dbt core: Einrichten in VS Code und nahtlos auf Databricks ausführen – Schritt für Schritt
In dieser Schritt-für-Schritt-Anleitung zeige ich, wie man dbt core lokal in Visual Studio Code installiert, die entsprechenden Visual Studio Code Extension einrichtet und dbt auf Databricks ausführt.
Contents
Was ist dbt?
dbt steht für “data build tool” und ist ein Open-Source-Softwarewerkzeug, das hauptsächlich für das Datenmodellieren und die Datenintegration verwendet wird. Mit dbt können Datenanalysten und Data Engineers Datenpipelines erstellen, die Daten transformieren, bereinigen und in eine für Analysen geeignete Form bringen. Weitere Informationen zu dbt findet man hier: https://www.getdbt.com/
dbt kann entweder in einer bezahlten Cloud-Version oder als Opensource-Version betrieben werden. In dieser Anleitung verwende ich die kostenlose core-Version.
Vorbereitungen und Voraussetzungen
Ich gehe davon aus, dass du bereits eine Databricks-Umgebung eingerichtet hast. Wenn nicht, habe ich hier eine Schritt-für-Schritt-Anleitung geschrieben, wie man in Azure eine solche Umgebung erstellt.
Weiter solltest du folgende Software auf deinem Computer installieren:
Github Desktop: https://desktop.github.com/
Visual Studio Code: https://code.visualstudio.com/
Python: https://www.python.org/downloads/
Git: https://git-scm.com/downloads
Git-Repo erstellen
Bevor ich mit der eigentlichen Installation beginnen, werde ich ein Github-Repository erstellen. Auf Github wechsle ich zu den Repositories. Dort klicke ich auf “New”.
