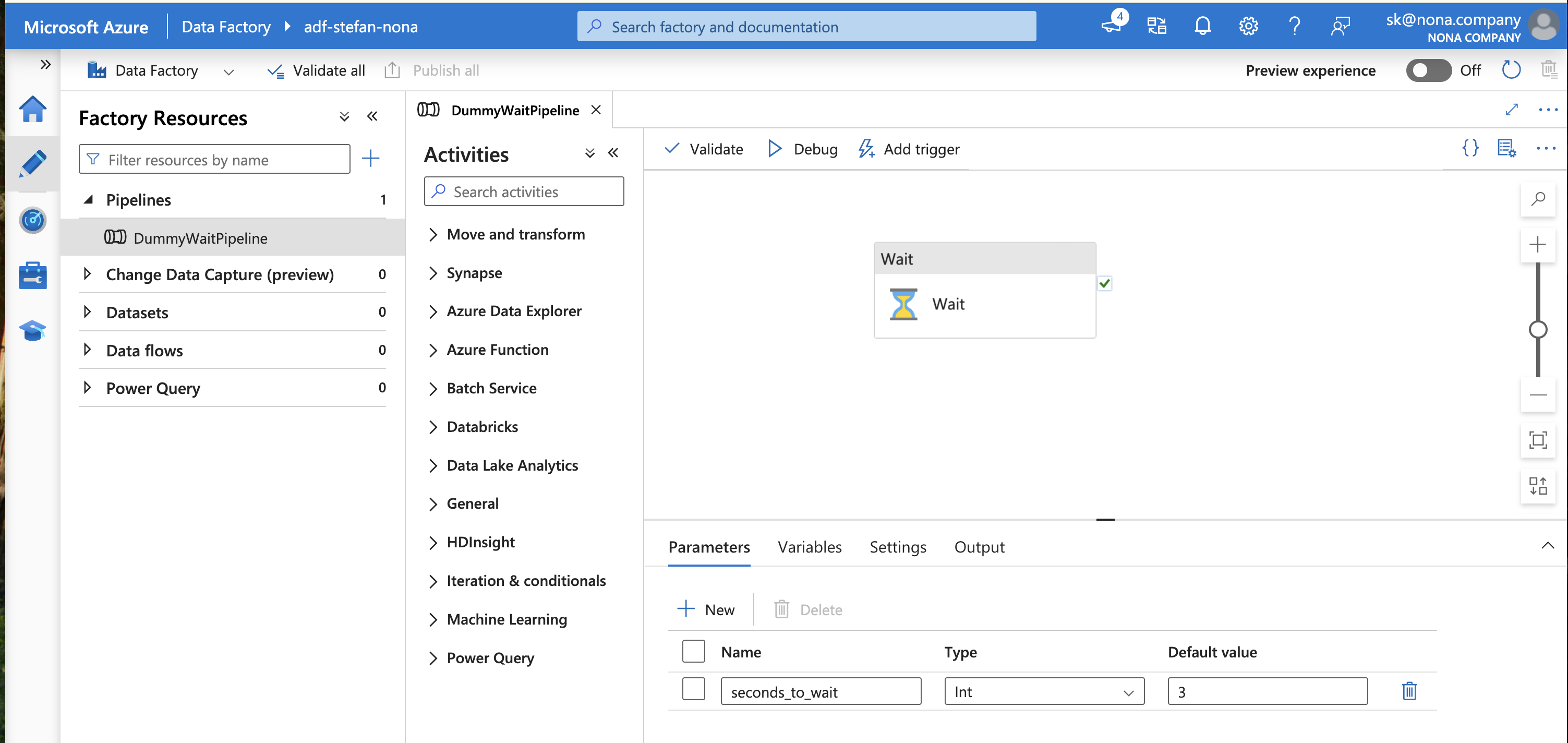
The pipeline has a single task that waits a defined number of seconds. I do not hard-code the number of seconds but pass it as a parameter. This parameter must, therefore be passed when the pipeline is run:
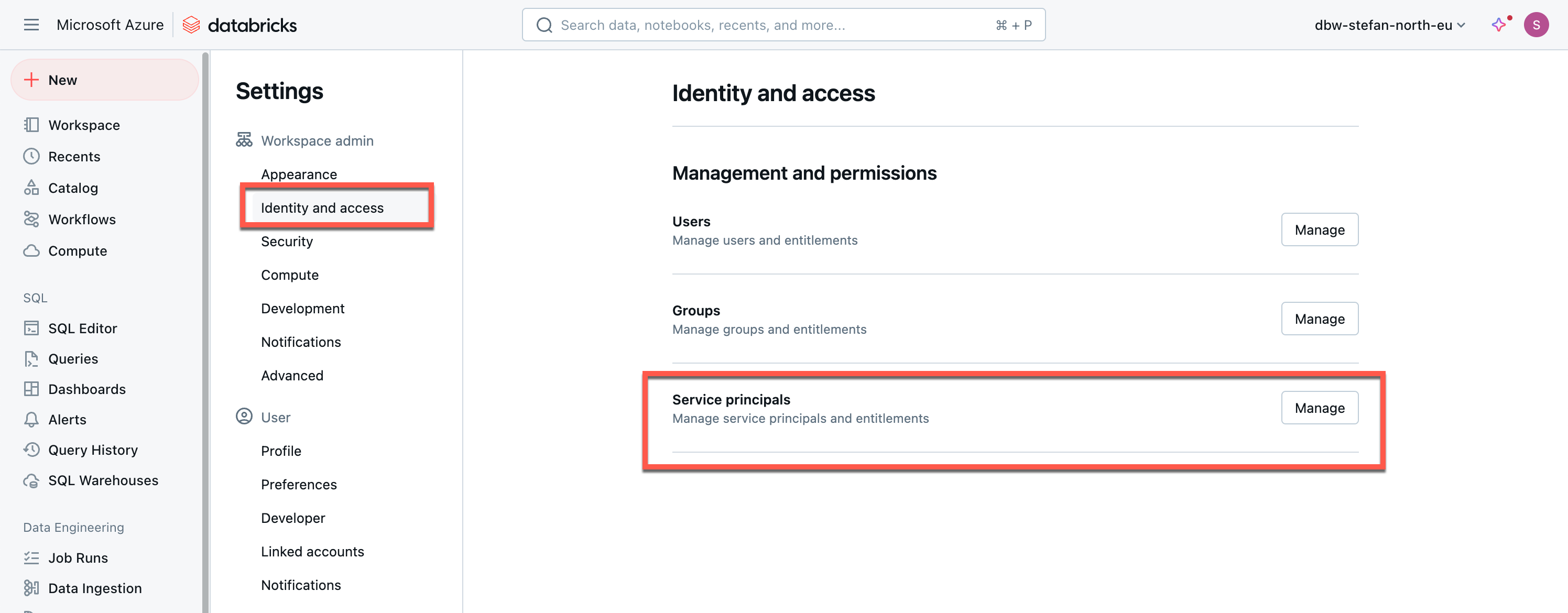
Creating an Entra Service Principal
If I now want to run this ADF pipeline in an automatic ETL process, I do not run it under my user but use a service principal. There are detailed instructions for Azure on how to create a service principal: https://learn.microsoft.com/en-us/power-apps/developer/data-platform/walkthrough-register-app-azure-active-directory
In the Azure Portal, you can search for app registrations and then create a new one. I choose a descriptive name so that you can roughly recognize the purpose for which this service principal was created.
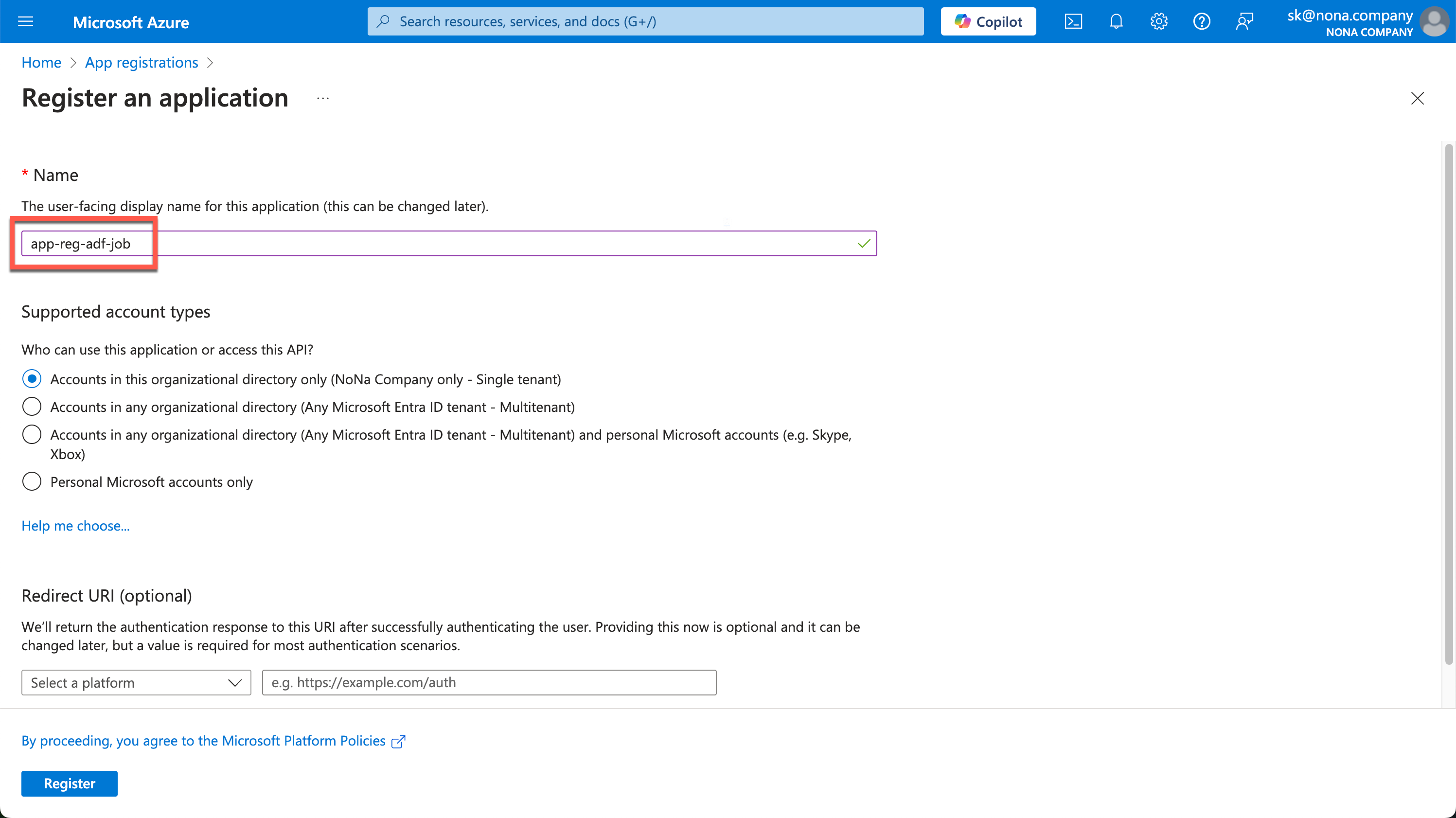
You can leave the Redirect URI empty.
After creating it, you will see the important information in the Overview. We need the Application (client) ID and the Directory (tenant) ID.
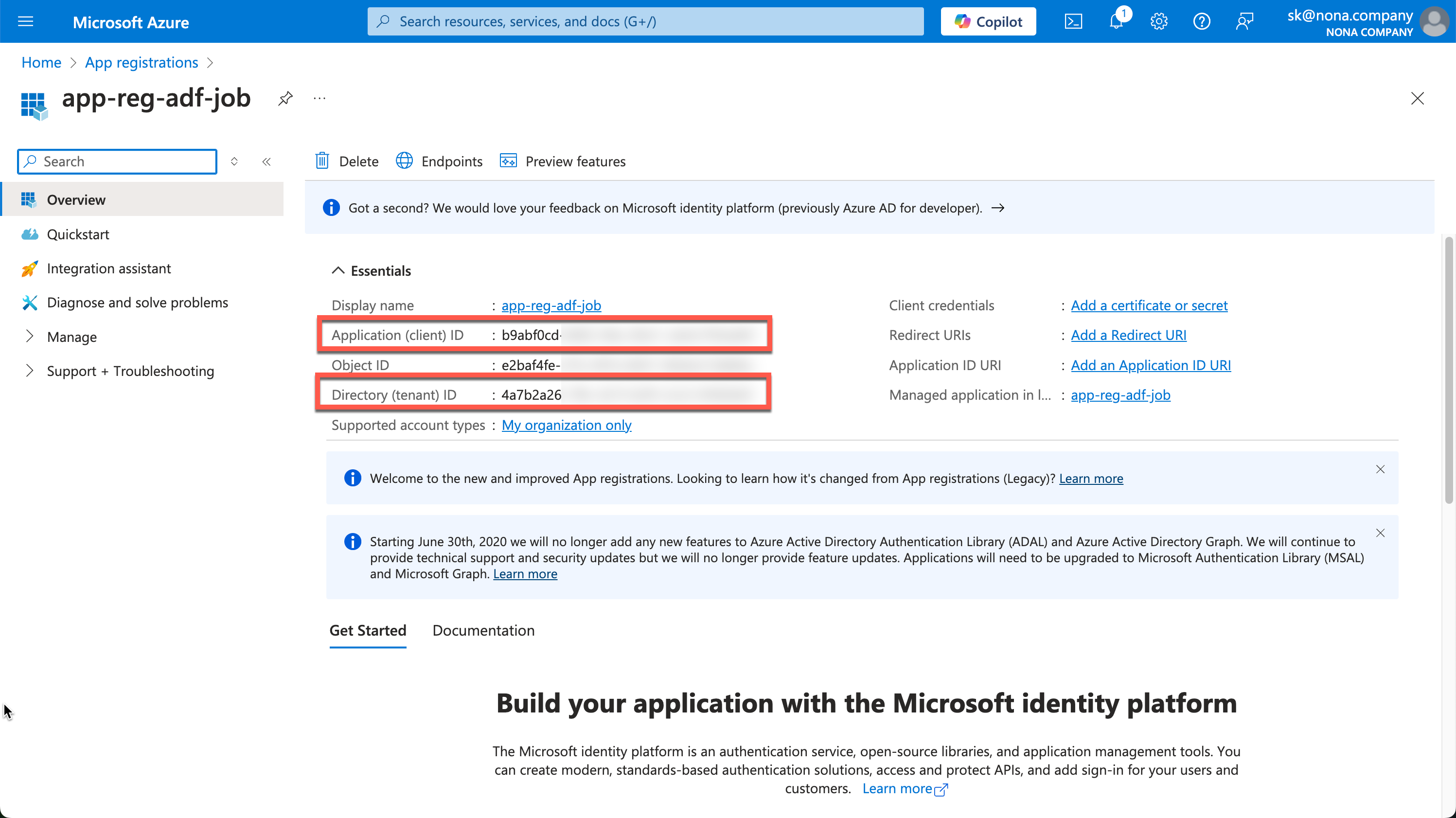
Now we need a secret, which we can create under “Certificates & secrets.”
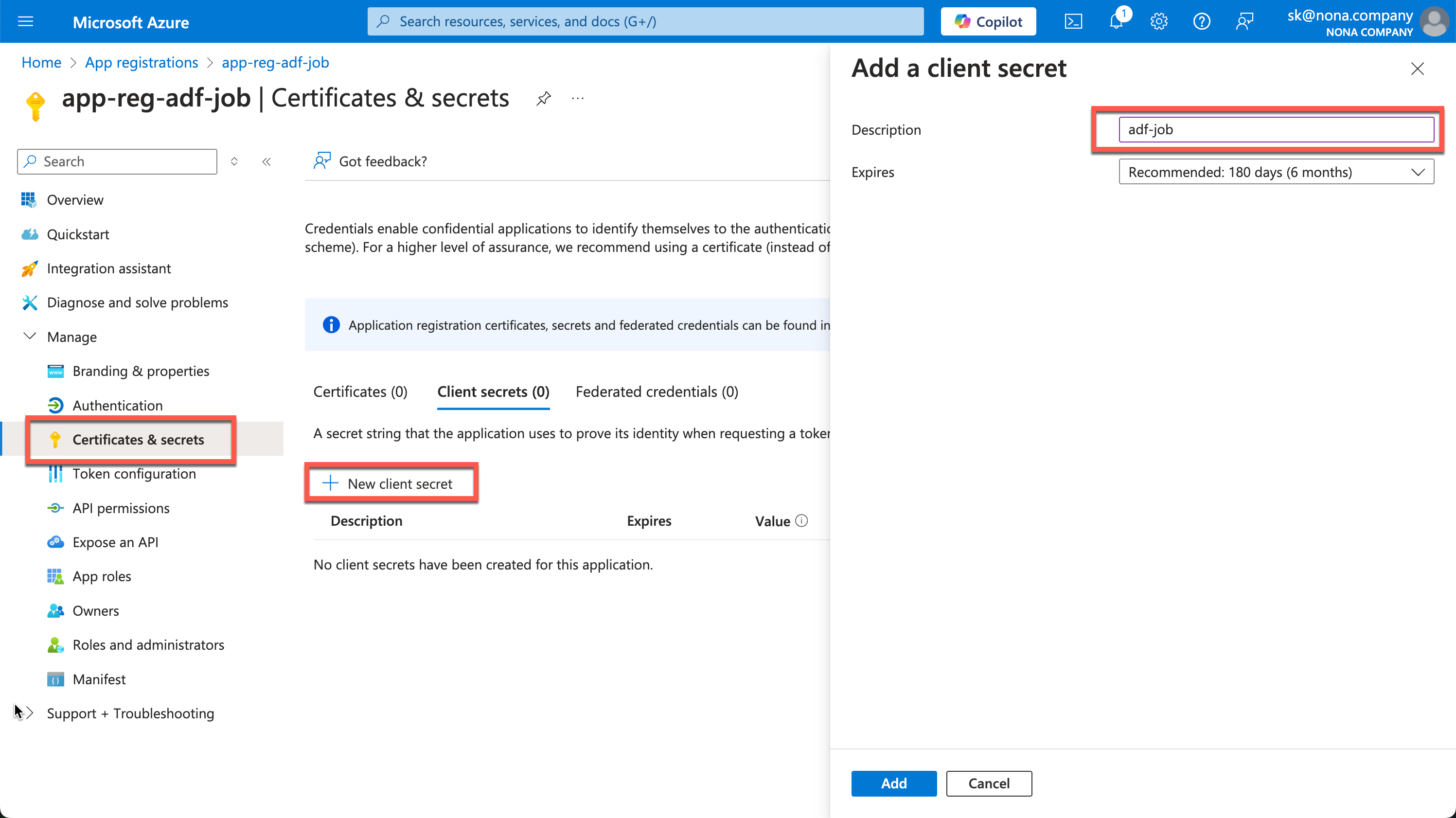
The created secret is then displayed in the value field. This process is only possible once, so the secret must be copied out immediately and saved in a safe place.
