How To: Kopieren von allen Schemas und Tabellen von einem Catalog in einen anderen Catalog in Databricks
In dieser Kurzanleitung zeige ich, wie man in Databricks alle Schemas und Tabellen automatisch von einem Catalog in einen anderen Catalog kopieren kann.
Contents
Ausgangslage
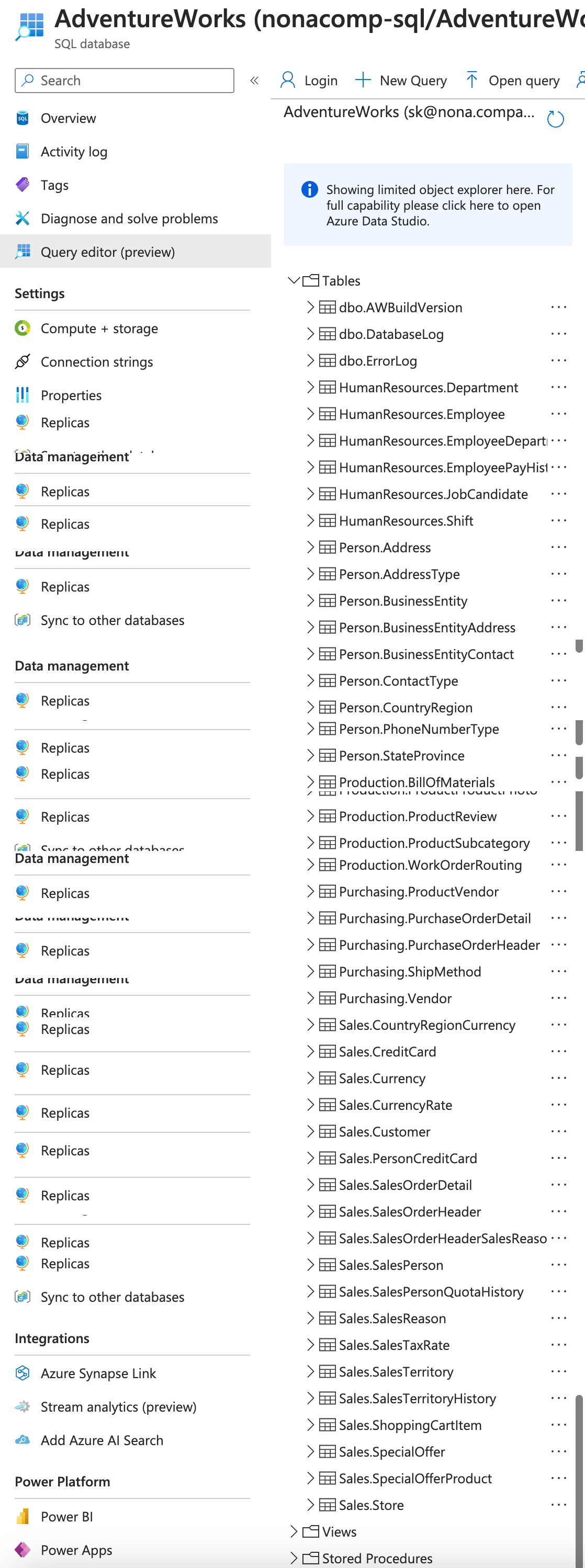
Ich habe für meine Studenten eine Beispiel-Umgebung in Azure eingerichtet, in welcher sie mit den Beispiel-Datenbanken von Microsoft üben können. Die Beispieldatenbanken sind in verschiedenen Azure SQL-Datenbanken gespeichert. Insgesamt handelt es sich um 4 Datenbanken:
- AdventureWorks
- AdventureWorksDW
- WideWorldImporters
- WideWorldImportersDW

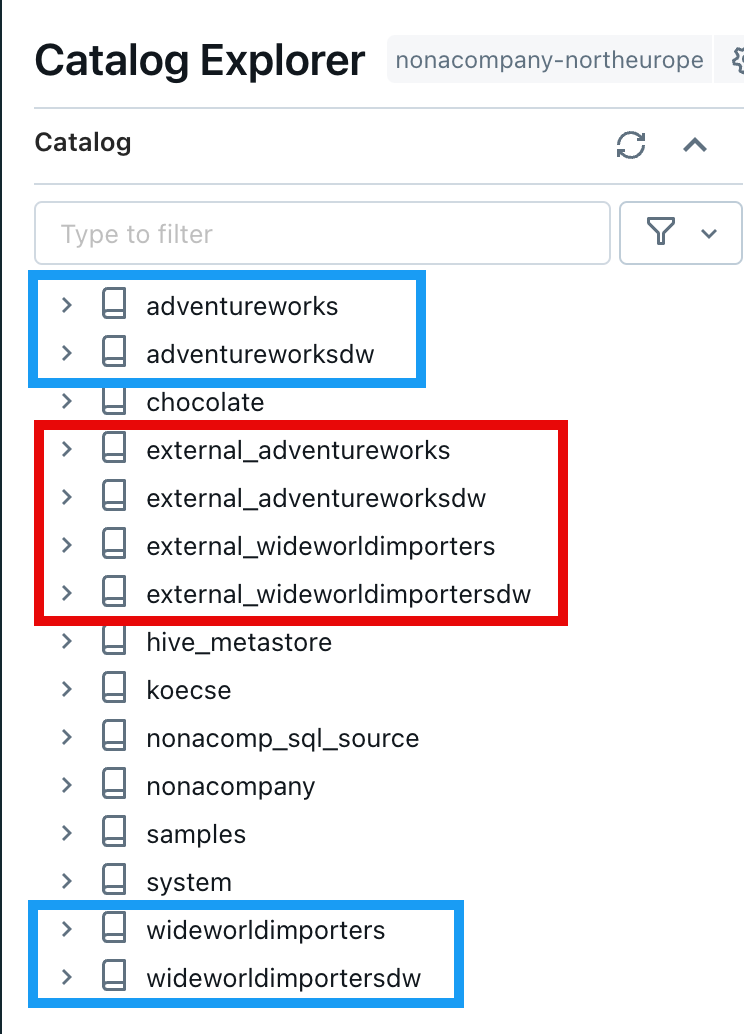
Jede diese Datenbanken hat mehrere Tabellen und Schemas. Wie aus der nachfolgenden Abbildung zu erkennen ist, sind das doch einige:
Nun wollte ich die Daten der SQL-Datenbanken ebenfalls in Databricks zur Verfügung stellen.
Alle Tabellen und Schemas manuell zu kopieren wäre sehr umständlich gewesen und hätte mich viel Zeit gekostet. Darum entschied ich mich, das ganze zu automatisieren.
Einbinden der Azure SQL Datenbank via Lakehouse Federation
Natürlich könnte ich die Datenbanken direkt aus Databricks ansprechen, z.B. mit einer JDBC Verbindung.
Ein anderer Weg ist, die Datenbanken via Lakehouse Federation als externe Quelle in den Unity Catalog einzubinden. Nähere Informationen zu Lakehouse Federation findet man hier: https://docs.databricks.com/en/query-federation/index.html
Ich habe also den Azure SQL Server als externe Verbindung in Unity Catalog registriert.