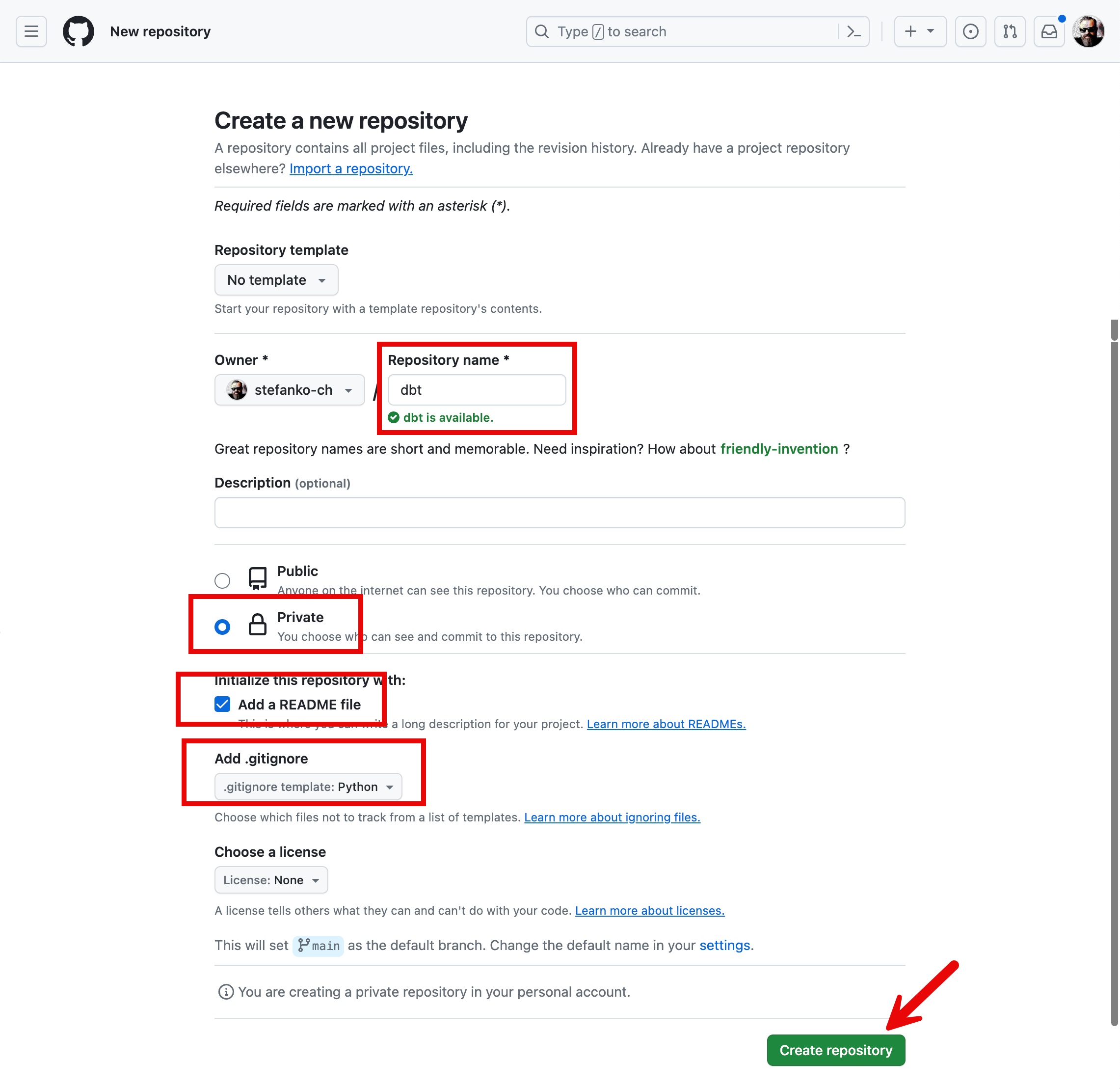
Ich vergebe einen sprechenden Namen für mein neues Projekt und mache noch ein paar zusätzlich Einstellungen:
Das leere Repository kann ich dann via Browser und VS Code auf meinen lokalen Rechner klonen.

Es öffnet sich ein Pop Up
Es öffnet sich Visual Studio Code und man sieht den Inhalt des Projektes, welches jetzt erst das README- und das .gitignore-File enthält.
Man kann entweder ein Terminal öffnen, oder das in VS Code integriert Terminal verwenden. So muss ich nicht zwischen einem externen Terminal und VS Code hin und her switchen.
Python Vorbereitungen
Für dbt wird Python benötigt. Für VS Code gibt es eine Extension für Python, welche ich installiere.

Ich überprüfe die Installation und Version von Python.
python --versionIm Terminal sollte dann die entsprechende Version zurückgegeben werden.

Damit ich keine Konflikte mit anderen Python Projekten und Installationen bekomme, installiere ich dbt in eine Virtualenv. Weitere Informationen, was eine Virtualenv ist, findest du hier: https://docs.python.org/3/library/venv.html
Die Virtualenv werde ich im Verzeichnis von dem geklonten Github Projekt erstellen. Falls man sich noch nicht in diesem Verzeichnis befindet, muss man dahin navigieren. Anschliessend kann die VirtualEnv mit folgendem Befehl erstellt werden:
python -m venv .dbtenvDer Name der VirtualEnv nenne ich .dbtenv. Wenn der Befehl ausgeführt wird, sieht man einen gleichnamigen Ordner, welcher erstellt wird. In diesem befinden sich die Binaries für die Umgebung.