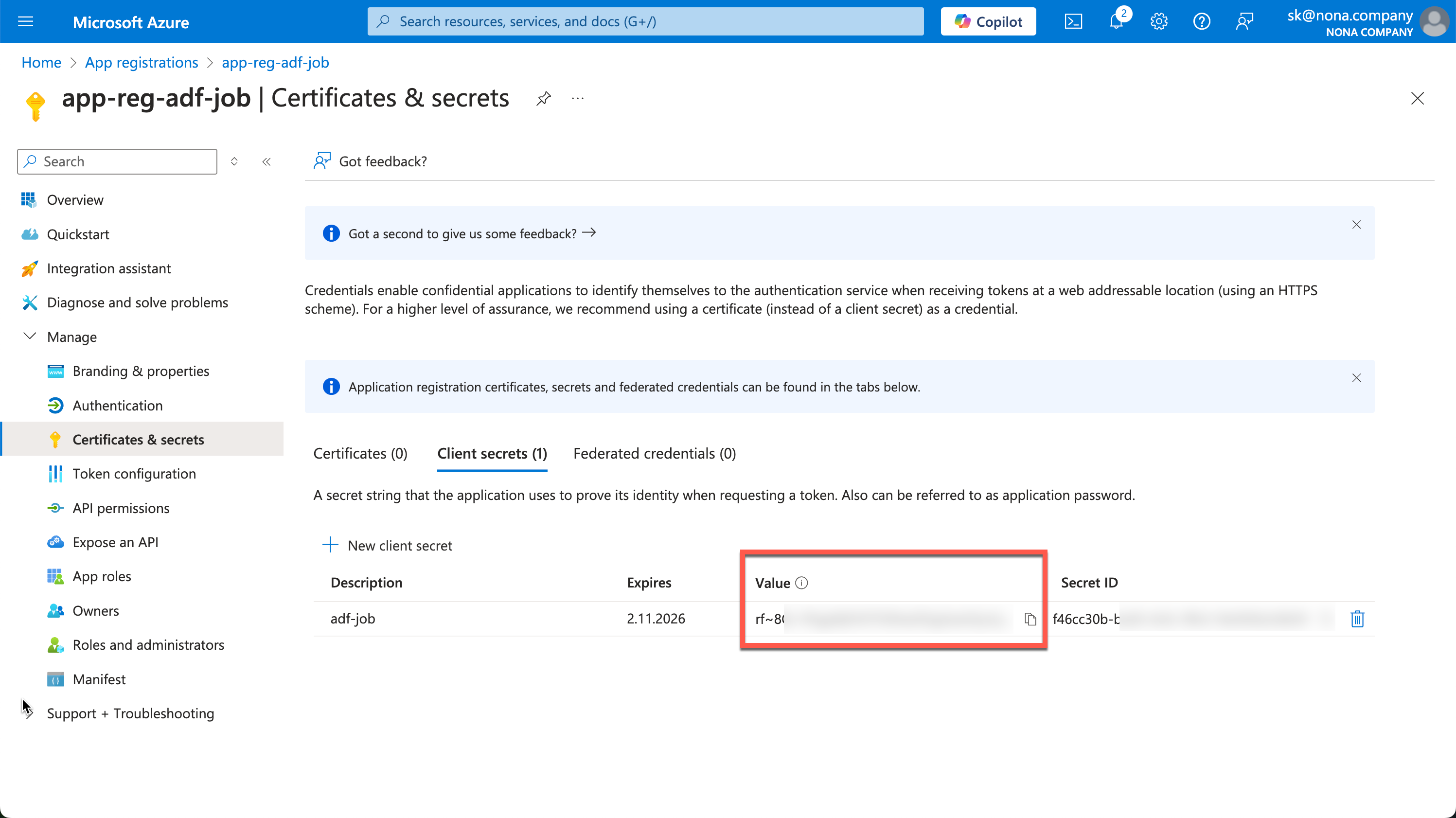
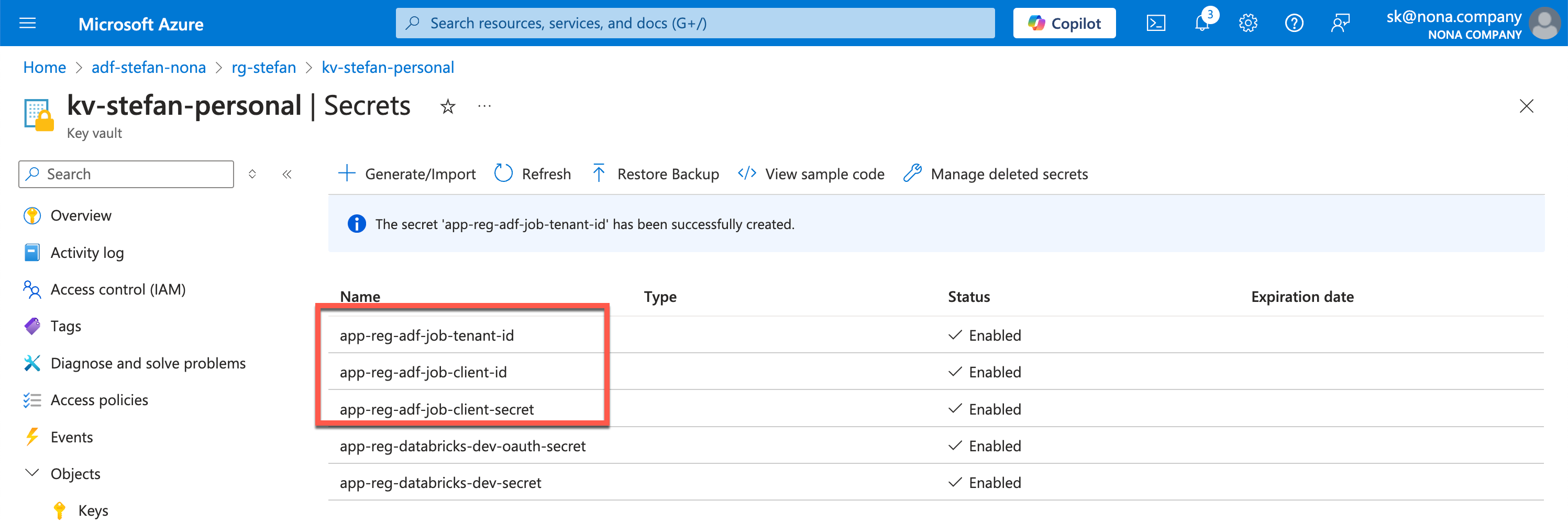
I store this information in my KeyVault.
Authorizing the service principal on the data factory
In order for the service principal to have the correct authorizations to start an ADF pipeline, it must be authorized on the ADF resource. To do this, go to the corresponding resource in the Azure portal.
Note: Of course, I would not set such an authorization manually in a real data project, but via IaC such as Terraform.
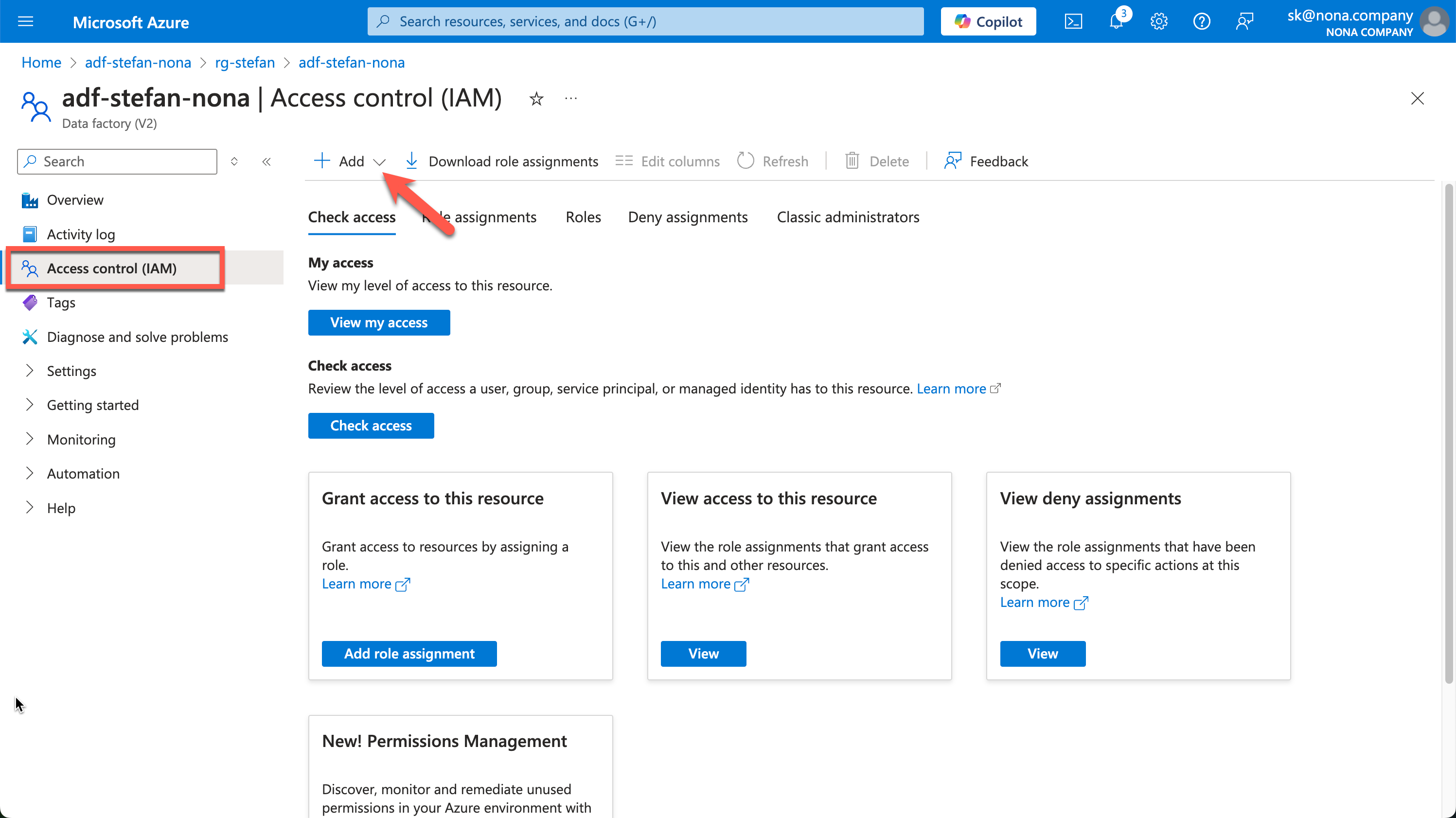
When creating the role assignment, I give the service principal “Data Factory Contributor” rights. You can search for the name of the service principal under “Select members.”
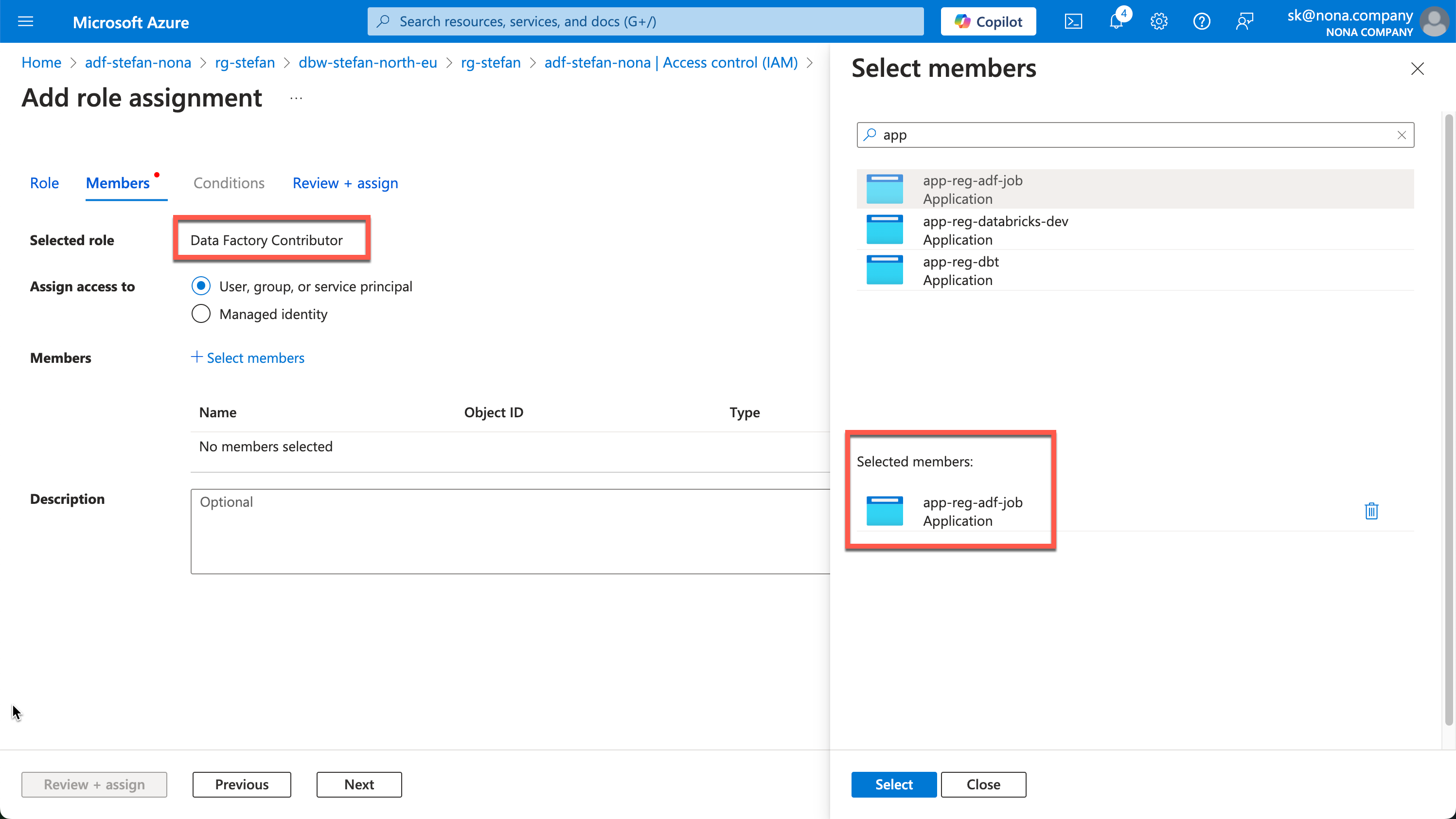
Databricks Secret Scope with KeyVault integration
Later on in the example, I don’t want to save the secrets for the app registration in plain text in the code. For this reason, I will create a secret scope in Databricks that points to the KeyVault in which I have entered the corresponding secrets. There are also detailed instructions on how to create the secret scope and connect it to the KeyVault: https://learn.microsoft.com/en-us/azure/databricks/security/secrets/secret-scopes
In my example, I call the secret scope “kv”.
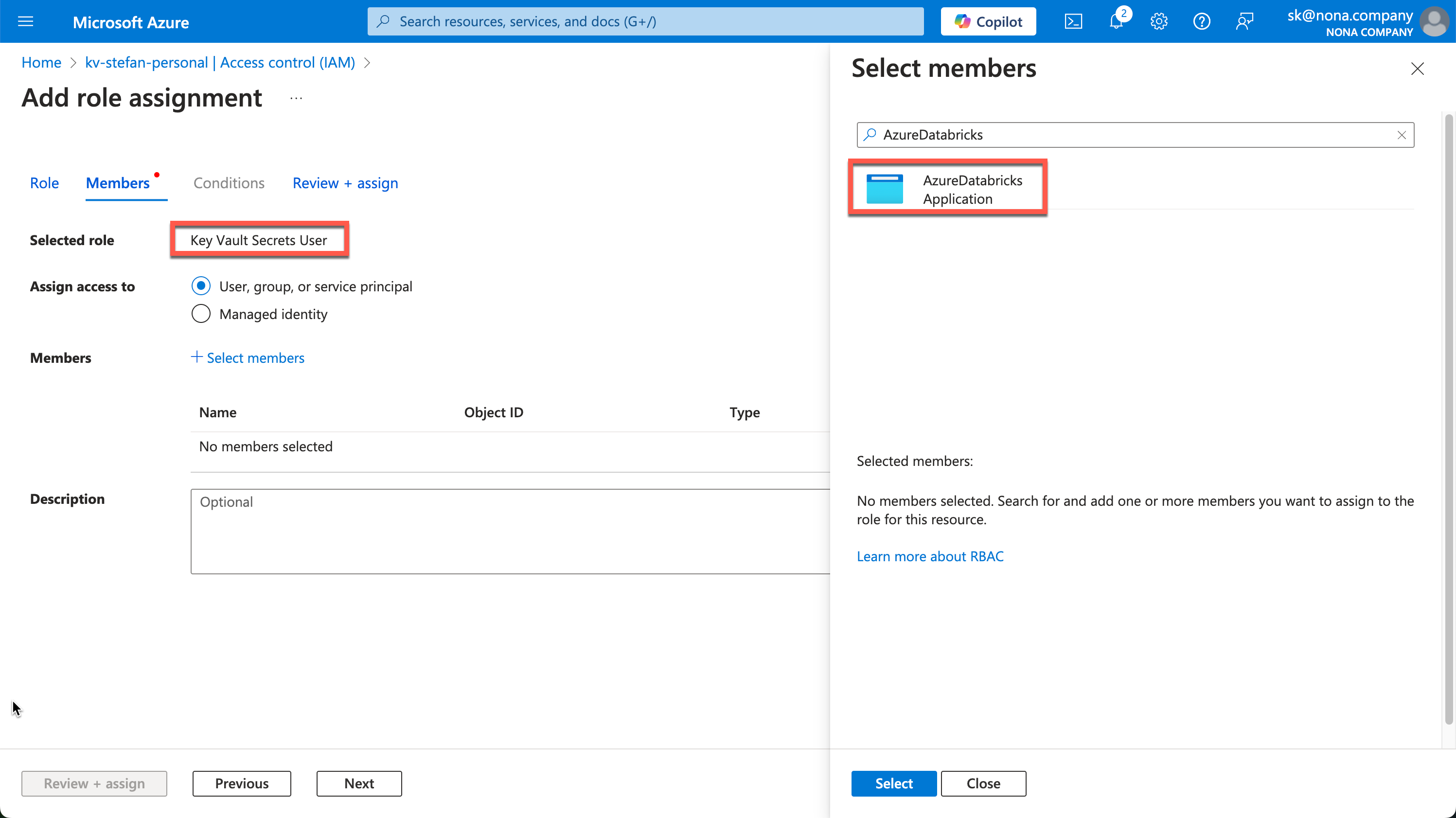
In addition, databricks must be authorized on the KeyVault, otherwise you will receive an error message like this:

This authorization is set on the KeyVault resource, similar to how it was set on the Data Factory resource. At the moment, I don’t want to change any secrets via Databricks, only read them, so I assign the “Key Vault Secrets User” role and assign it to the “AzureDatabricks” application.