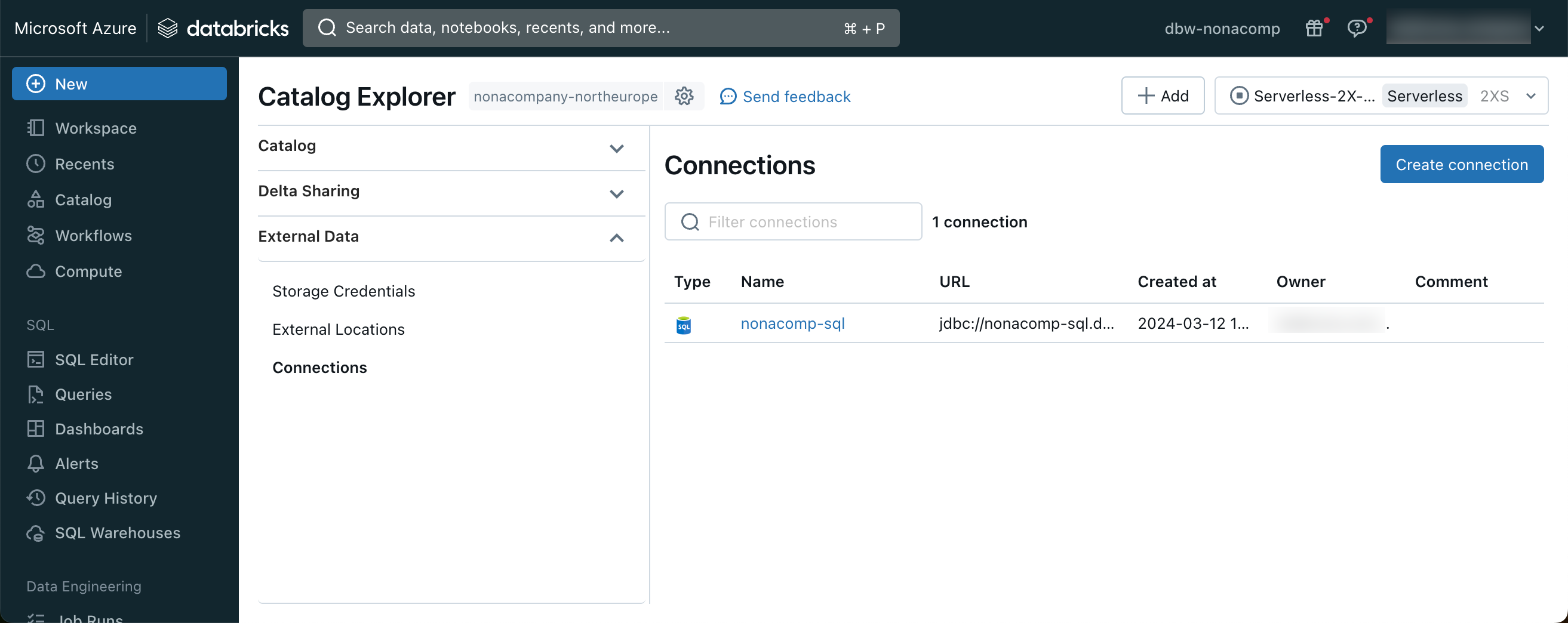
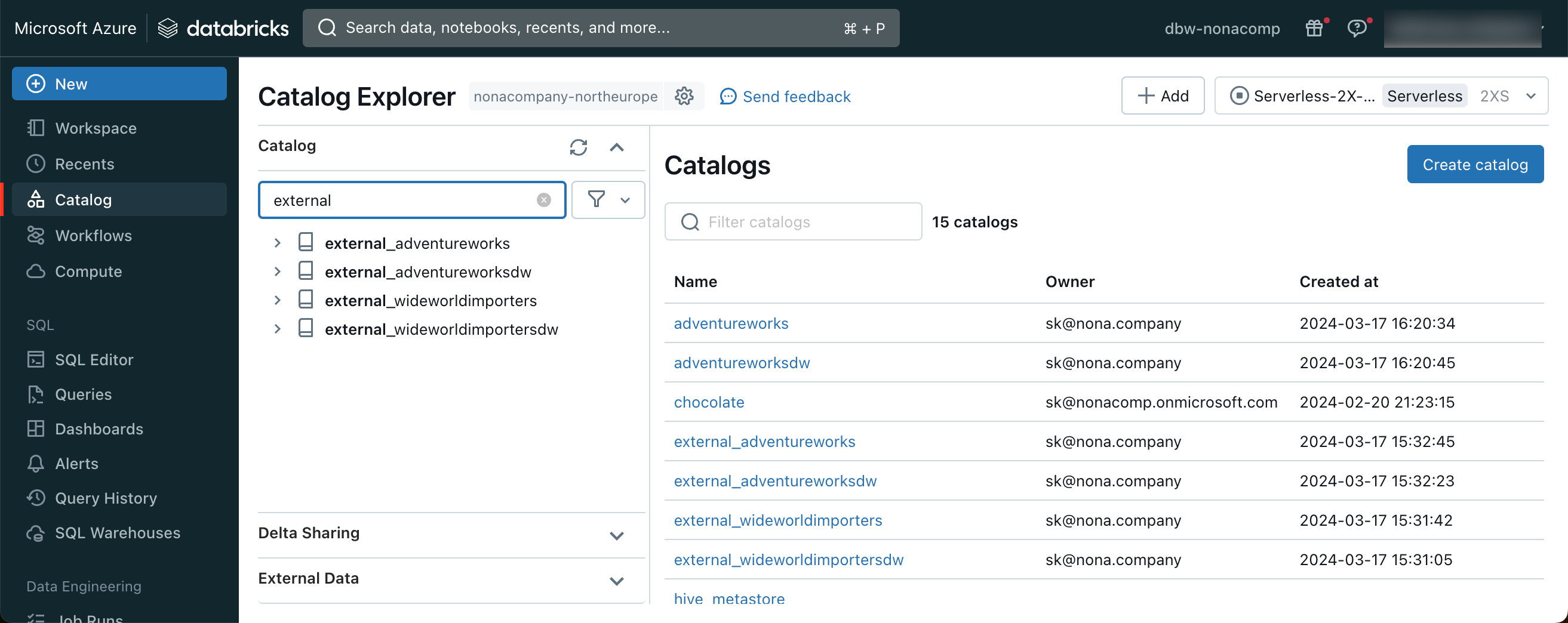
Anschliessend habe ich von dieser Connection aus den jeweiligen Datenbanken je einen Catalog erstellt. Damit sie gleich als solches erkennbar waren, habe ich den Präfix “external_” vorangestellt.
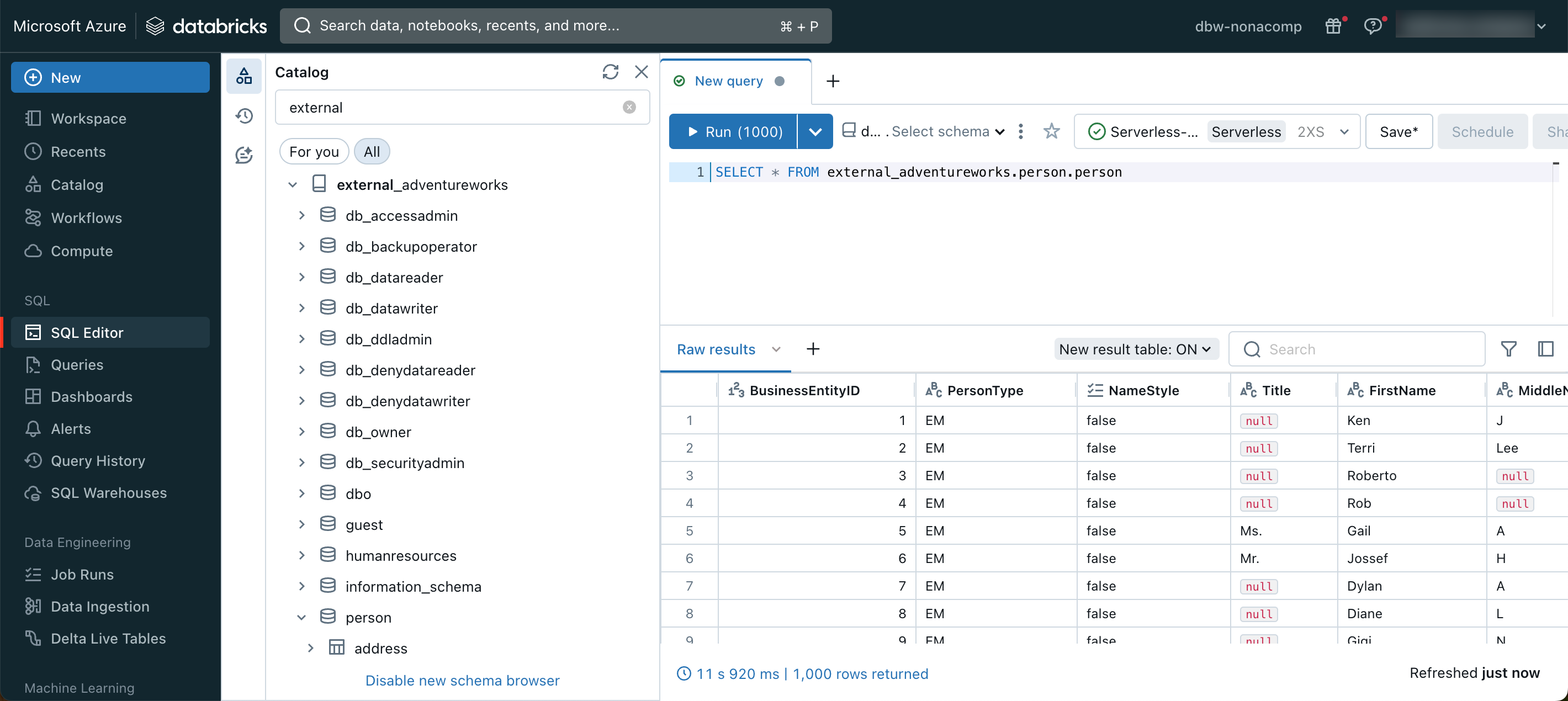
Mit diesem Setup kann man innerhalb vom Databricks Lakehouse die externe Quelle direkt ansprechen. Zum Beispiel habe ich mal die Tabelle person.person von der AdventureWorks-DB abgefragt.
Innerhalb von Unity Catalog habe ich gleich mal 4 leere Cataloge erstellt, für jede Quell-DB einen Catalog. Nachfolgend sieht man die Quellen rot umrandet und die Ziel-Catalog blau umrandet:
