How To: Copying all schemas and tables from one catalog to another catalog in Databricks
In this quick guide, I will show you how to automatically copy all schemas and tables from one catalog to another in Databricks.
Contents
Initial situation
I have set up a sample environment in Azure for my students in which they can practice with the sample databases from Microsoft. The sample databases are stored in different Azure SQL databases. There are 4 databases in total:
- AdventureWorks
- AdventureWorksDW
- WideWorldImporters
- WideWorldImportersDW

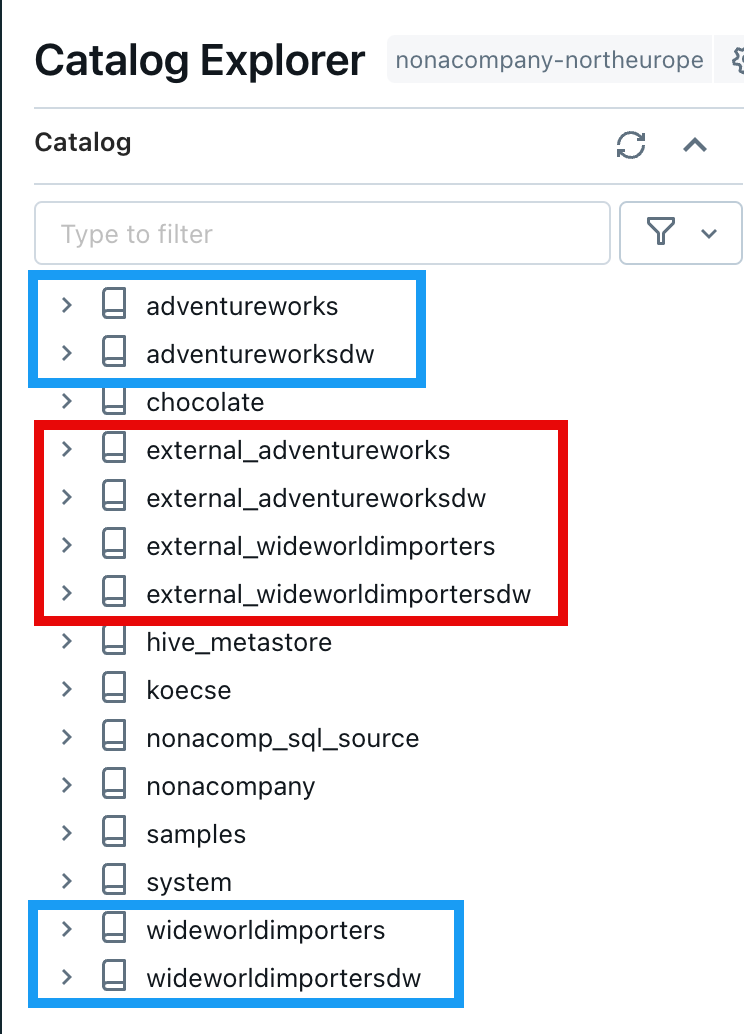
Each of these databases has several tables and schemas. As can be seen from the following illustration, there are quite a few:
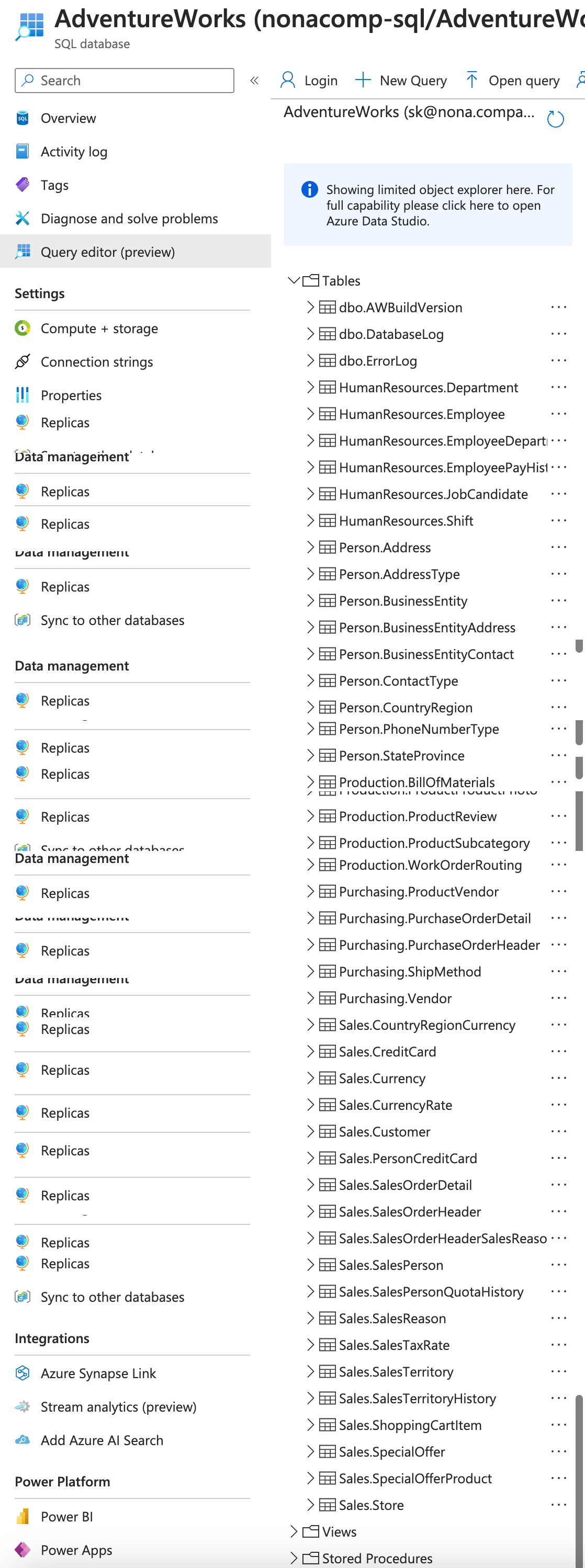