Databricks Notebook for ADF REST API Call
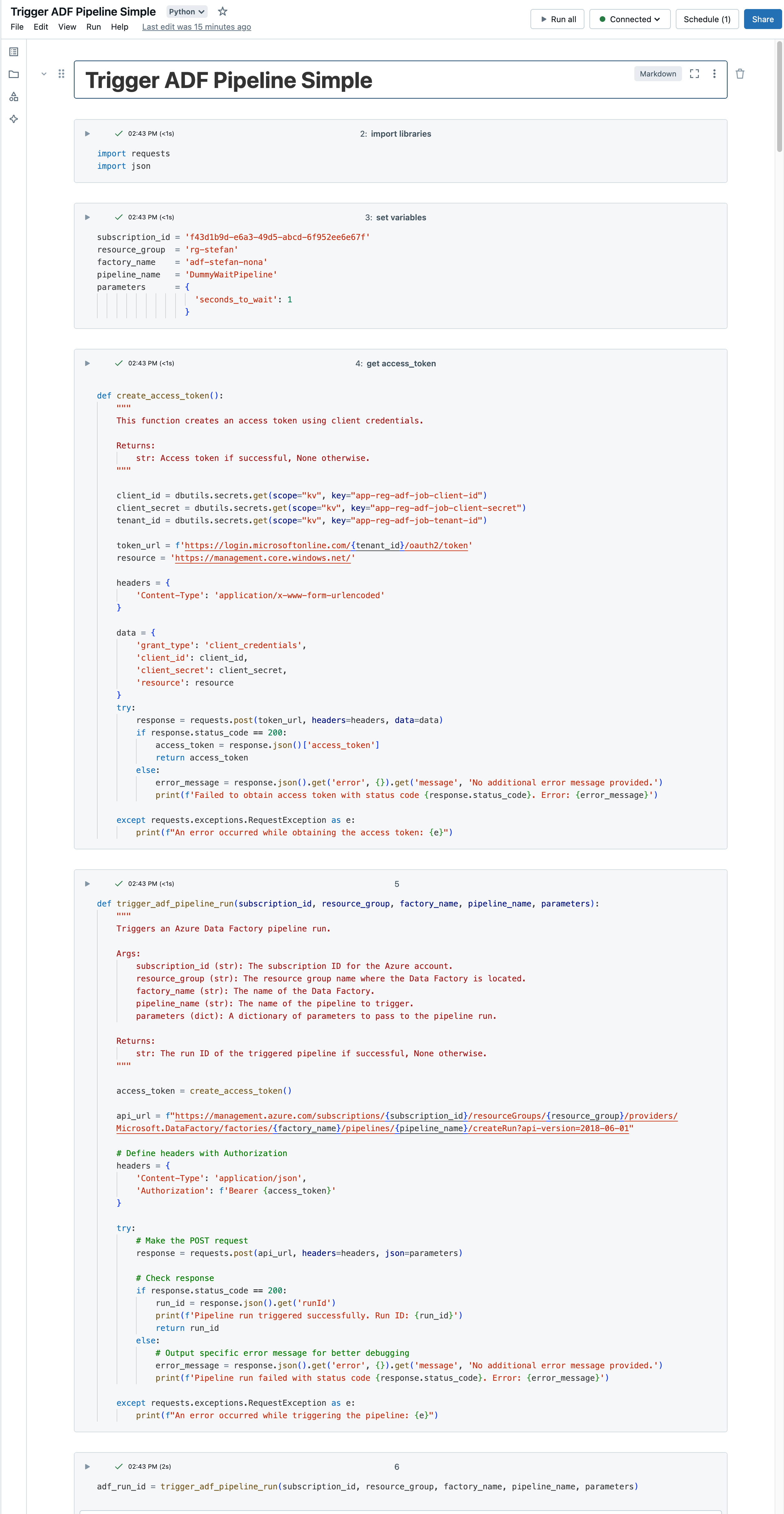
In this example, I would like to make a simple REST call. First I have to import the corresponding Python libraries and then I set various variables so that I can control my correct data factory. I can pack the pipeline parameters for the data factory into a dictionary and thus extend them as required.
|
|
To interact with the Azure management API, you must first generate an access token using the service principal’s credentials. I have written a function for this purpose.
|
|
Now that the access token has been generated, the next step is to implement the start of the pipeline. So that I can keep the whole thing a little generic, I have also created a simple function.
|
|
To start the ADF pipeline, I call the function:
|
|
I then receive a success message in Databricks that the pipeline has been started:

A look at the Data Factory also shows the successful run. Since I played around a bit with the Databricks notebook, you can see several runs:
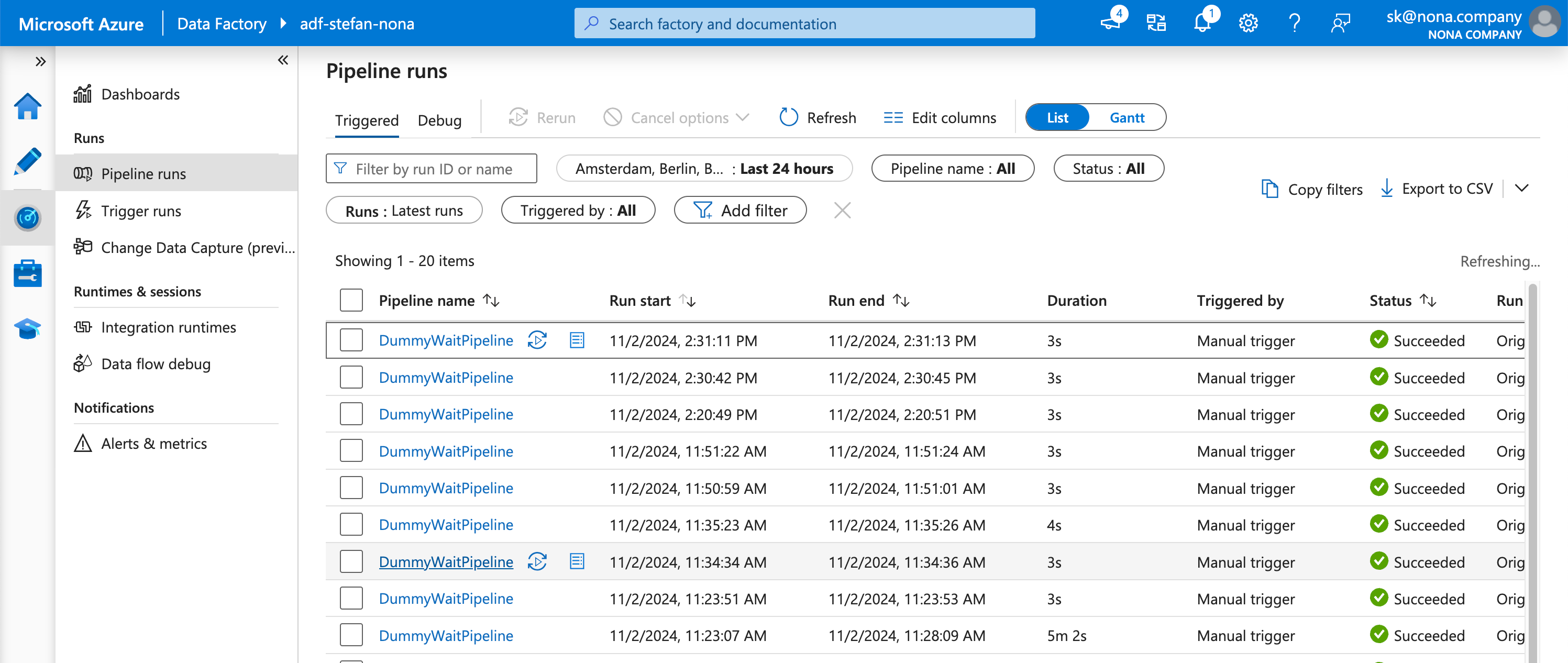
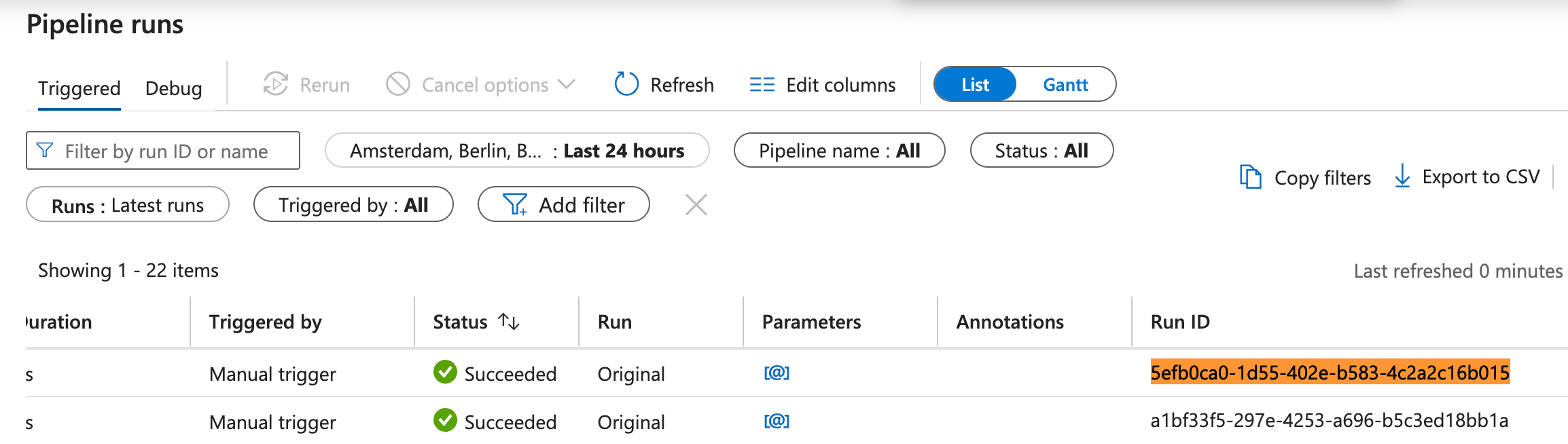
When I sort by run-id, I find the corresponding run:
The Databricks notebook then looks like this:
Databricks Workflows Job
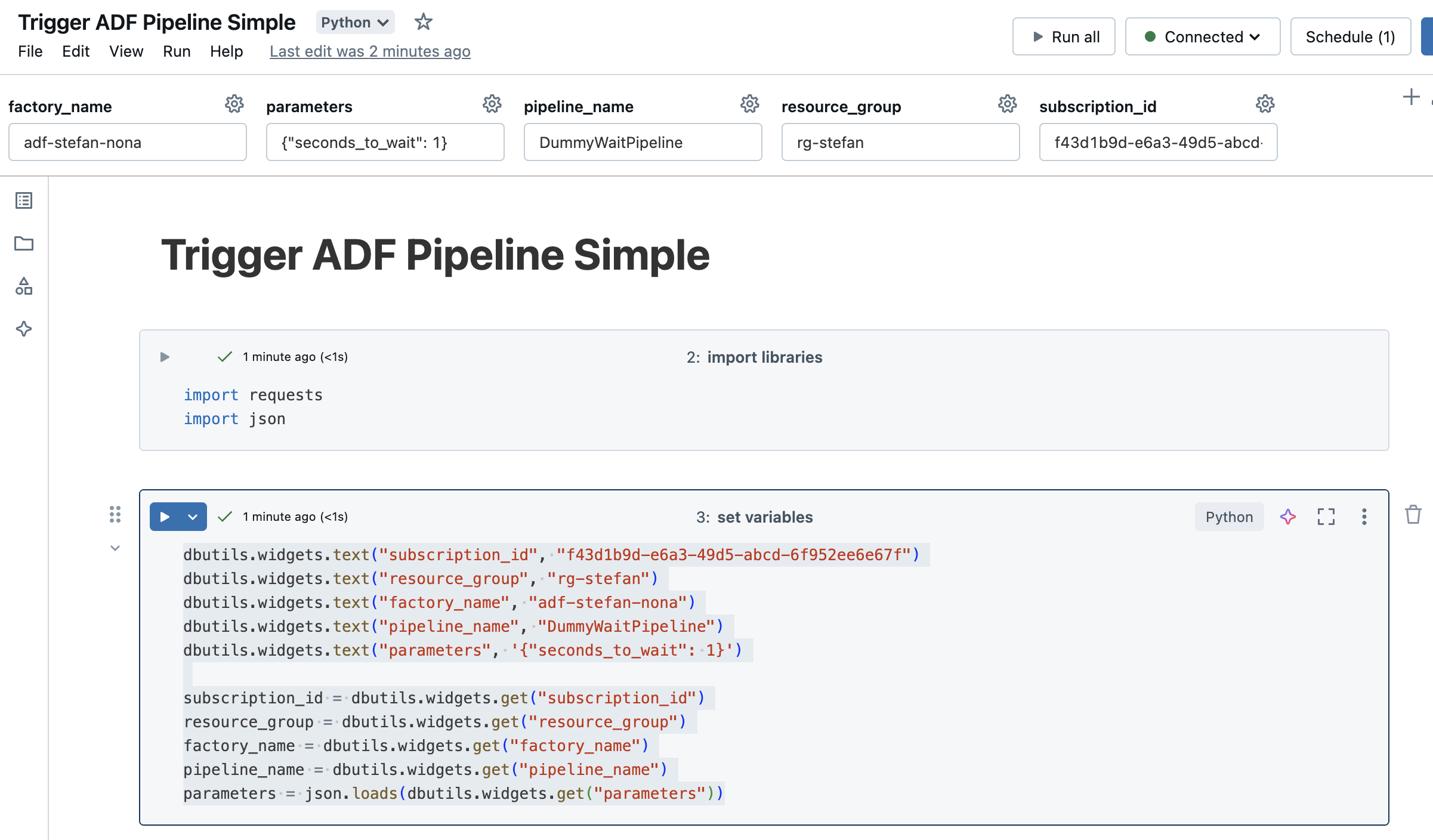
Now I’m putting the whole thing into a Databricks job. But before I configure the job, I will customize the notebook a bit. I will not write the variables hard-coded in the notebook, but add them as widgets. This way I can also reuse the notebook for other pipelines.
|
|
It looks like this:
In the Workflows tab, I create a new job and give it a descriptive name. I select Notebook as the task and enter the path to the previously created notebook.
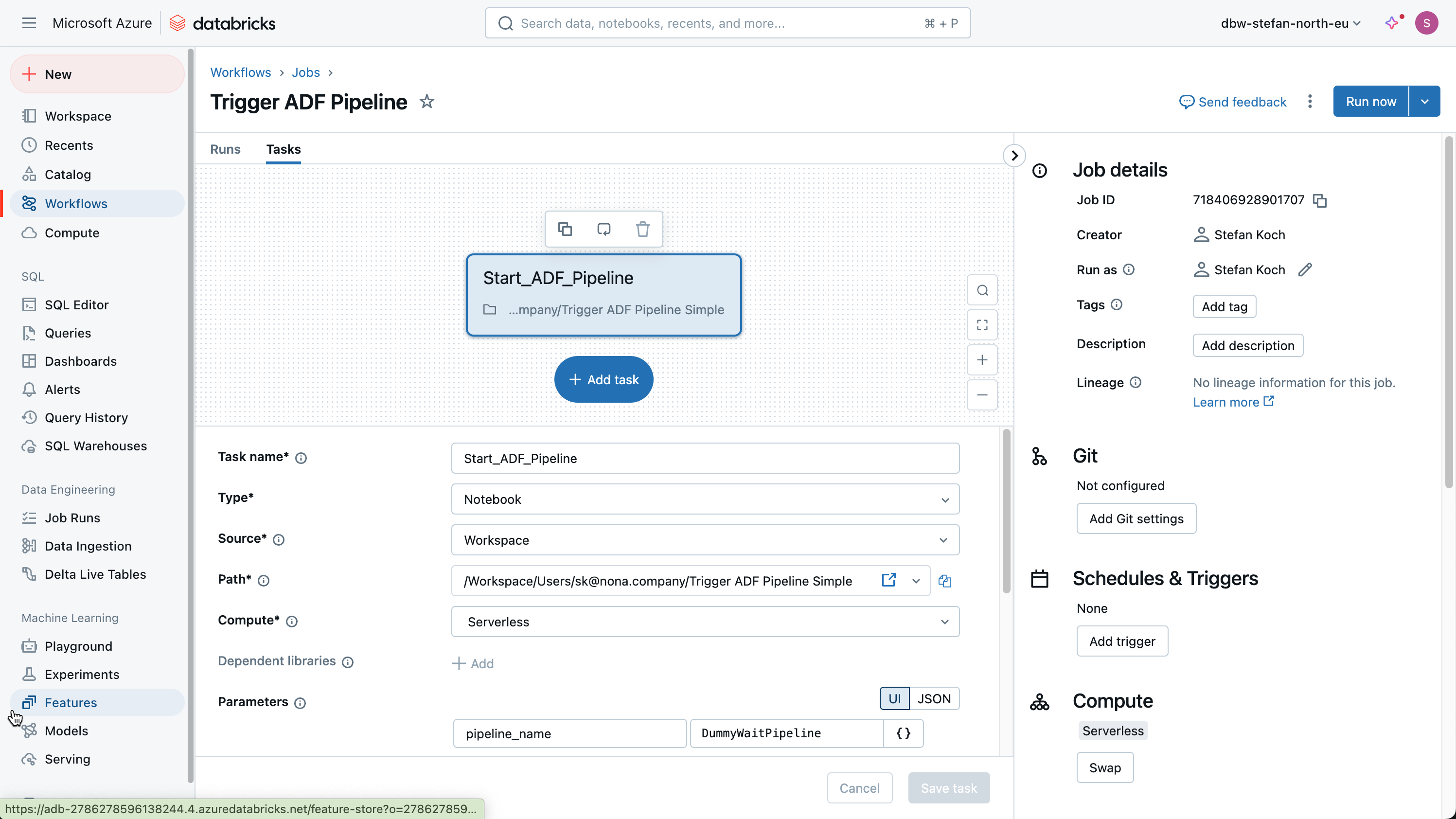
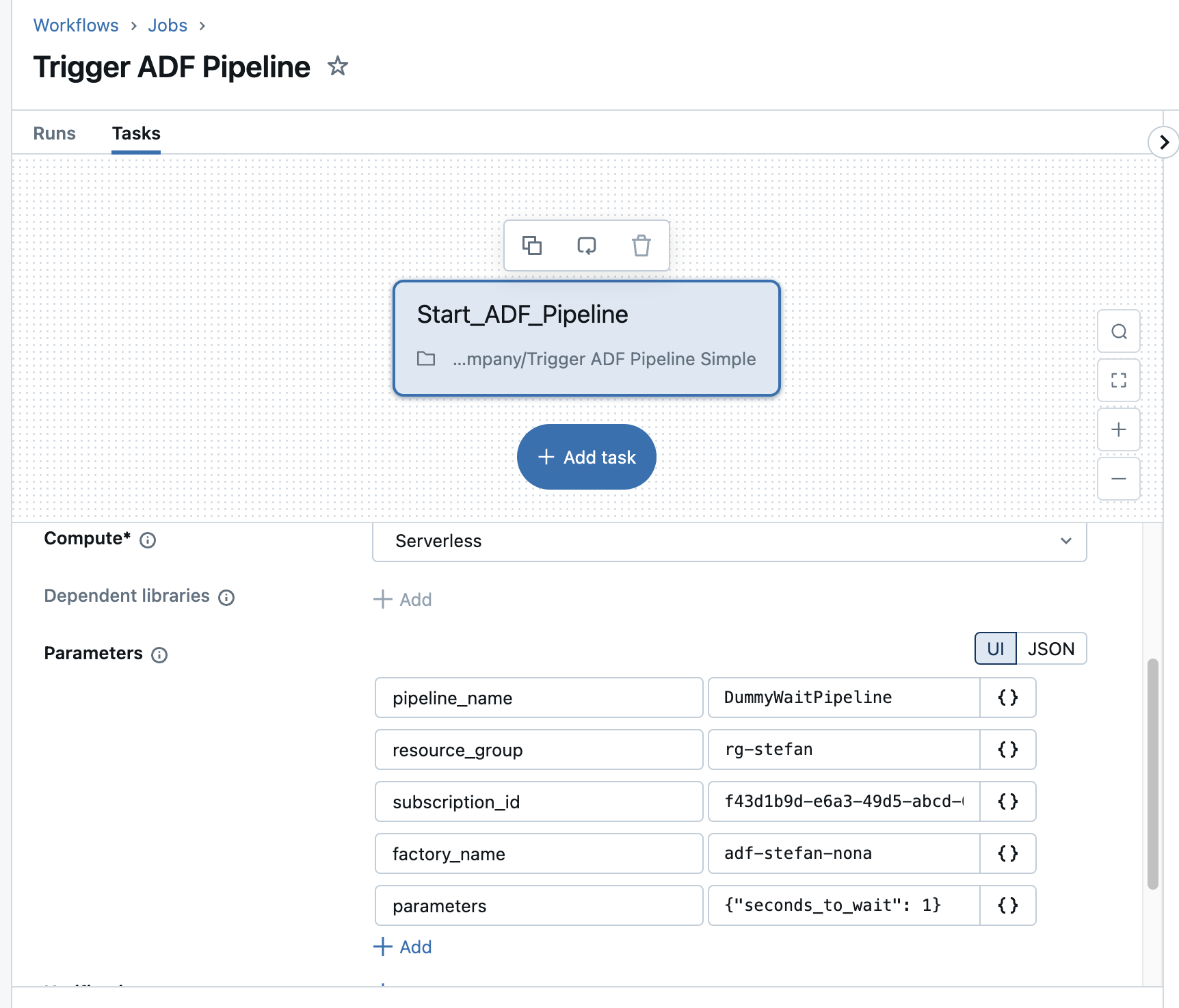
I also enter the required information in the parameters.