Der Ordner .dbtenv befindet sich im Git-Verzeichnis und würde bei einem Commit ebenfalls in das Git-Repository gepusht. Dies will ich aber verhindern und füge den Ordner zum .gitignore hinzu. Dazu kann man eine neue Zeile in der Datei .gitignore hinzufügen:
/.dbtenv
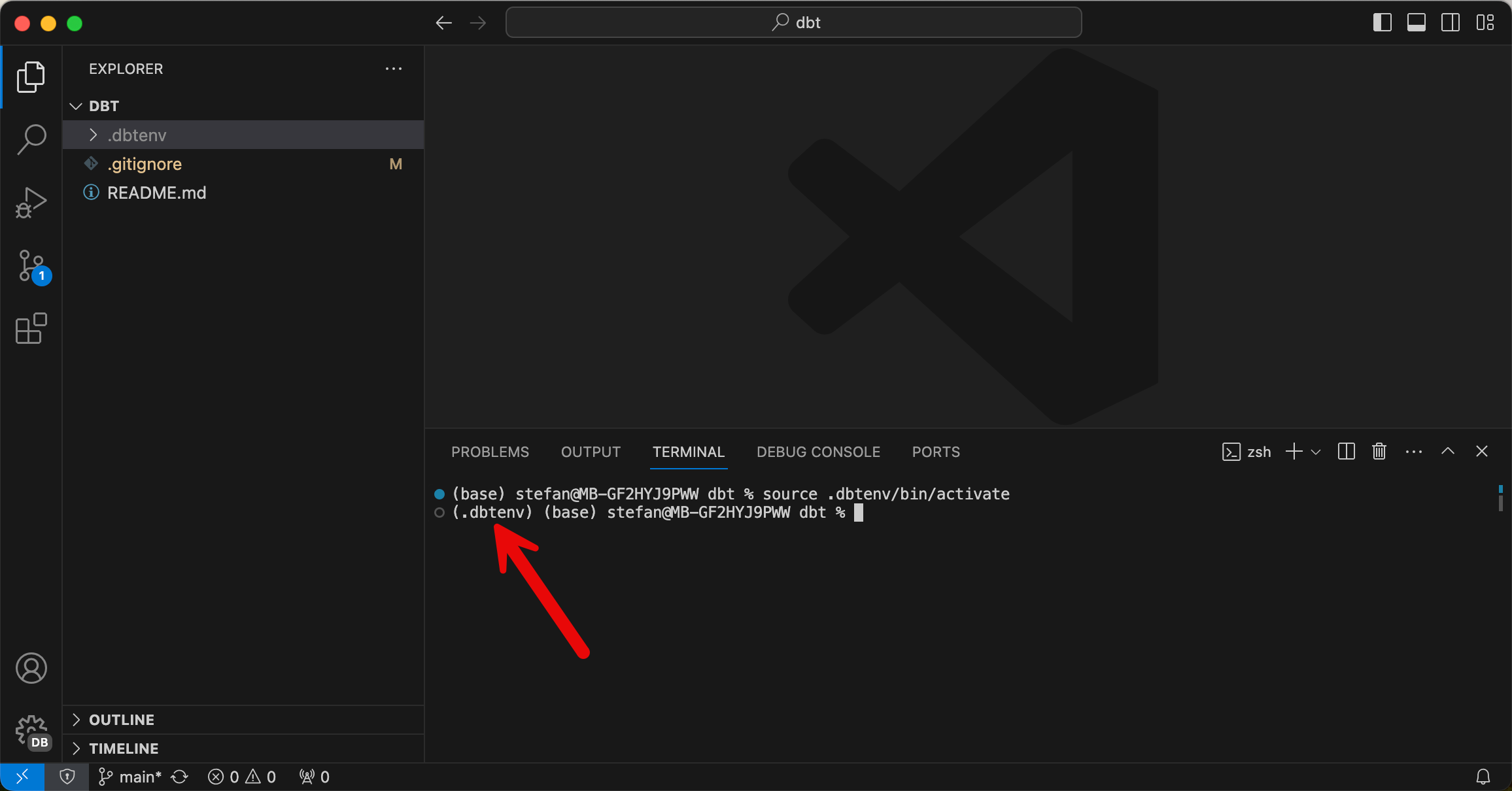
Nun muss die VirtualEnv noch aktiviert werden, was man im Terminal mit einer Befehlszeile tun kann. Ich arbeite auf einem Mac, da ist die Befehlszeile source .dbtenv/bin/activate, auf einem Windows Rechner lautet der Befehl anderst, zum Beispiel .dbtenv\Scripts\Activate.ps1 Je nach der eigenen Umgebung muss der entsprechende Code angepasst werden.