Now I wanted to make the data from the SQL databases available in Databricks as well.
Copying all the tables and schemas manually would have been very cumbersome and would have cost me a lot of time. That’s why I decided to automate the whole thing.
Integration of the Azure SQL database via Lakehouse Federation
Of course I could access the databases directly from Databricks, e.g. with a JDBC connection.
Another way is to integrate the databases into the Unity Catalog as an external source via Lakehouse Federation. More information about Lakehouse Federation can be found here: https://docs.databricks.com/en/query-federation/index.html
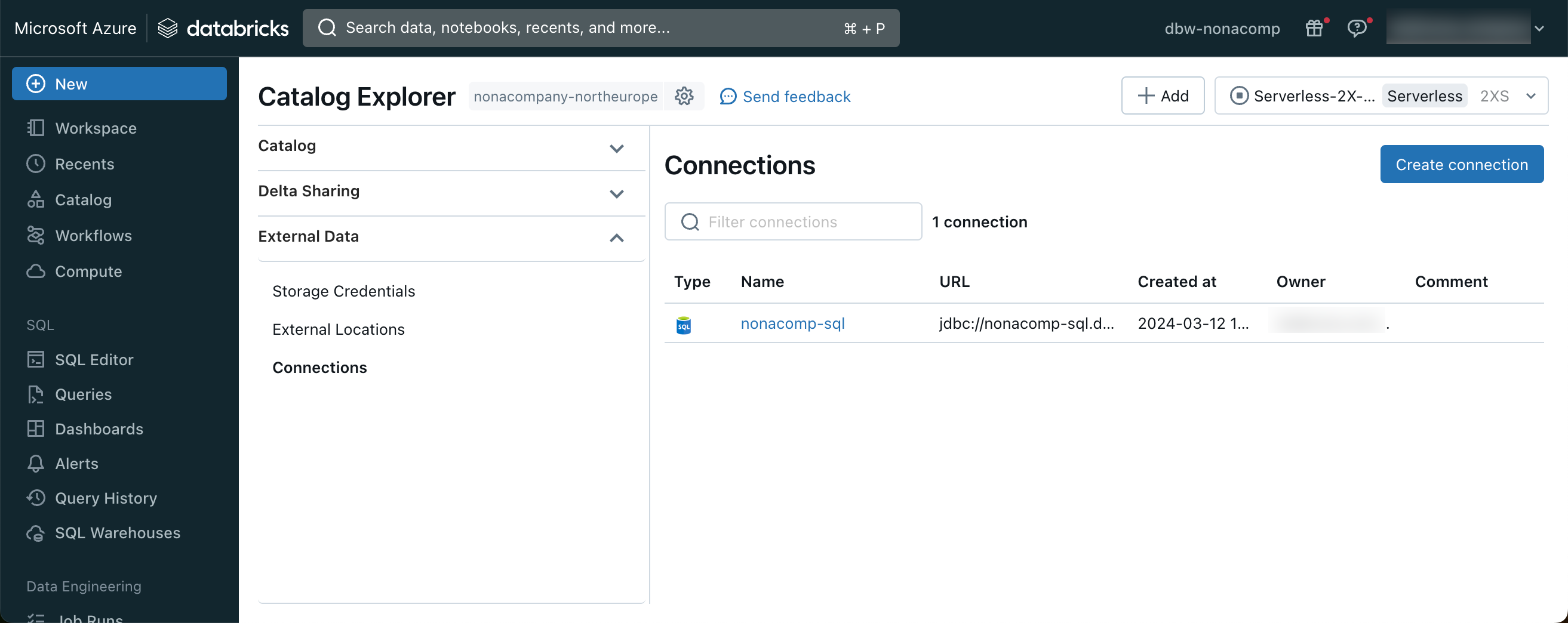
So I have registered the Azure SQL Server as an external connection in Unity Catalog.