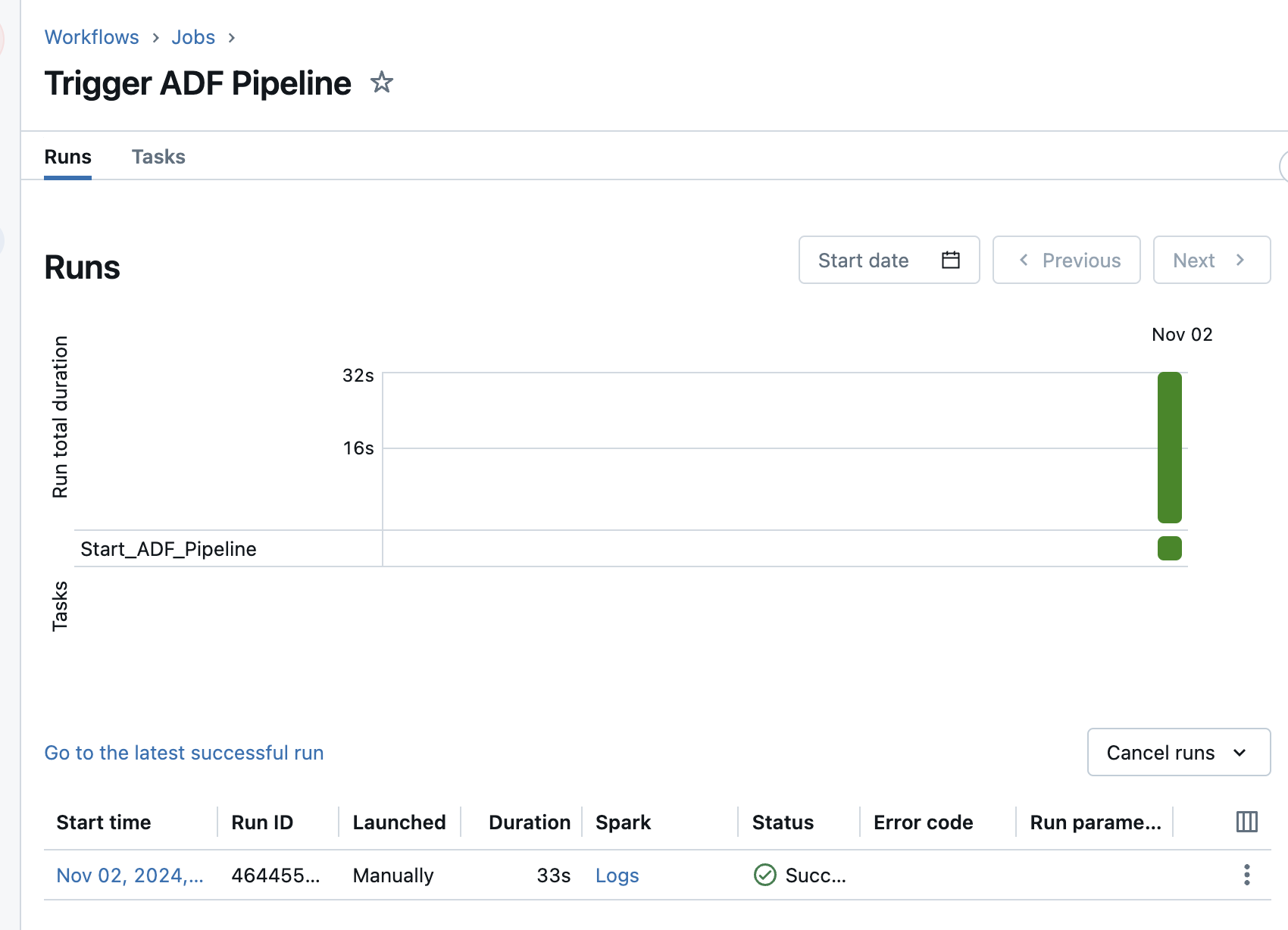
I can start the job by clicking on “Run now”. After a few seconds, the job runs successfully.
If you click on the run, you can also see the details of the run.
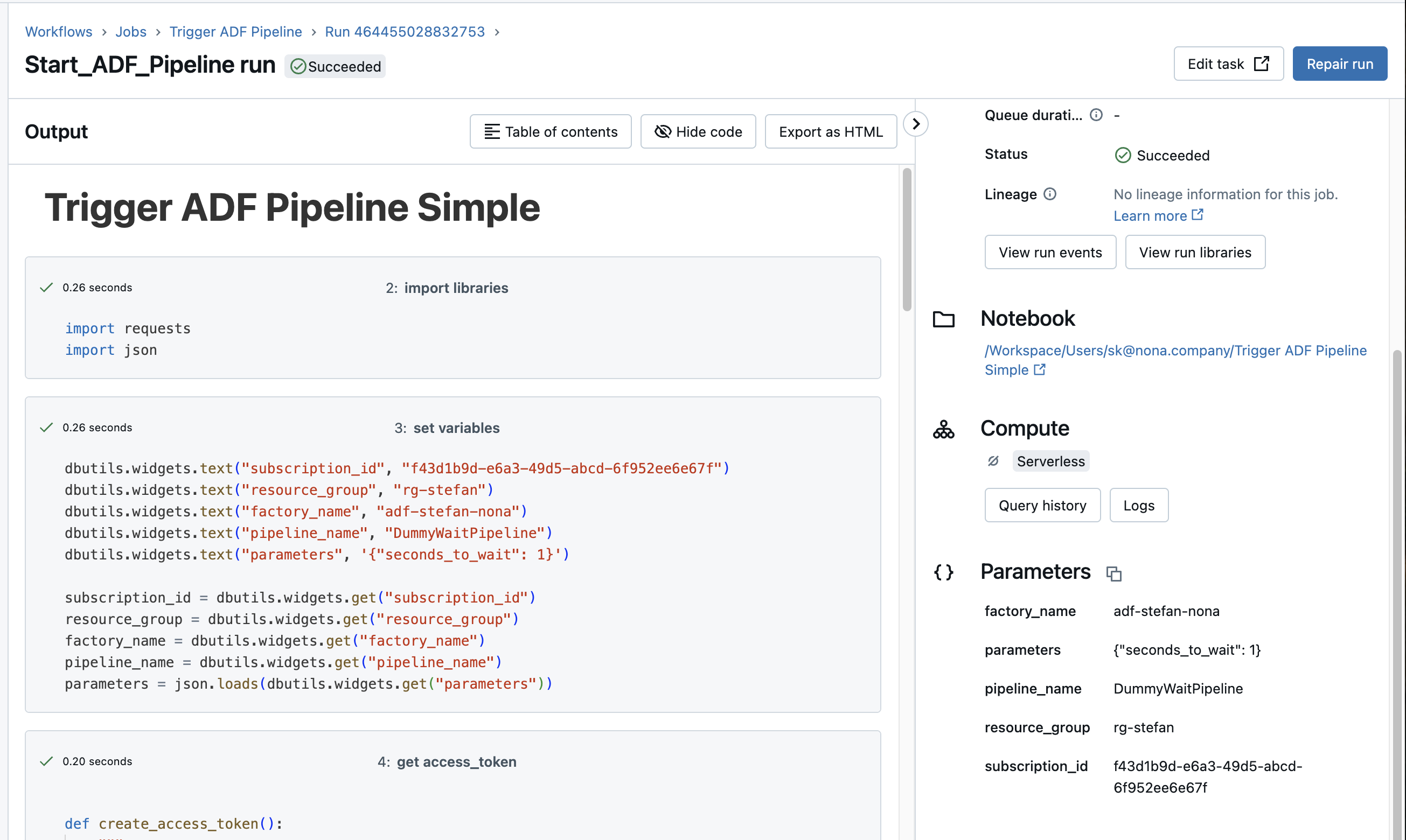
What about the runtime? Is Databricks waiting for ADF?
The question I’m asking myself now is what happens if the Data Factory pipeline has a long runtime? Does the Databricks workflow then wait until the ADF pipeline is finished? That would cause unnecessary costs. To answer this question, I will set the waiting time of the dummy pipeline to 5 minutes. All I have to do is change the corresponding value in the parameters.
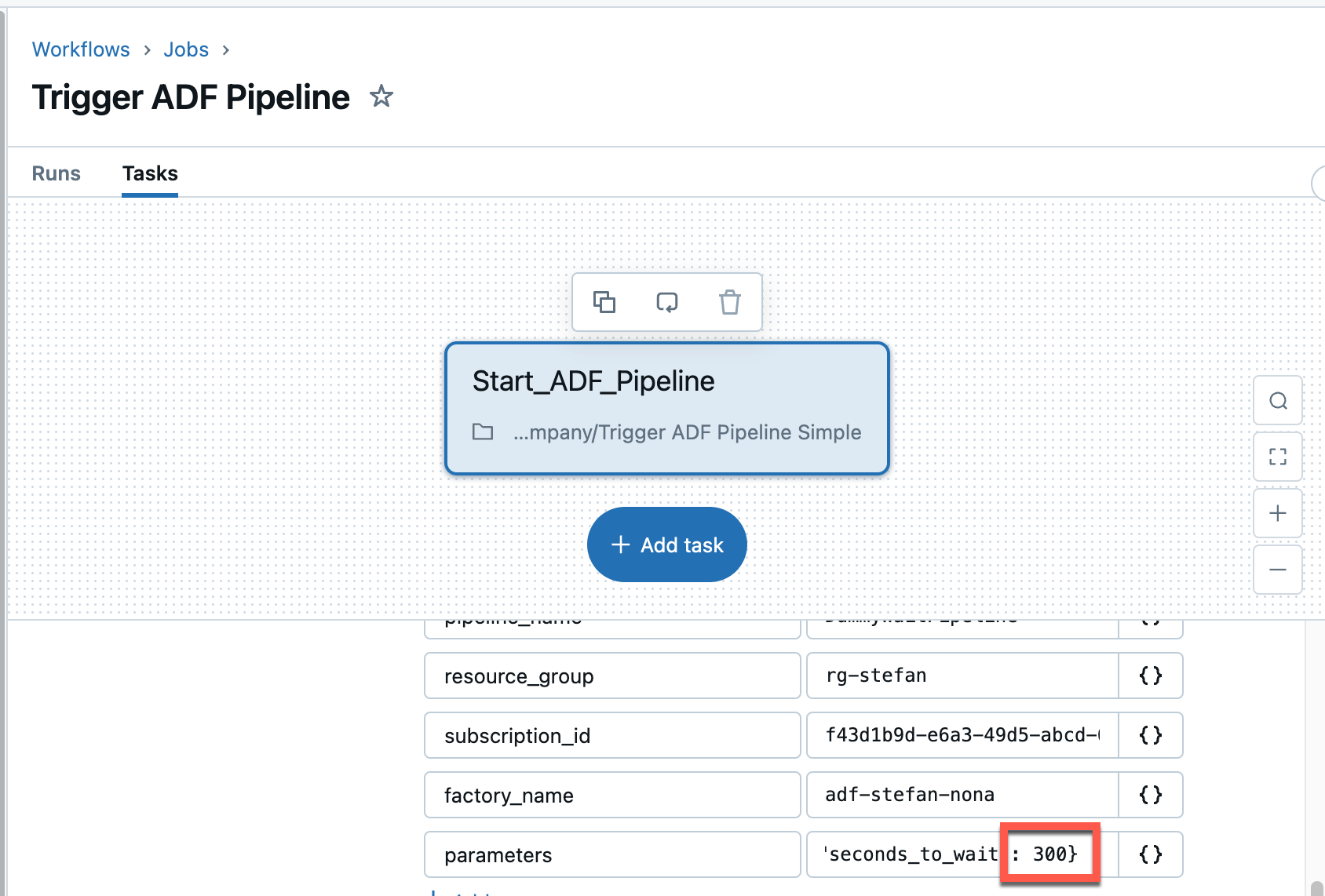
Well, as it turns out, the runtime has not changed as a result. The Databricks pipeline runs for exactly 32 seconds and is then terminated. The first run took 33 seconds. This means that the Databricks job does not wait for the execution of the ADF pipeline.
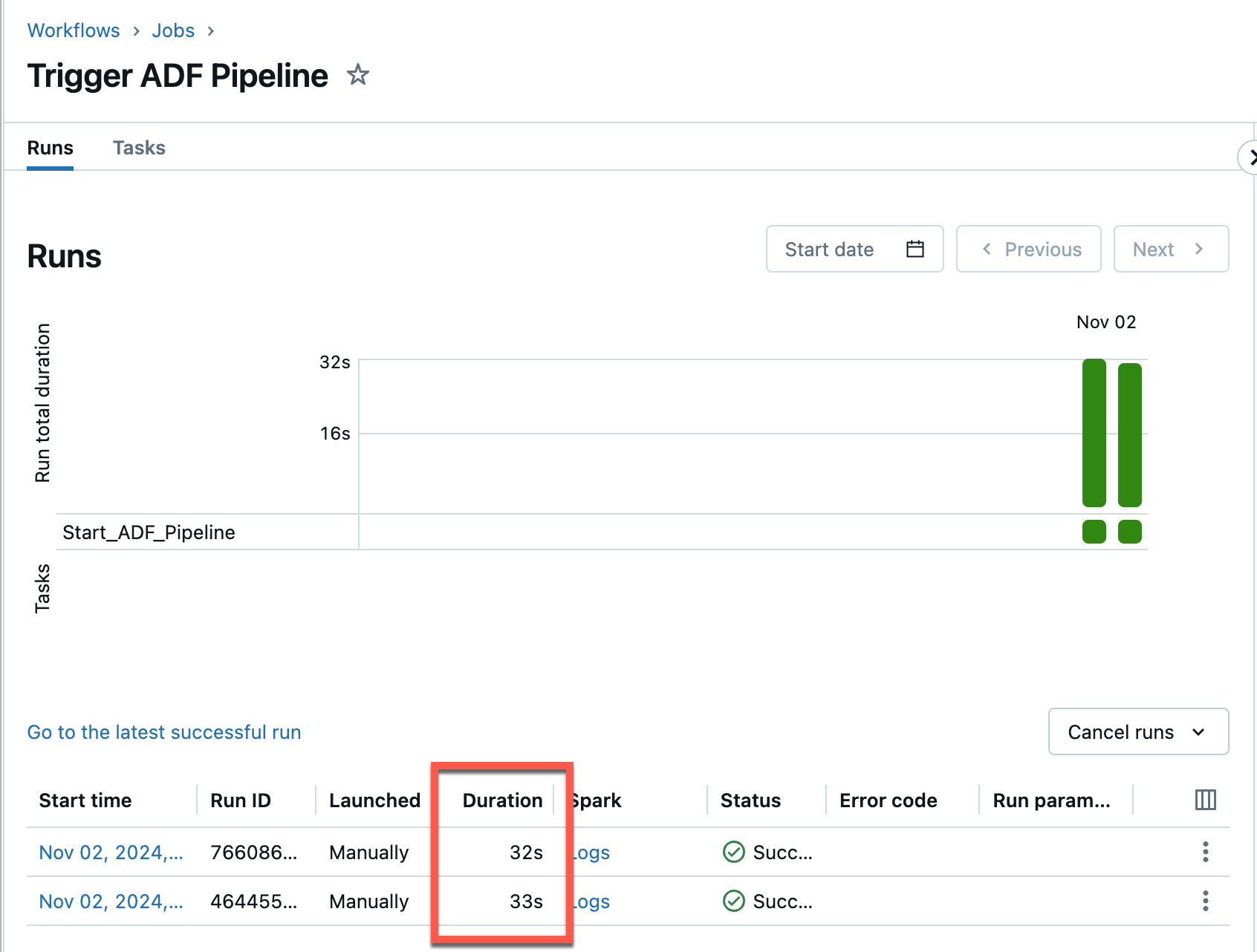
And here is the screenshot of the ADF execution:
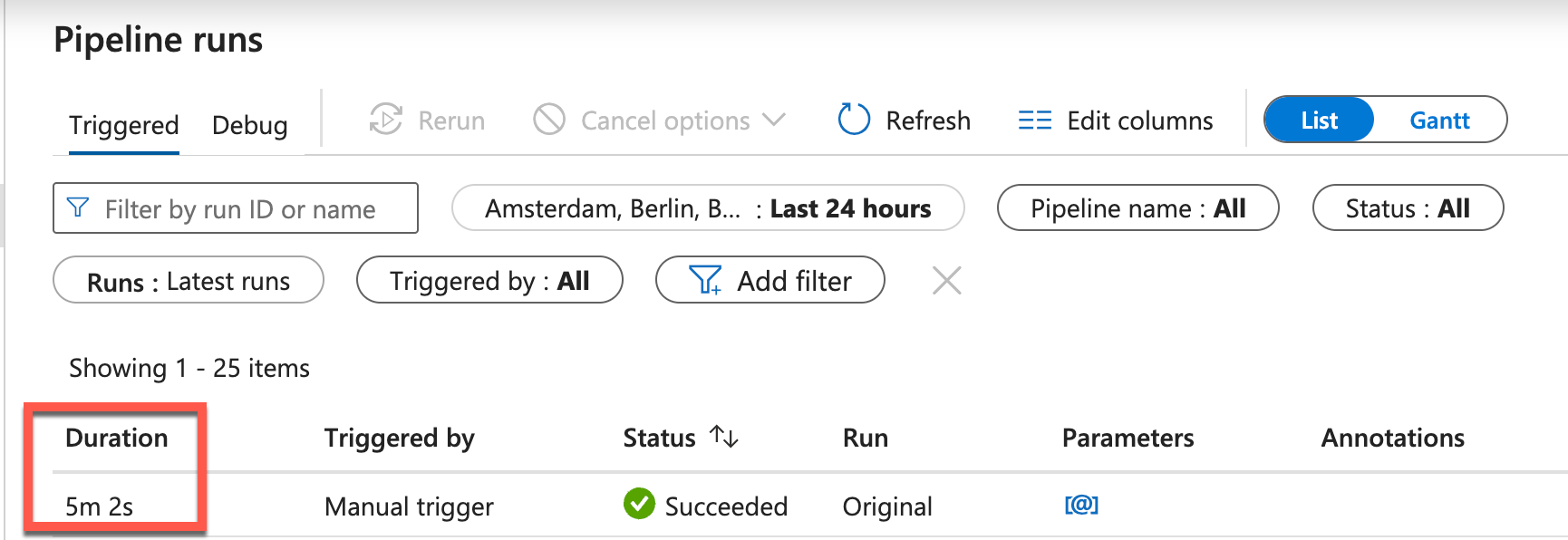
This means that compute resources are not wasted unnecessarily. On the other hand, I don’t know whether the job in the ADF has been successfully completed.