Notebook für das automatische kopieren
Ich erstellte nun ein leeres Notebook im Databricks Workspace.
Das Notebook soll dynamisch aufgebaut sein. Darum habe ich mal 2 Widgets hinzugefügt, eines dient für den Namen des Quell-Catalogs, das andere für den Ziel-Catalog.
dbutils.widgets.text("source_catalog", "")
dbutils.widgets.text("target_catalog", "")Den Inhalt aus den Widgets fülle ich in je zwei Variabeln ab.
source_catalog = dbutils.widgets.get("source_catalog")
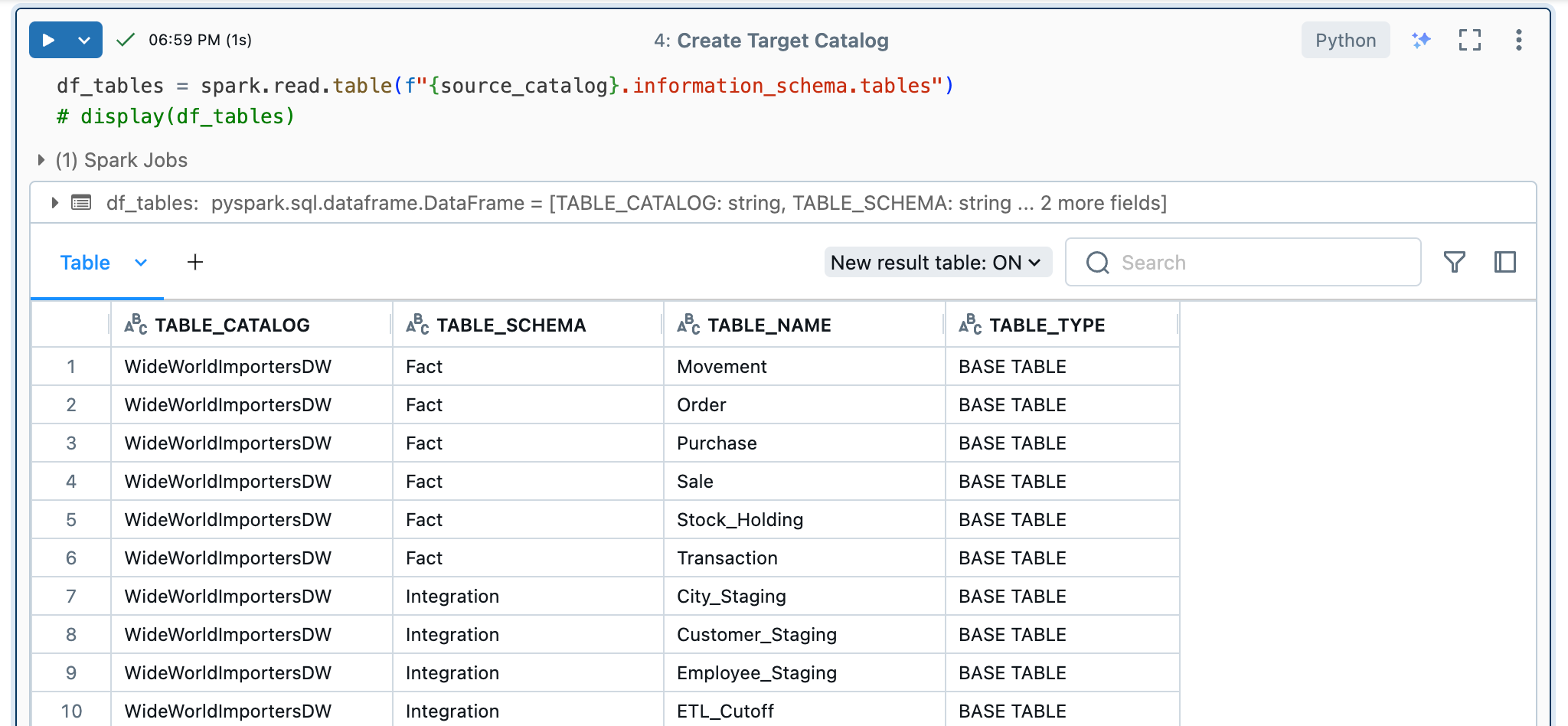