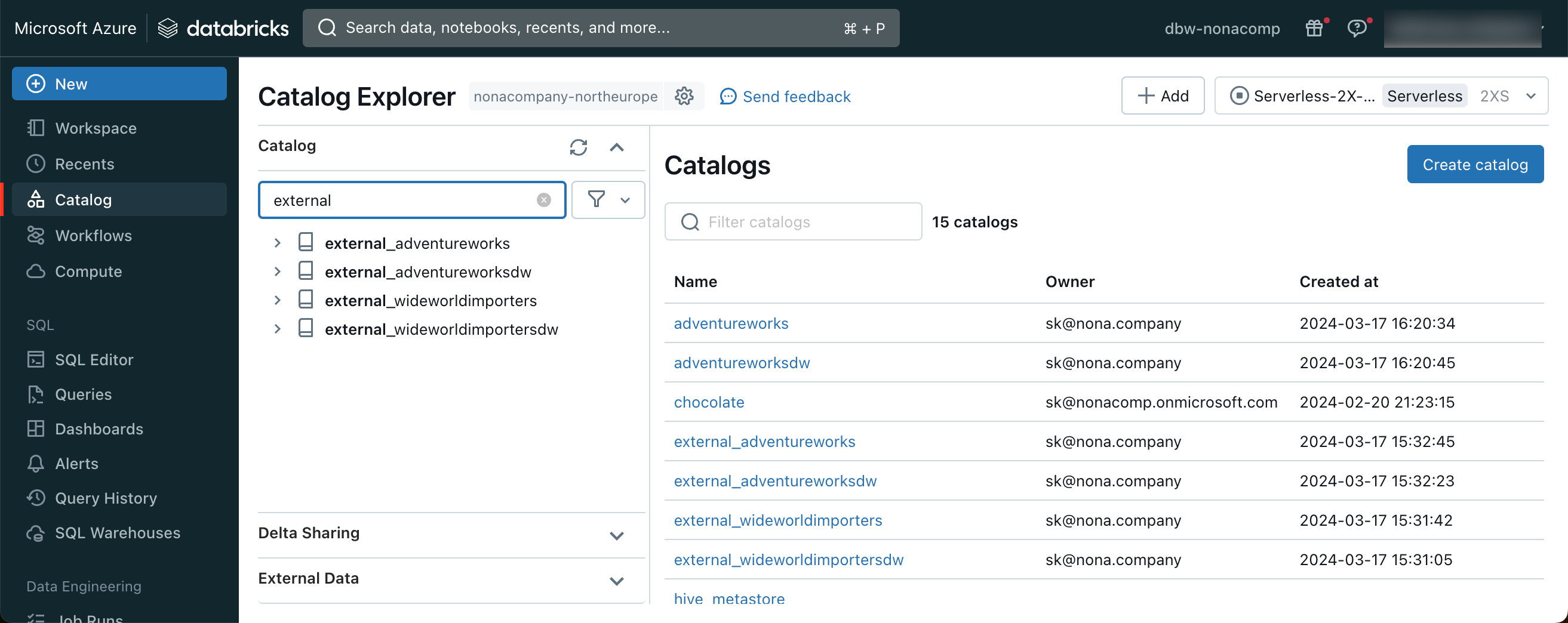
I then created a catalog for each of the respective databases from this connection. So that they were immediately recognizable as such, I prefixed them with “external_”.