Check ADF-Pipeline Run via REST API
In another example, I would like to extend the notebook and see what the current status of the pipeline is. For this purpose, I rewrite the Databricks notebook a little and add a function to it. The Microsoft documentation describes in detail how to get the status of an ADF pipeline run via REST: https://learn.microsoft.com/en-us/rest/api/datafactory/pipeline-runs/get?view=rest-datafactory-2018-06-01&tabs=HTTP
First I add 2 widgets, adf_run_id and action.
|
|
I copied the previous function trigger_adf_pipeline_run and created a new function that queries the status.
|
|
I have also rewritten the function call accordingly.
|
|
If I now run the notebook with the action ‘check_adf_pipeline’, I get the following response:
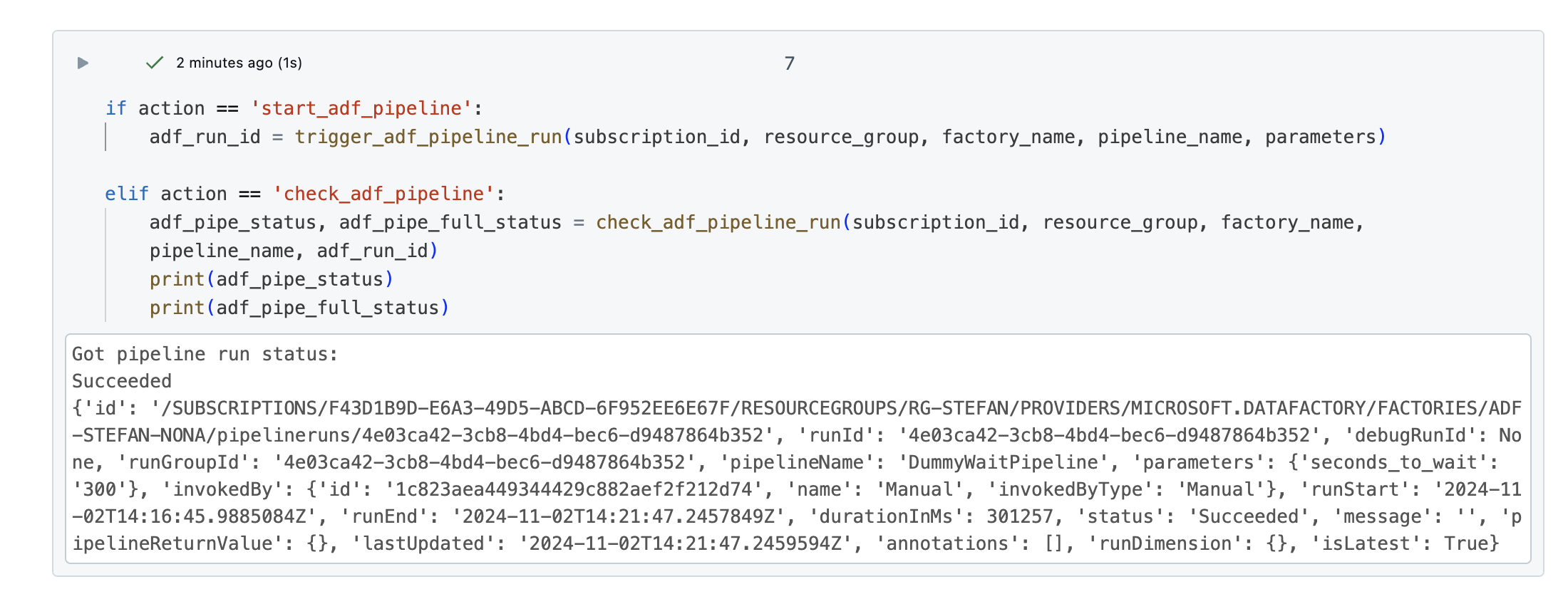
Now I can query the status of an ADF pipeline programmatically. But I have to bear in mind that this is only half the battle. What I don’t want to do is trigger an ADF pipeline and then check every 5 minutes with a Databricks job to see if the pipeline is complete.
What would make more sense here is that at the end of the ADF pipeline, when the relevant tasks have been processed, the ADF pipeline triggers a Databricks job. This can be realized by creating an additional task at the end. In this way, you would be informed immediately and can then start another job in Databricks. Calling a Databricks job would also be implemented via a REST call.
Preparation for Trigger Databricks Job from Azure Data Factory
Before I dedicate myself to the actual rest of the call, I make a few small preparations. Firstly, I create a simple notebook that is to be executed in a job.
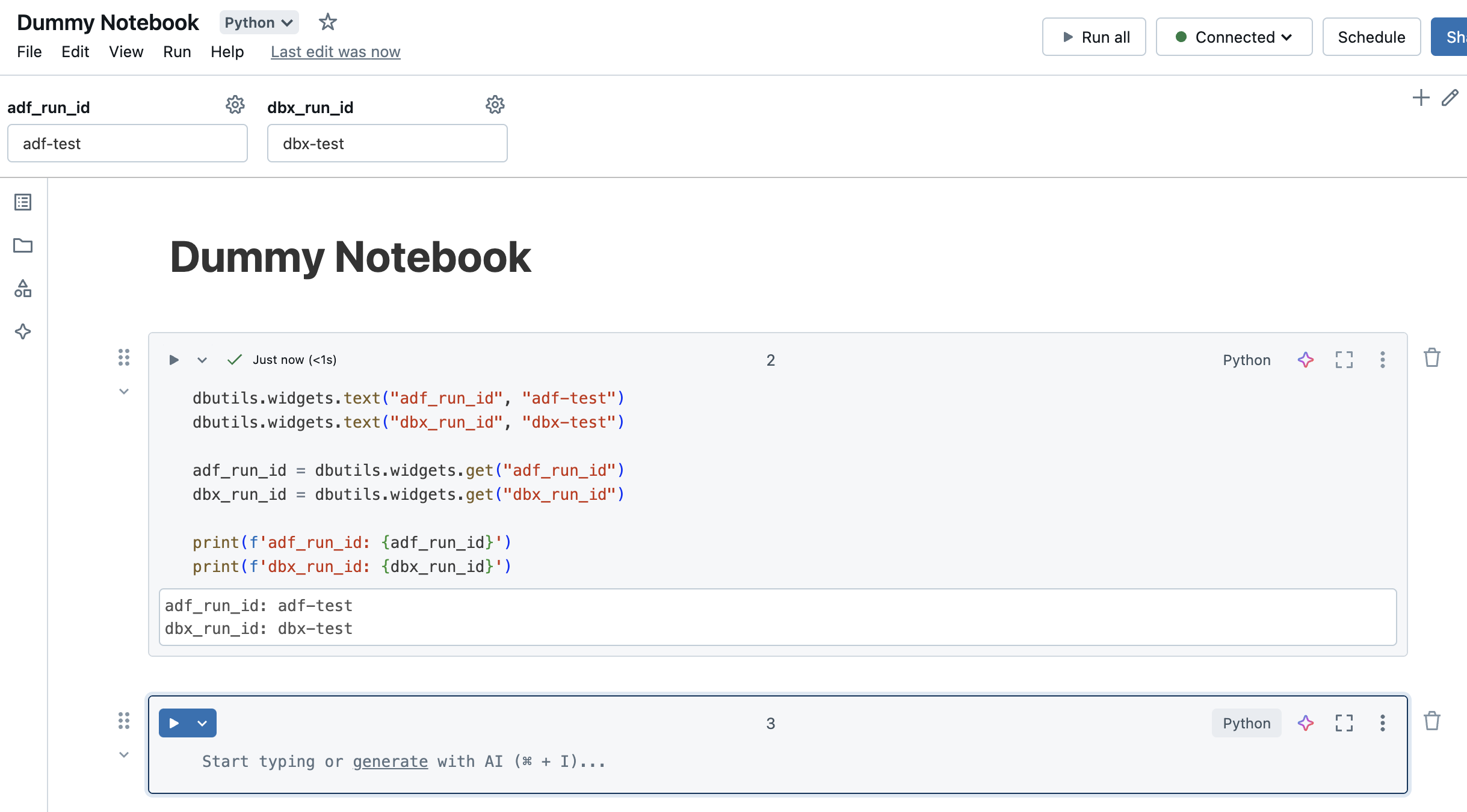
The notebook does nothing other than accept and print 2 parameters. These are the run ID of the ADF and the run ID of Databricks. To execute the notebook automatically, I create the corresponding Databricks job.
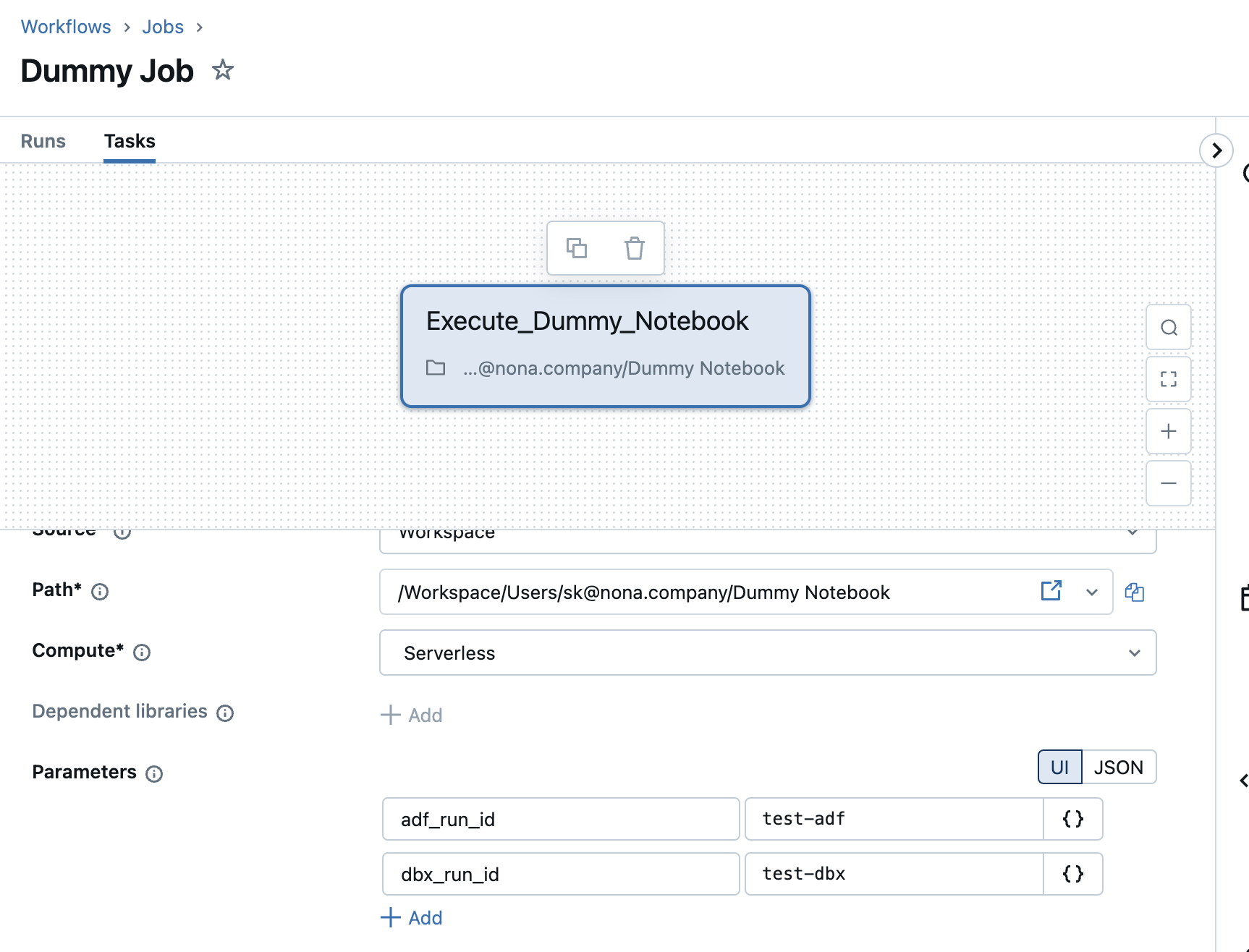
Service principal to start Databricks workflow job
The job in Databricks must be executed via a service principal. We also need this service principal to make the REST call. This means that there is a machine-to-machine athentication.
For the sake of simplicity, I use the same service principal with which I start the ADF pipeline. In practice, however, it makes sense to create another service principal.
I will add the service principal in the Databricks account. To open it, I go to the account:
https://accounts.azuredatabricks.net/
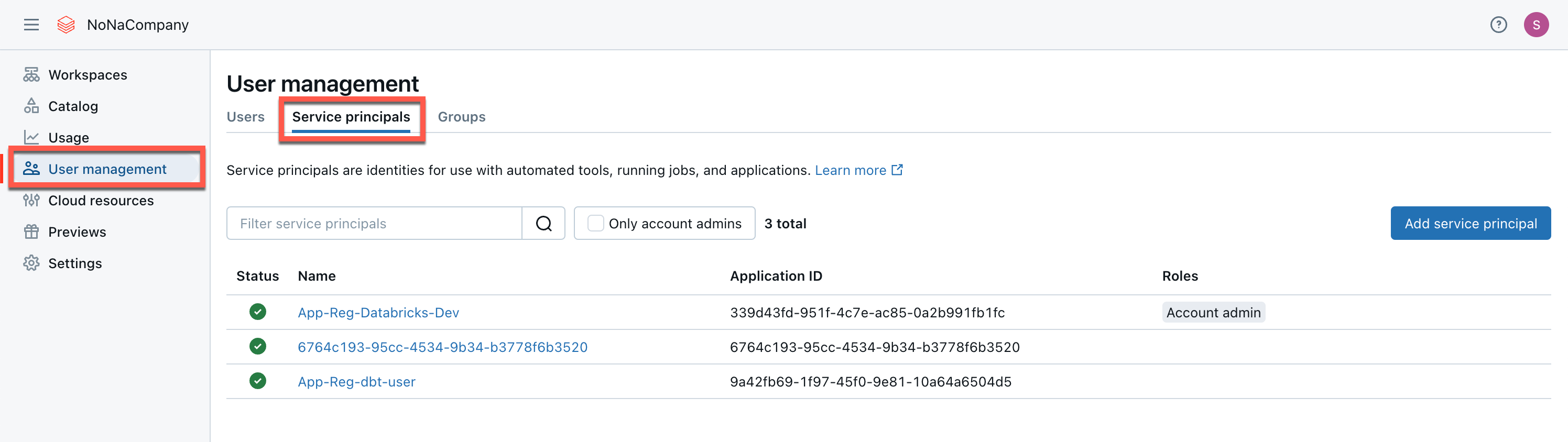
As the service principal has already been created, I select “Microsoft Entra ID managed”.
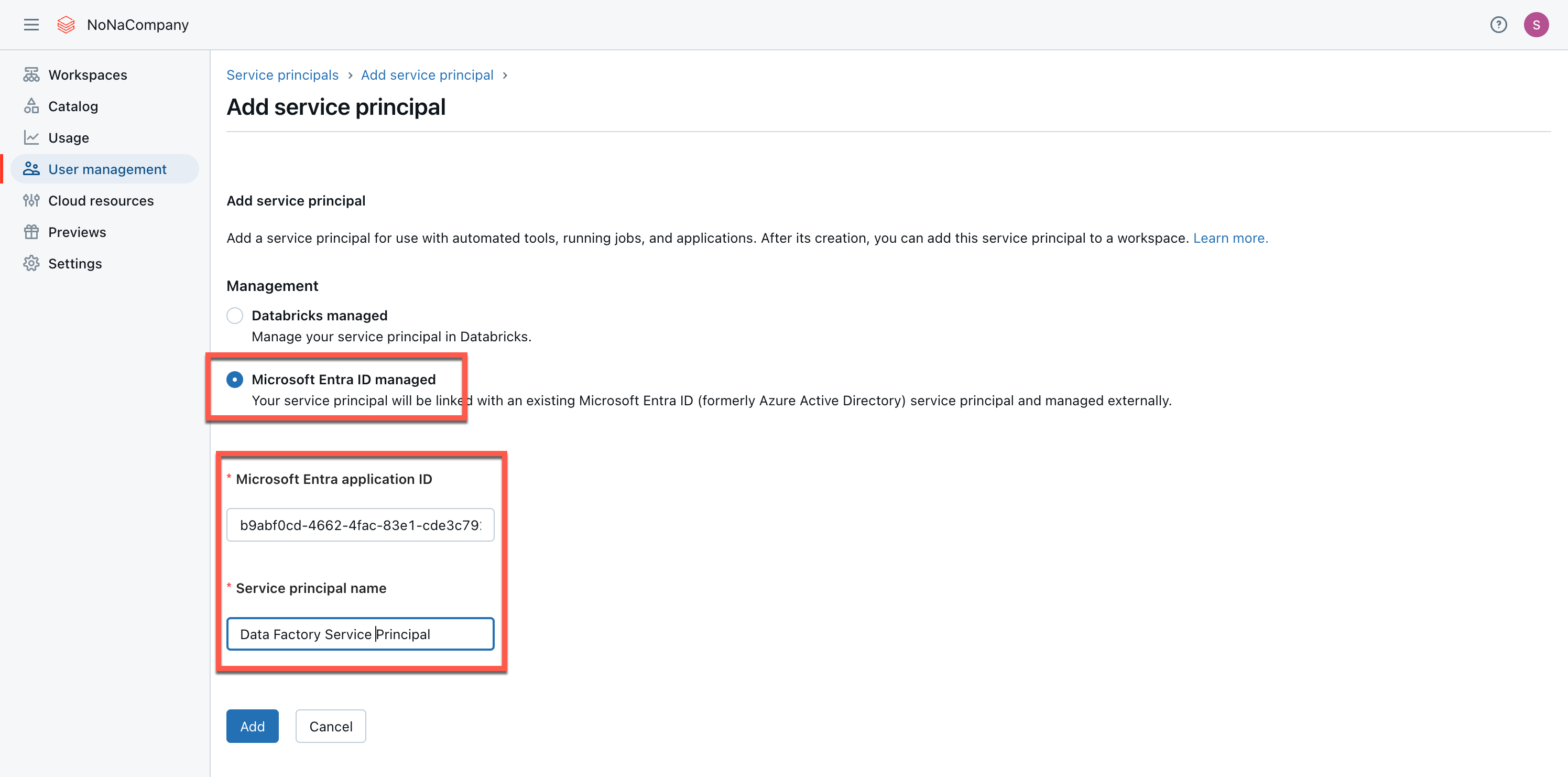
Then I go to the workspace and add the service principal to the workspace.