target_catalog = dbutils.widgets.get("target_catalog")Damit ich über alle Quell-Tabellen iterieren kann, lese ich diese aus dem Information-Schema der Quelle aus und speichere die Tabellen in einem Dataframe.
df_tables = spark.read.table(f"{source_catalog}.information_schema.tables")Wenn ich dieses Dataframe anzeige, erhalte ich folgende Ausgabe:
Als nächstes habe ich eine Funktion geschrieben, welche ich in einem For-Loop aufrufen kann für jede einzelne Tabelle. Dazu muss jeweils die Angaben zum Quell-Catalog, Ziel-Catalog, das Schema und der Tabellenname übergeben werden. In der Funktion selber wird dann zuerst das Schema erstellt, falls es nicht vorhanden ist und anschliessend die neue Tabelle mit einem “CREATE TABLE AS SELECT”-Statement erstellt.

Bevor ich über alle Tabellen geloopt bin, habe ich das mal an einer Tabelle getestet:

Und den Inhalt der Zieltabelle überprüft.

Soweit so gut, dachte ich mir. Also habe ich das Script in einen Loop gepackt. Via Pandas iterrows habe ich über jede Row im Tabellen-Dataframe iteriert. Innerhalb des For Loops habe ich dann die copy_table-Funktion aufgerufen.
for index, row in df_tables.toPandas().iterrows():
schema = row[1]
table = row[2]
copy_table(source_catalog, target_catalog, schema, table)Leider gab es Probleme mit gewissen Spaltennamen und die Funktion lieferte einen Error.