With this setup, you can address the external source directly within Databricks Lakehouse. For example, I have queried the person.person table from the AdventureWorks DB.
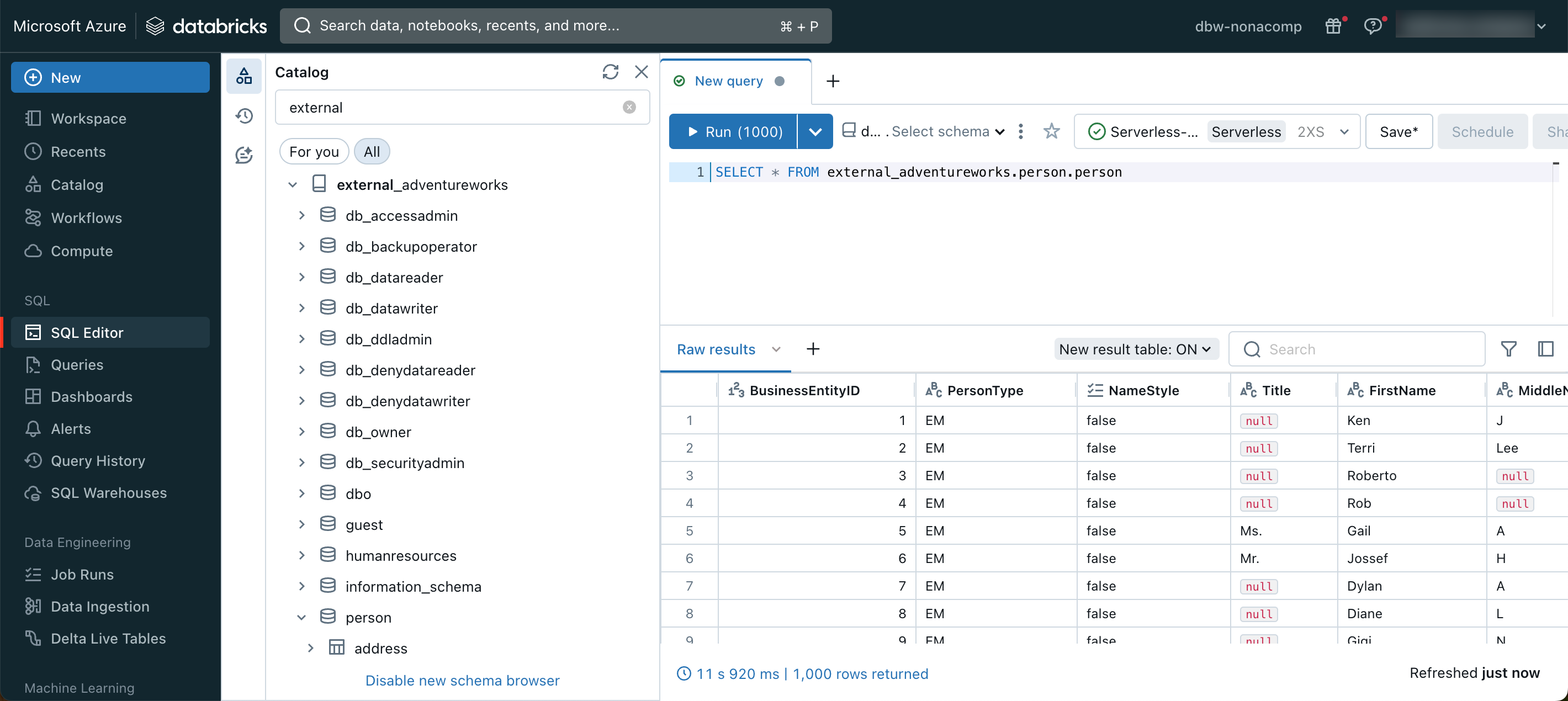
Within Unity Catalog, I created 4 empty catalogs, one catalog for each source DB. Below you can see the sources outlined in red and the target catalog outlined in blue:
Notebook for automatic copying
I now created an empty notebook in the Databricks workspace.