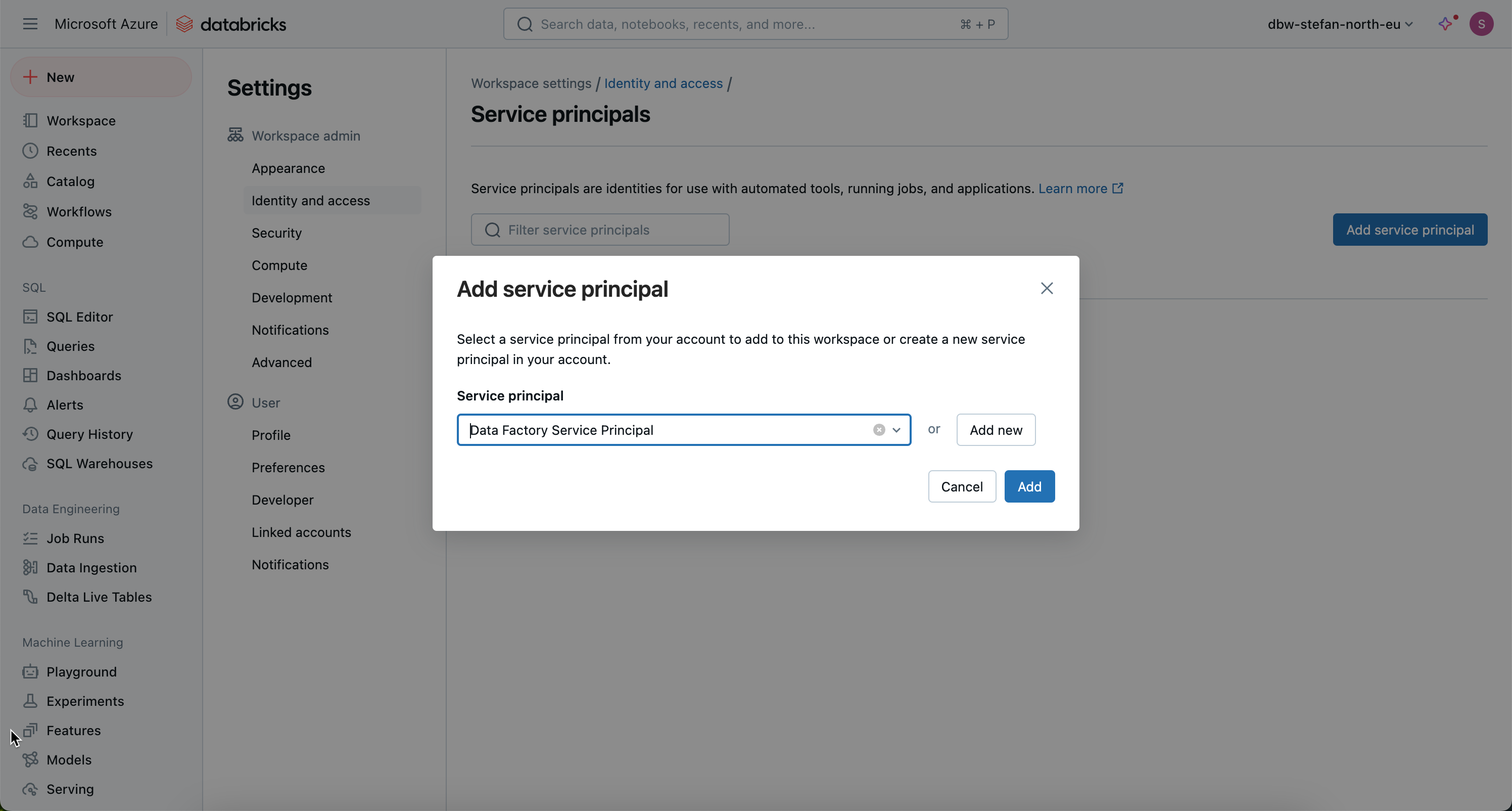
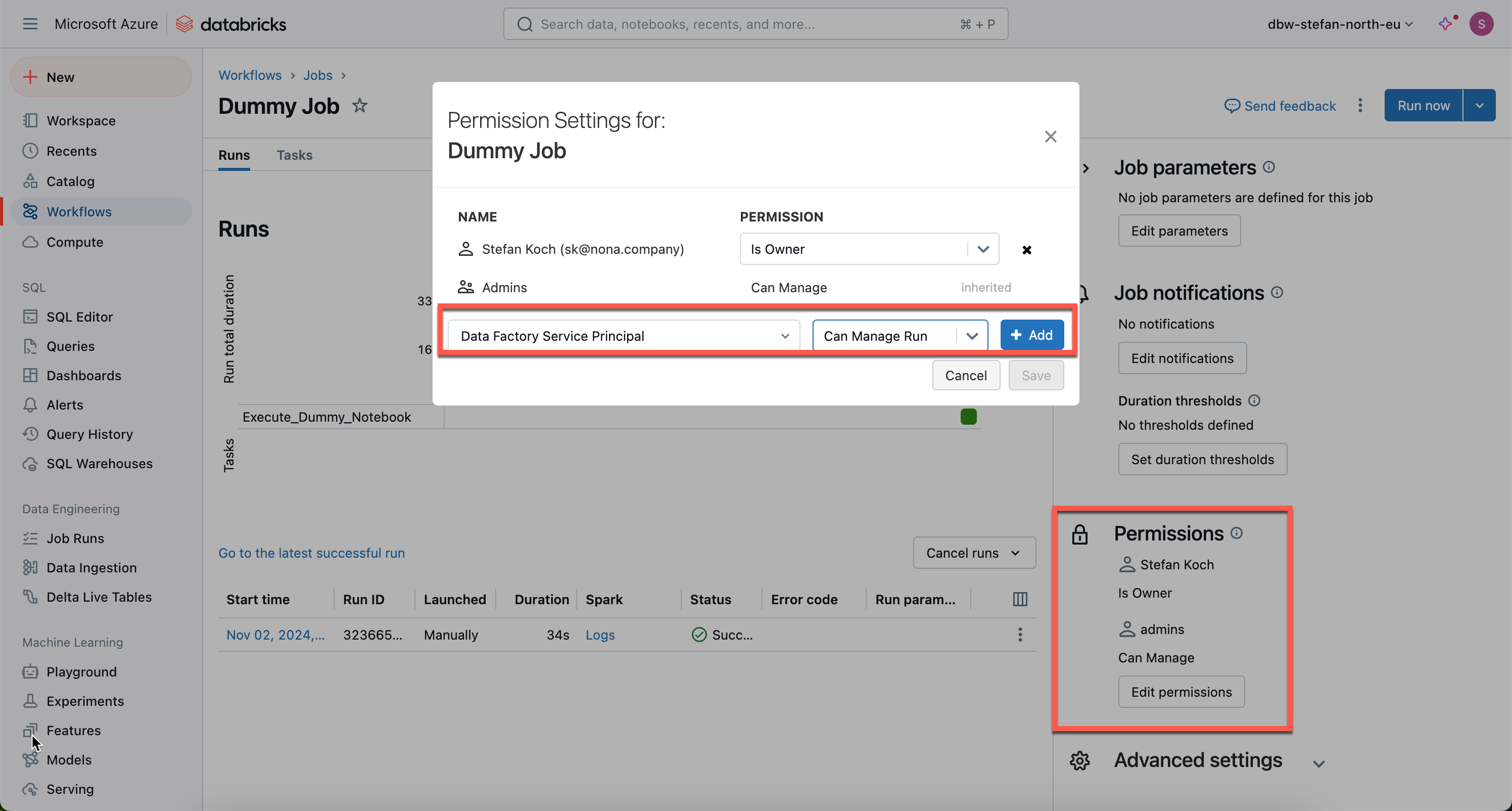
Now I have to authorize the Service Principal to the job so that he is able to start the job at all.
Customizing the ADF pipeline
In the Data Factory, I now need to customize the pipeline. I add an additional task, a web activity.
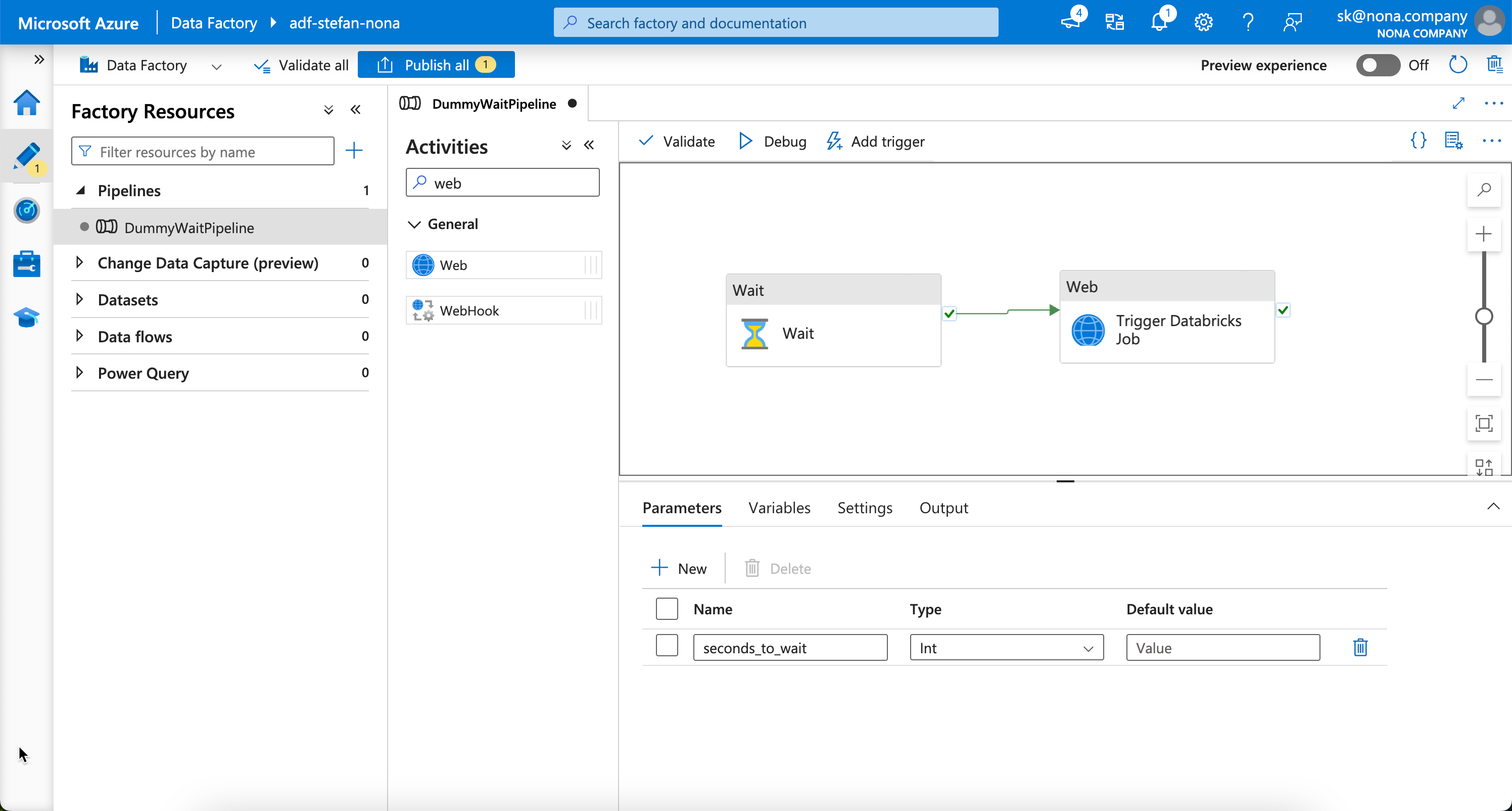
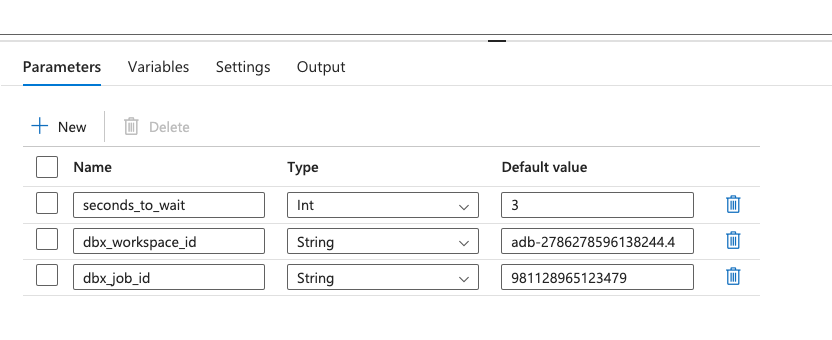
In the pipeline parameters I add 2 additional parameters:
- dbx_workspace_id: The ID of the Databricks workspace.
- dbx_job_id: The ID of the Databricks job that I want to trigger from ADF.
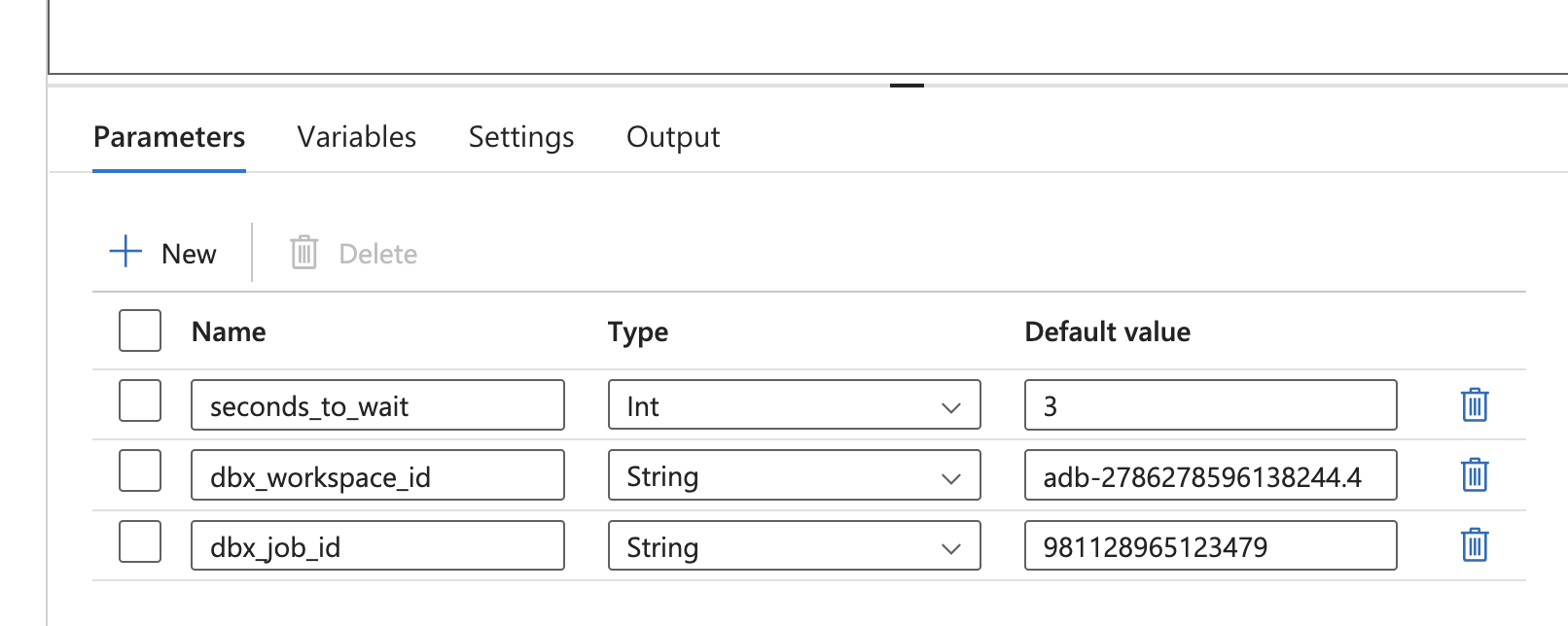
I can read the Databricks Workspace ID from the URL.

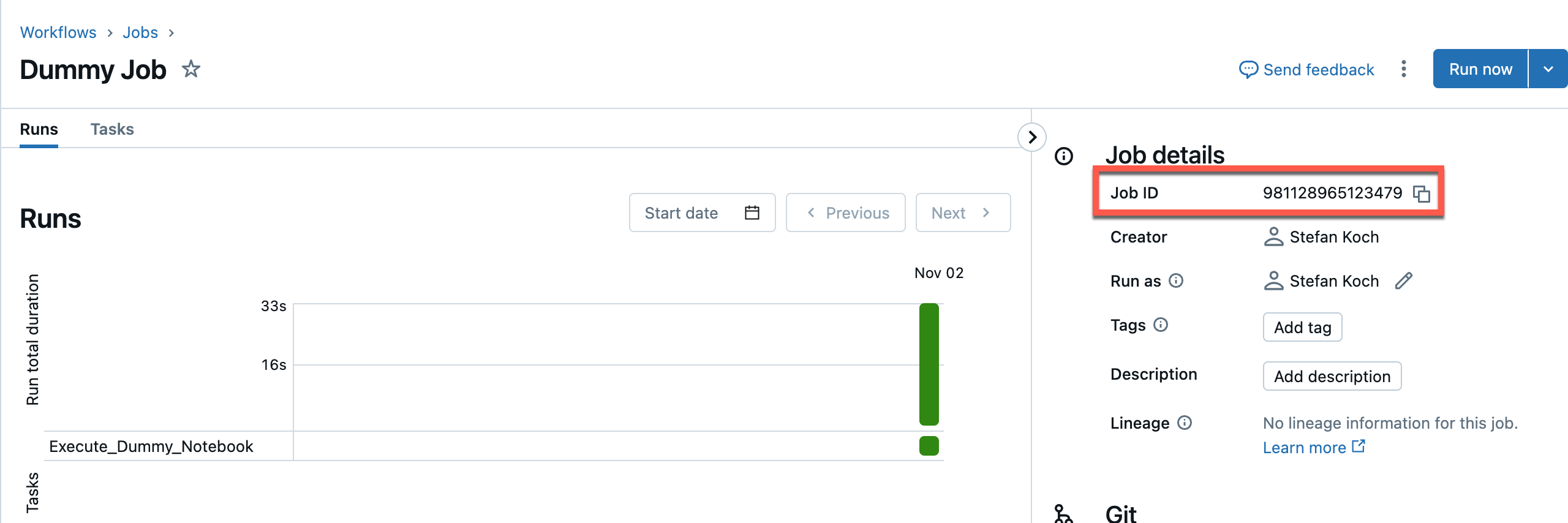
I can see the job ID when I open the Databricks job.
Now I configure the web activity.