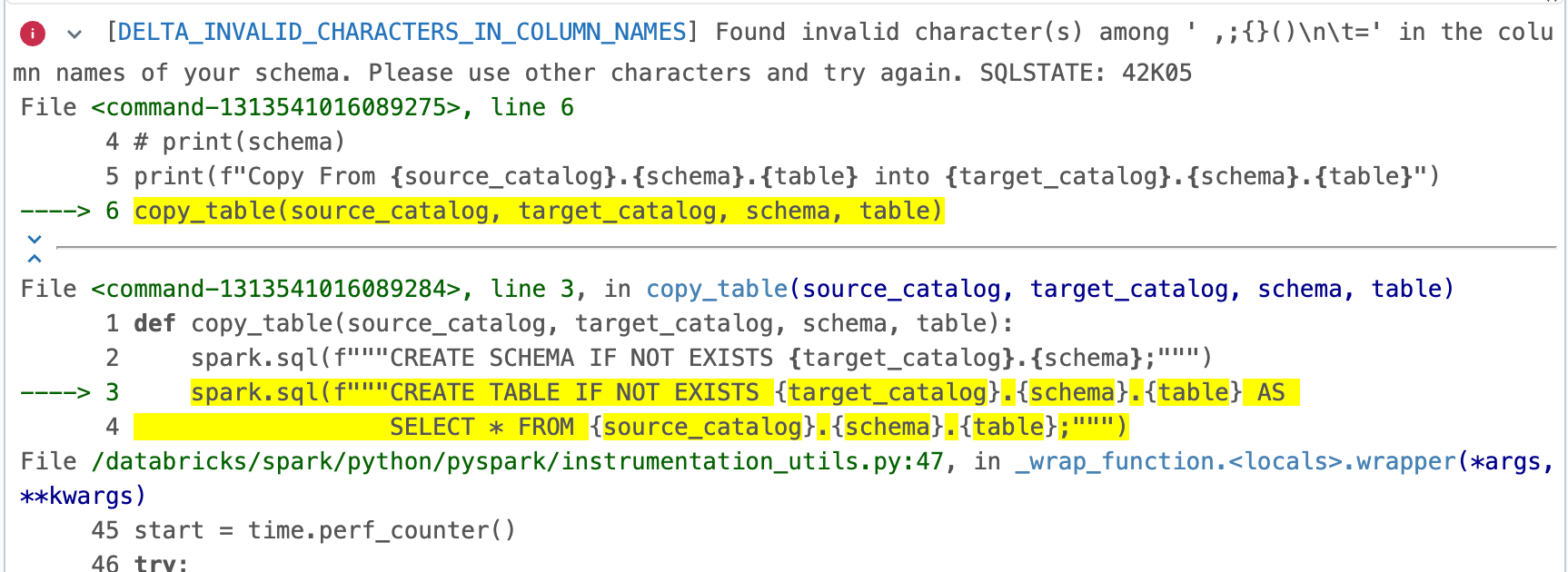
Es stellte sich heraus, dass Microsoft in seinen Beispiel-Datenbanken Spaltennamen mit Leerschlägen verwendet.

Ich habe nun die Funktion entsprechend umgeschrieben, so dass bei den Spaltennamen die Leerschläge mit einem “_” ersetzt wurden. Die Funktion sah dann so aus:
def copy_table(source_catalog, target_catalog, schema, table):
spark.sql(f"""CREATE SCHEMA IF NOT EXISTS {target_catalog}.{schema};""")
if spark.catalog.tableExists(f"{target_catalog}.{schema}.{table}"):
print(f"Skip table {target_catalog}.{schema}.{table}, because the table already exists.")
else:
print(f"Copy from {source_catalog}.{schema}.{table} into {target_catalog}.{schema}.{table}.")
source_df = spark.table(f"{source_catalog}.{schema}.{table}")
renamed_cols = [col.replace(" ", "_") for col in source_df.columns]
renamed_df = source_df.toDF(*renamed_cols)
renamed_df.write.mode("overwrite").saveAsTable(f"{target_catalog}.{schema}.{table}")
Ebenfalls habe ich Tabellen, welche schon kopiert wurde, mit einem if-Statement übersprungen. Der ganze Vorgang für eine Datenbank dauerte nur ein paar Minuten.

Ich konnte mit diesem Notebook alle 4 Datenbanken innerhalb kürzester Zeit von der Azure SQL Quelle in mein Lakehouse reinkopieren.
Source-Code
Das Notebook, welches ich geschrieben habe, findet ihr in meinem öffentlichen Git-Repo: https://github.com/stefanko-ch/Databricks_Dojo/blob/main/Snippets/Copy_all_tables_and_schemas_into_new_catalog.py