The notebook should have a dynamic structure. I have therefore added 2 widgets, one for the name of the source catalog, the other for the target catalog.
dbutils.widgets.text("source_catalog", "")
dbutils.widgets.text("target_catalog", "")I fill the content from the widgets into two variables each.
source_catalog = dbutils.widgets.get("source_catalog")
target_catalog = dbutils.widgets.get("target_catalog")So that I can iterate over all source tables, I read them from the information schema of the source and save the tables in a dataframe.
df_tables = spark.read.table(f"{source_catalog}.information_schema.tables")When I display this dataframe, I get the following output:
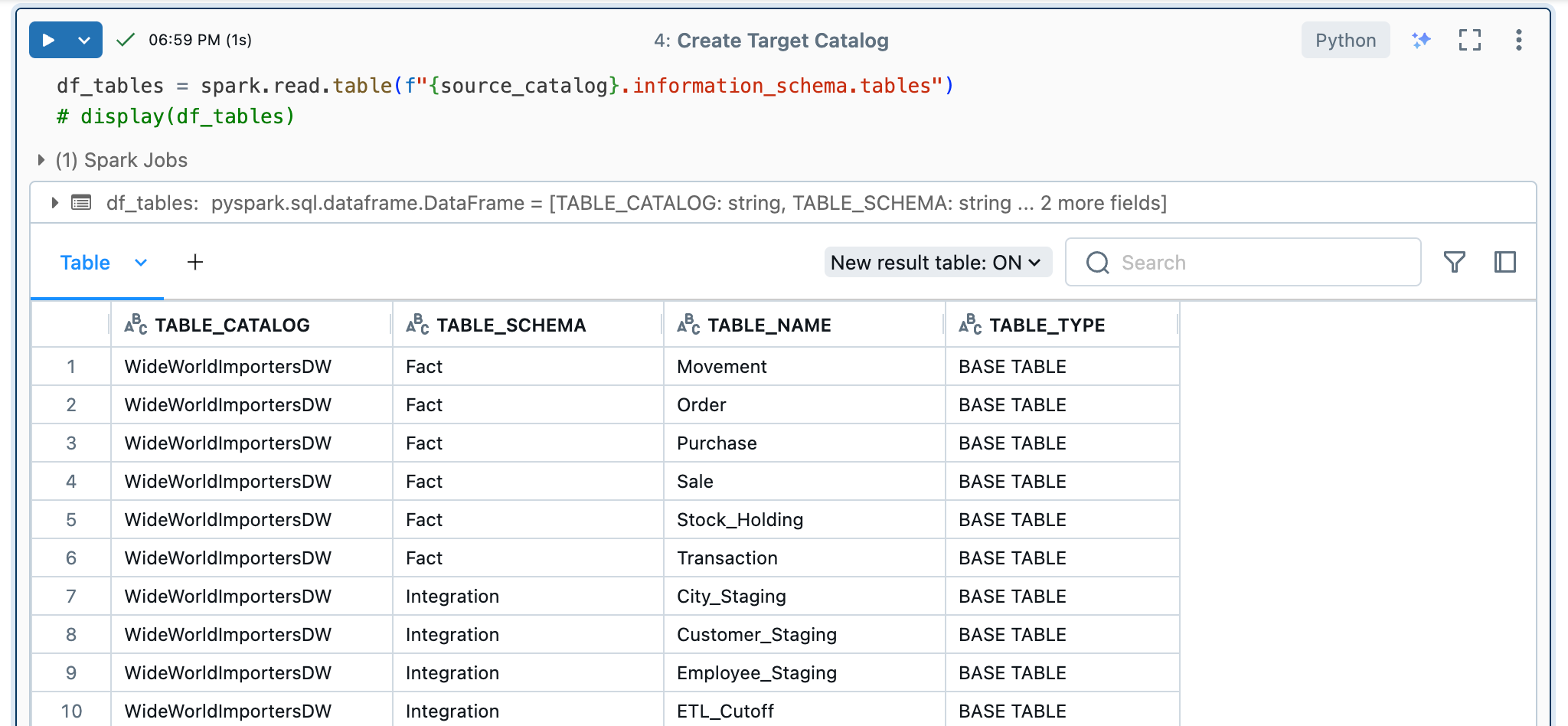
Next, I wrote a function that I can call in a for loop for each individual table. To do this, the source catalog, target catalog, schema and table name must be passed. In the function itself, the schema is first created if it does not exist and then the new table is created with a “CREATE TABLE AS SELECT” statement.

Before I looped over all tables, I tested this on one table:

And checked the contents of the target table.

So far so good, I thought. So I packed the script into a loop. Using Panda’s iterrows, I iterated over each row in the table dataframe. Within the for loop, I then called the copy_table function.
for index, row in df_tables.toPandas().iterrows():
schema = row[1]
table = row[2]
copy_table(source_catalog, target_catalog, schema, table)Unfortunately, there were problems with certain column names and the function returned an error.