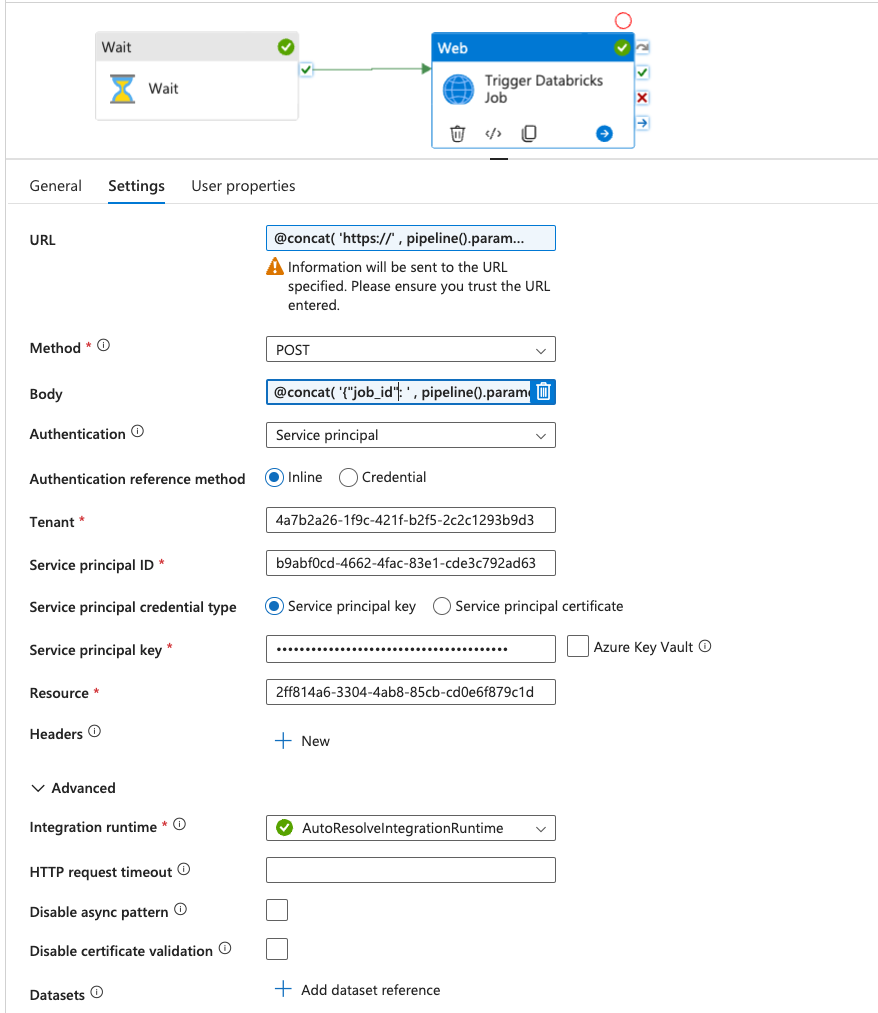
I make the URL dynamic so that I can address any Databricks workspaces. The content looks like this:
|
|
I also make the body of the REST call dynamic. There I enter the Databricks job ID, dbx_run_id and adf_run_id as parameters. The job ID is intended for Databricks to know which job is to be executed, the other two parameters are notebook parameters. The pipeline expression builder in the Data Factory takes a bit of getting used to. That is, it is not exactly user-friendly to build an expression. I have gotten into the habit of writing all subsctrings that are to be combined in a new line for concat methods. The content of the body then looks like this:
|
|
During authentication, I select the service principal and enter the relevant information:
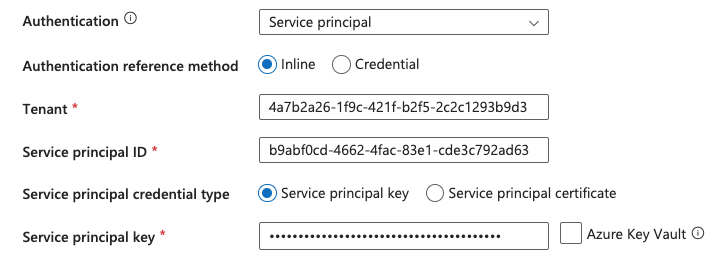
You could now integrate the KeyVault as a linked service in ADF and then link the secret from there. This certainly makes sense in productive environments. For the sake of simplicity, I will omit this in my example.
I enter the following hard-coded ID for the resource:
|
|
The Azure resource ID 2ff814a6-3304-4ab8-85cb-cd0e6f879c1d refers to the Databricks API resource in Entra. This ID is the unique application ID for Databricks and is used when a service principal or user identity in Azure accesses Databricks via the API.
I will now run a first test by starting the pipeline in debug mode. And it runs successfully.
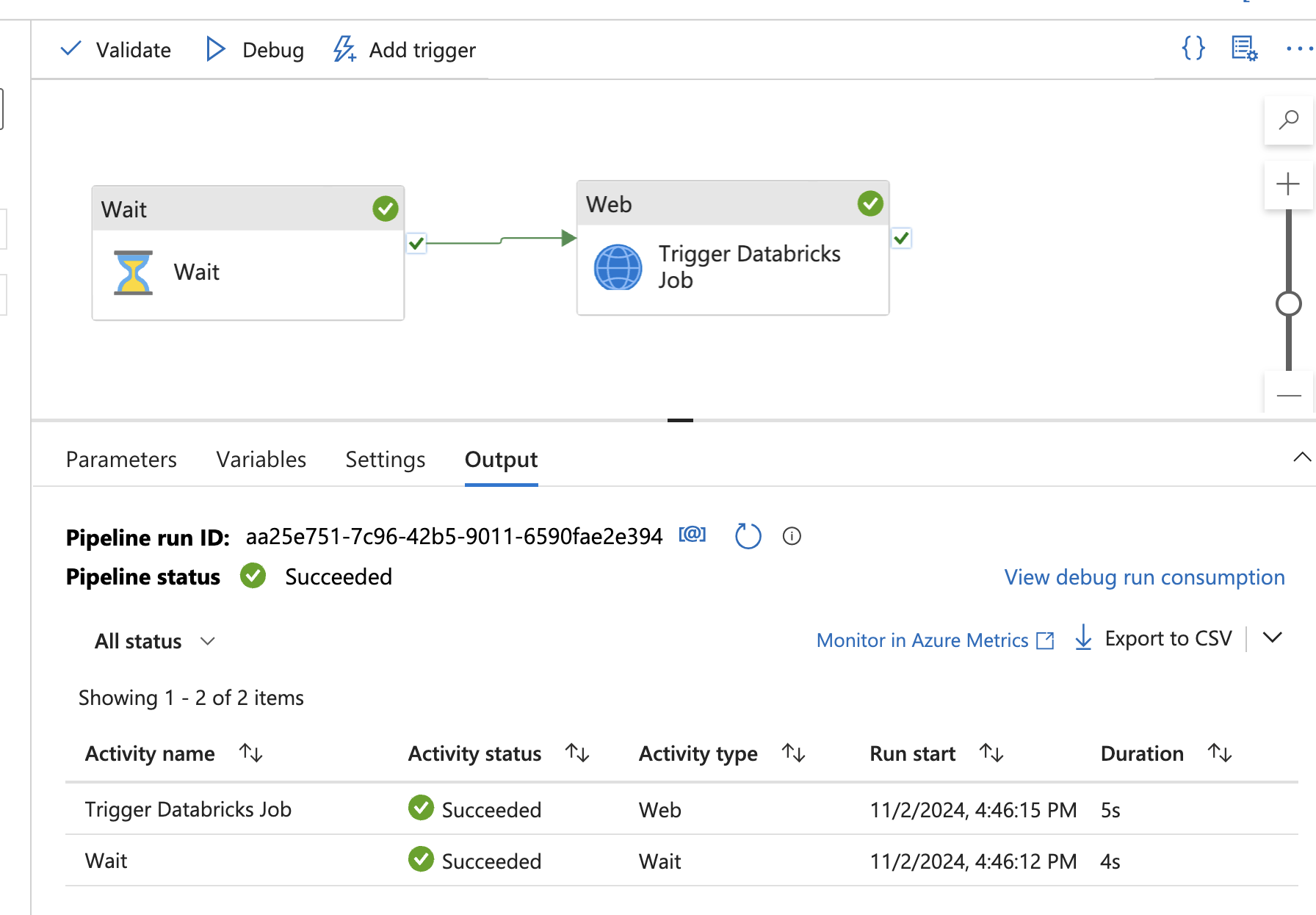
In Databrick’s workflows, I can also see that the job has run successfully.
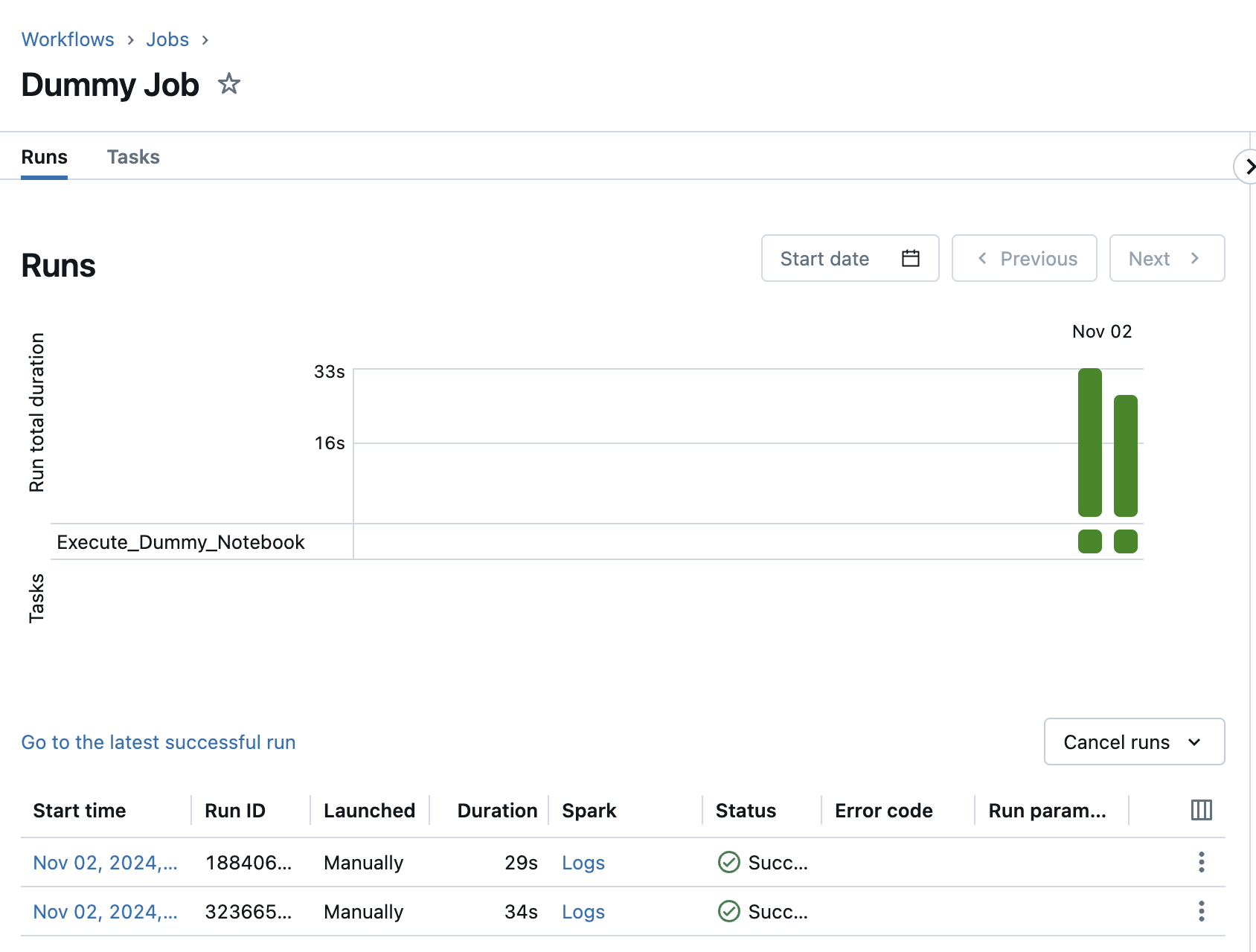
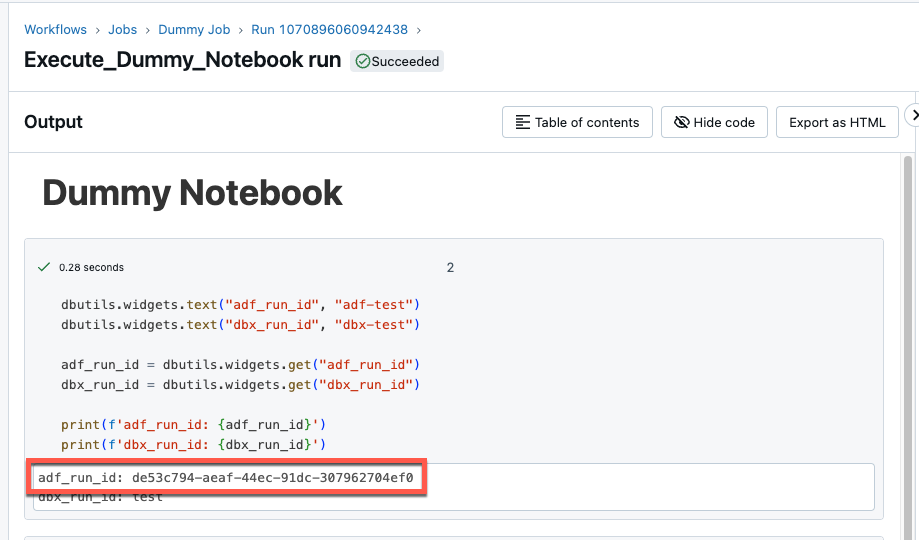
And then I take a look at the notebook that was executed by this dummy job. There I can also see the run ID of the ADF.
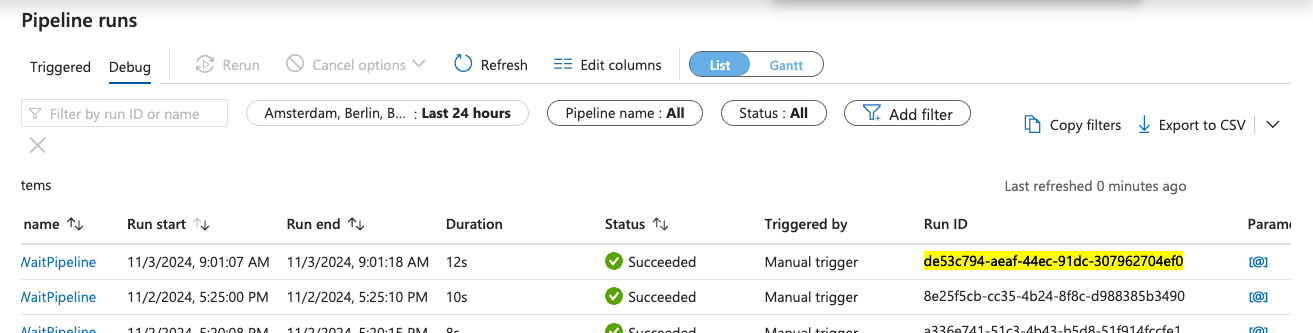
This matches the corresponding information in ADF.
Complete example pipeline
Now I would like to combine the individual steps into an overall picture. I would like to implement the following logic:
- start a Databricks job
- the Databricks job triggers an ADF job
- When called, the Run ID is retrieved from the Data Factory job
- The job writes its own Run ID and that of the ADF to a delta table
- the ADF pipeline is started
- The ADF pipeline executes its intended tasks
- At the end of the pipeline, a web activity is started, which starts a Databricks job
- When the Databricks follow-up job is triggered, the current run ID of the ADF pipeline is transferred
- the Databricks follow-up job is started.
- The run ID of the Databricks follow-up job is written to the delta table
- The status of the ADF job is retrieved using a function and written to the delta table
With this mechanism, the ADF jobs and the Databricks jobs can be linked and monitored.
For this purpose, I have created a rudimentary delta table and assigned the corresponding authorizations to the service principal.
|
|
I also need to extend the notebook for triggering the ADF job. I create two additional widgets, one that receives the Databricks Run ID from the start job and a second that receives the Delta Table.
|
|
I have written a simple function so that the data can be written to the delta table.
|
|
And then added this function when triggering the ADF.
|
|
Now I’ll adjust the ADF job accordingly. I’ve noticed that I don’t need to pass the Databricks Run ID if I write it to the Delta Table, so I’ll remove it.
I also adapt the body of the web activity accordingly and remove these parameters so that it looks like the following:
|
|
I now adapt the follow-up job in databricks so that the current run ID of the job is transferred to the notebook in the parameter dbx_run_id. I can do this by entering the following string in the value: {{job.run_id}}
It will look like this

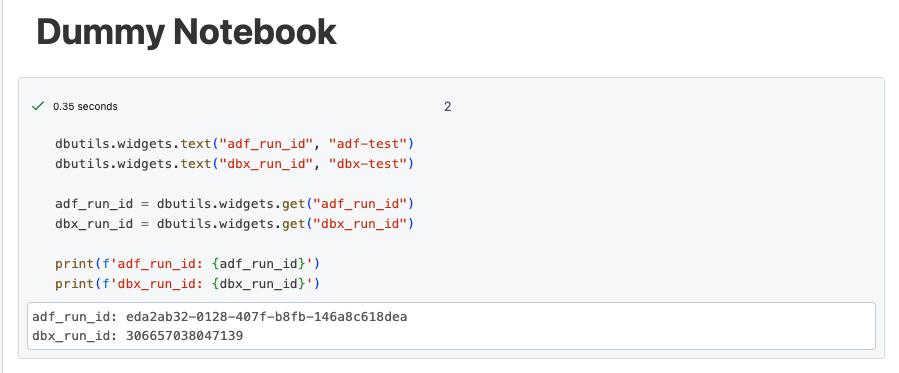
If I now start the job to trigger the ADF, the ADF pipeline is executed, this starts the dummy job at the end and this then outputs the Run IDs.
Now I’m going to write a function there that writes this information to the Delta Table. The name Dummy for the job and the notebook is no longer quite appropriate, so I’ll rename it Follow Job. The function is no longer an INSERT, but an update. As the Run ID from the Data Factory is already in the table, I will insert the status from the ADF job and the Run ID from the Databricks Follow Job accordingly. The function for the update then looks like this:
|
|
Now I start a final test. I go to my initial job in Databricks Workflows and start the pipeline. The dbx_start_run_id and the adf_run_id are written to the delta table.