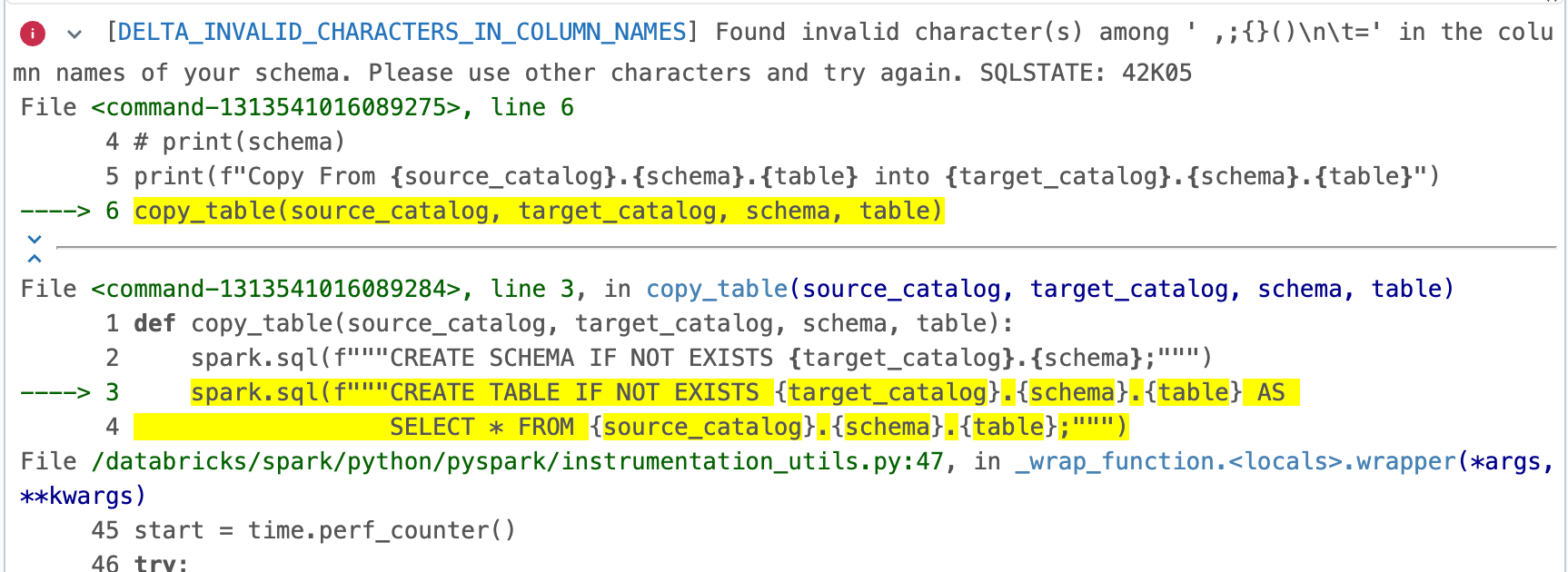
It turned out that Microsoft uses column names with spaces in its sample databases.

I have now rewritten the function accordingly so that the spaces in the column names have been replaced with a “_”. The function then looked like this:
def copy_table(source_catalog, target_catalog, schema, table):
spark.sql(f"""CREATE SCHEMA IF NOT EXISTS {target_catalog}.{schema};""")
if spark.catalog.tableExists(f"{target_catalog}.{schema}.{table}"):
print(f"Skip table {target_catalog}.{schema}.{table}, because the table already exists.")
else:
print(f"Copy from {source_catalog}.{schema}.{table} into {target_catalog}.{schema}.{table}.")
source_df = spark.table(f"{source_catalog}.{schema}.{table}")
renamed_cols = [col.replace(" ", "_") for col in source_df.columns]
renamed_df = source_df.toDF(*renamed_cols)
renamed_df.write.mode("overwrite").saveAsTable(f"{target_catalog}.{schema}.{table}")
I also skipped tables that had already been copied with an if statement. The whole process for a database only took a few minutes.

I was able to use this notebook to copy all 4 databases from the Azure SQL source into my Lakehouse within a very short time.
Source-Code
You can find the notebook I wrote in my public Git repo: https://github.com/stefanko-ch/Databricks_Dojo/blob/main/Snippets/Copy_all_tables_and_schemas_into_new_catalog.py