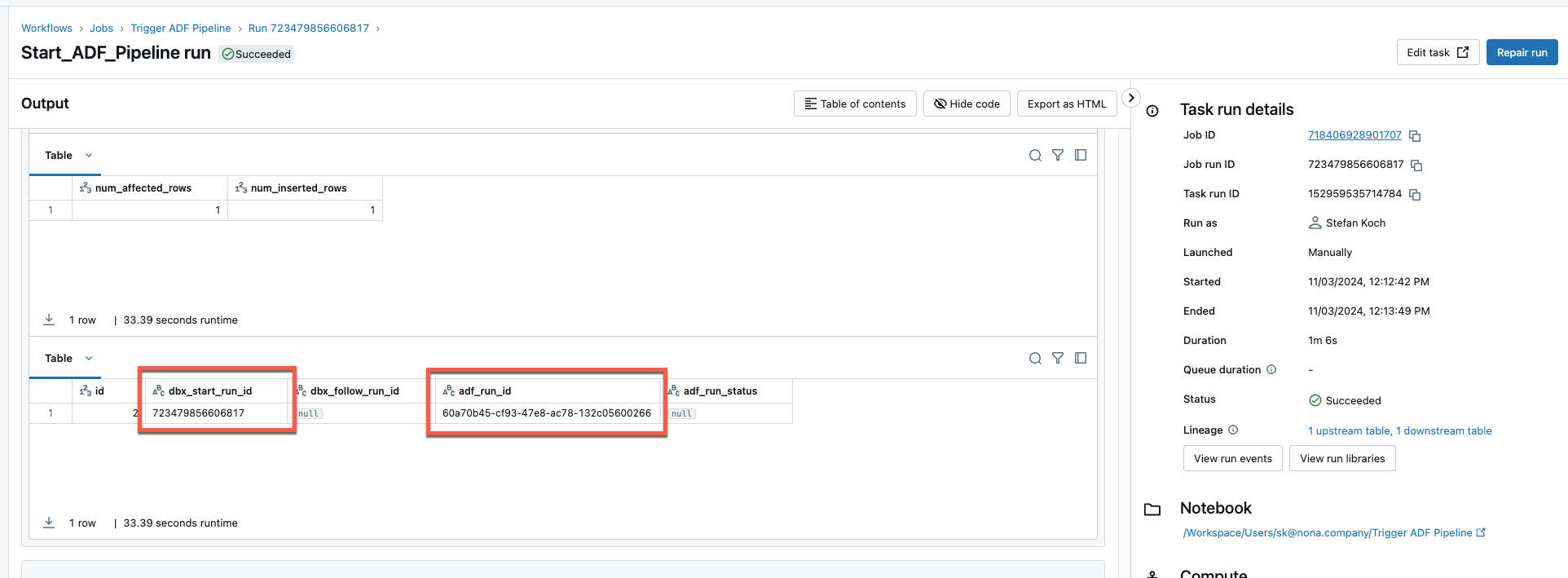
The corresponding pipeline was started in the Data Factory.
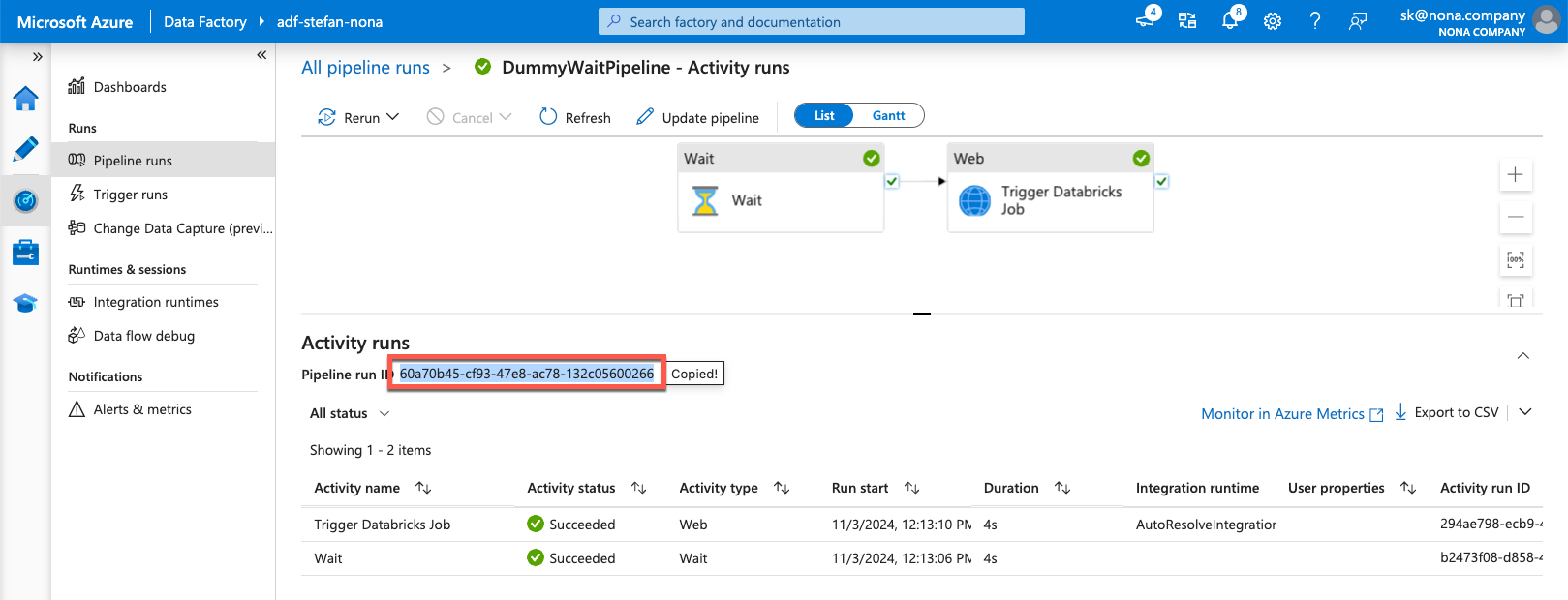
This in turn started the follow job in Databricks, which then wrote the missing information to the delta table.
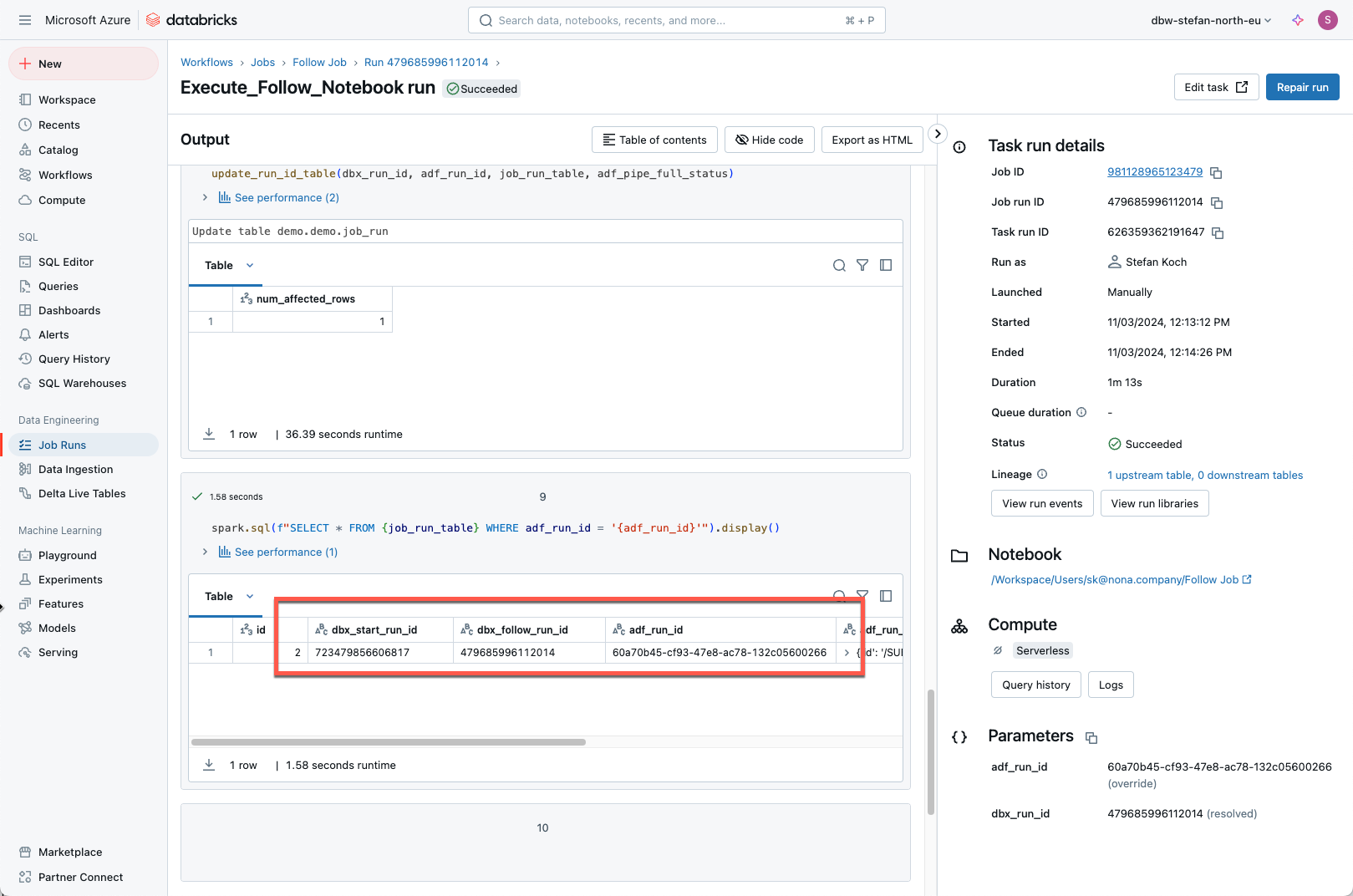
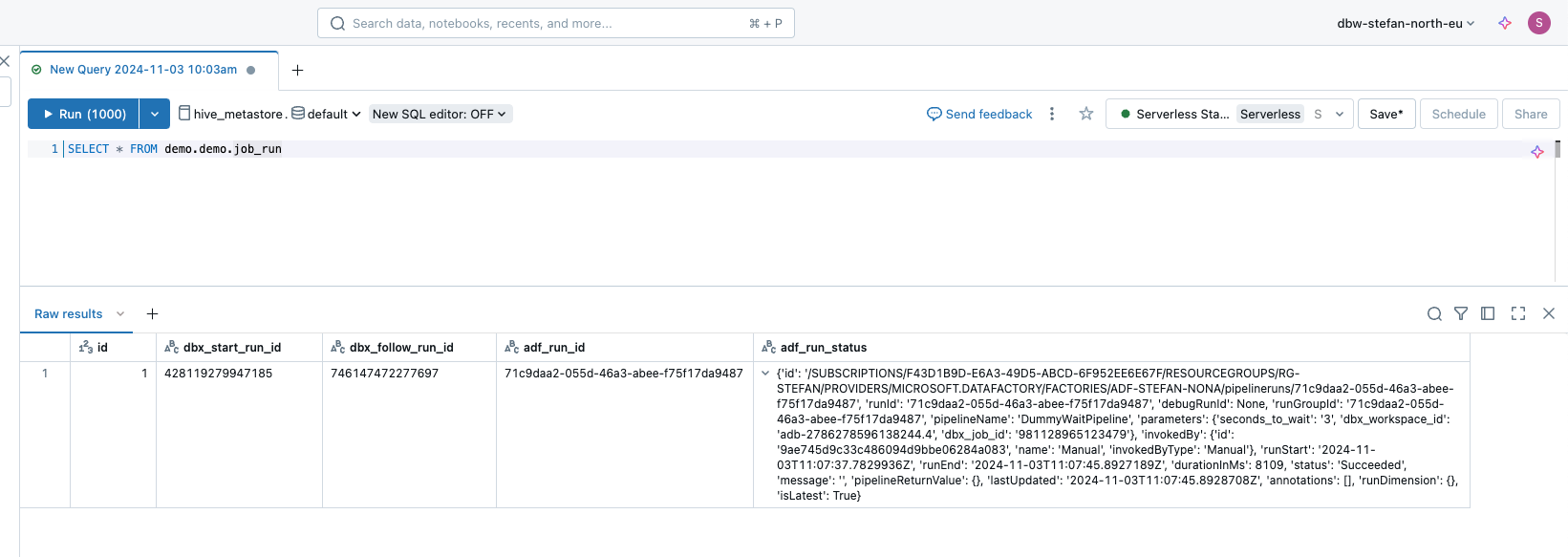
Now the runs from the Data Factory and Databricks can be brought into relation by querying the Delta Table.
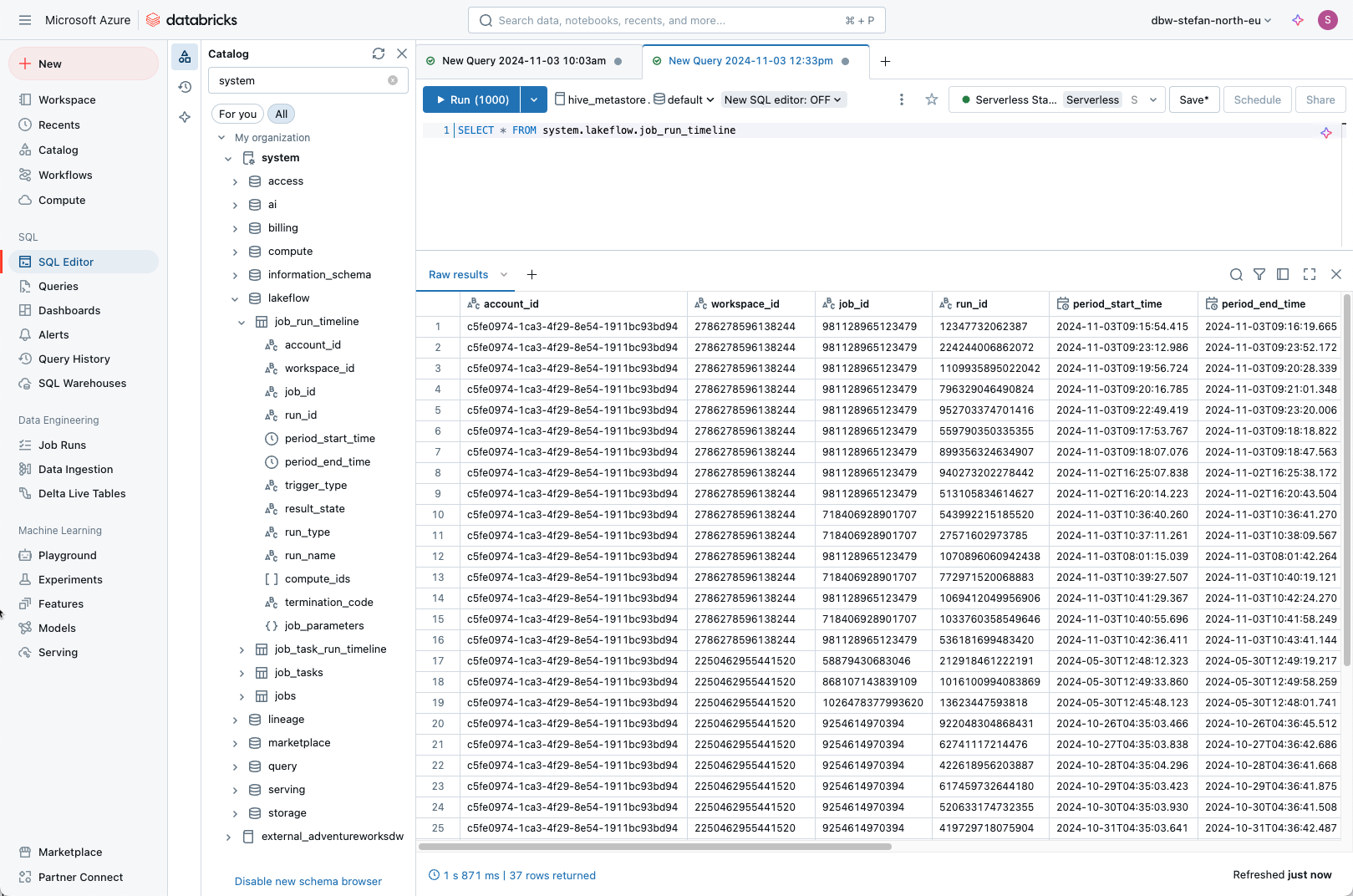
In addition, this delta table could be joined with the system table of databricks, in which the runs of databricks are located.
Conclusion
Using REST queries, it is easy to start Data Factory jobs from Databricks workflows and vice versa. With these methods, you have a lot of freedom to set up central orchestration and monitoring in Databricks.
In each of my examples, I have used an Azure Service Principal (aka App Registration). Of course, you could also use a Managed Identity to authenticate yourself in Databricks or Data Factory.
The setup works best with serverless clusters. This is because the Databricks job that starts the ADF job only takes a few seconds. So it makes no sense to use a classic cluster.
The code examples used are examples. This means that they were created for illustrative purposes and should of course be improved accordingly if you want to use them in production. The processes should also be adapted to your own environment. The artifacts created should only serve as input.
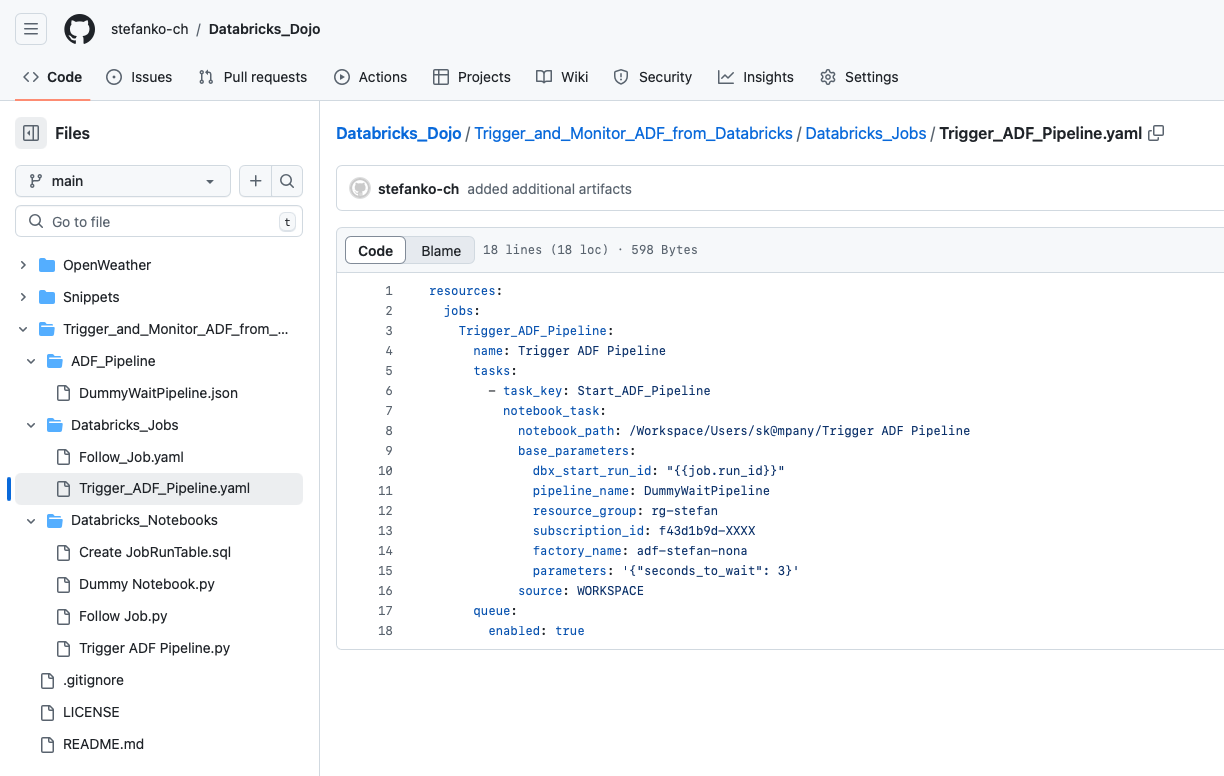
I provide the created artifacts on the following Github repo: https://github.com/stefanko-ch/Databricks_Dojo/tree/main/Trigger_and_Monitor_ADF_from_Databricks
I take no responsibility for the content and accuracy of the code. It is what it is and you are welcome to customize it. In addition to the notebooks created, I also provide the definitions of the Databricks jobs and the ADF pipeline.
I am happy to receive questions, tips or comments. 😊