source .dbtenv/bin/activateDass die Umgebung nun aktiviert ist, sieht man im Terminal, es ist der Name der VirtualEnv vorangestellt:
Um den Kontext der VirtualEnv zu verlassen, kann man den Befehl “deactivate” benutzen.
Ich will jetzt aber in der VirtualEnv bleiben und starte mit der Installation von dbt-core:
pip install dbt-coreNun werden sämtliche benötigten Pakete installiert .
Nebst dbt-core benötige ich auch das Modul für Databricks. Dieses installiere ich ebenfalls.
pip install dbt-databricksDie Installation und Versionen der beiden Modulen kann man überprüfen.
dbt --versionEs erscheint eine Ausgabe mit den entsprechenden Versionen:

dbt Projekt erstellen
Nun wird das dbt Projekt initialisiert. Ich gebe in meinem Beispiel dem Projekt den Namen “dbt_playground”.
dbt init dbt_playgroundIm Terminal werden dann mehrere Input-Parameter abgefragt, welche nacheinander eingegeben werden können.
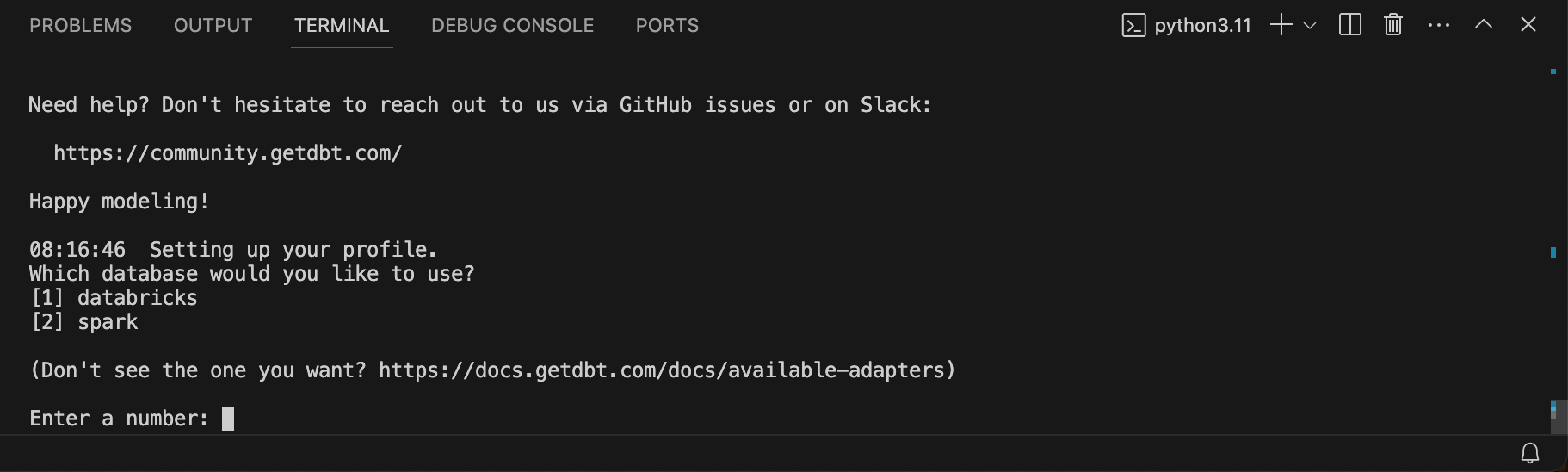
Bei der Datenbank wähle ich [1] für Databricks.
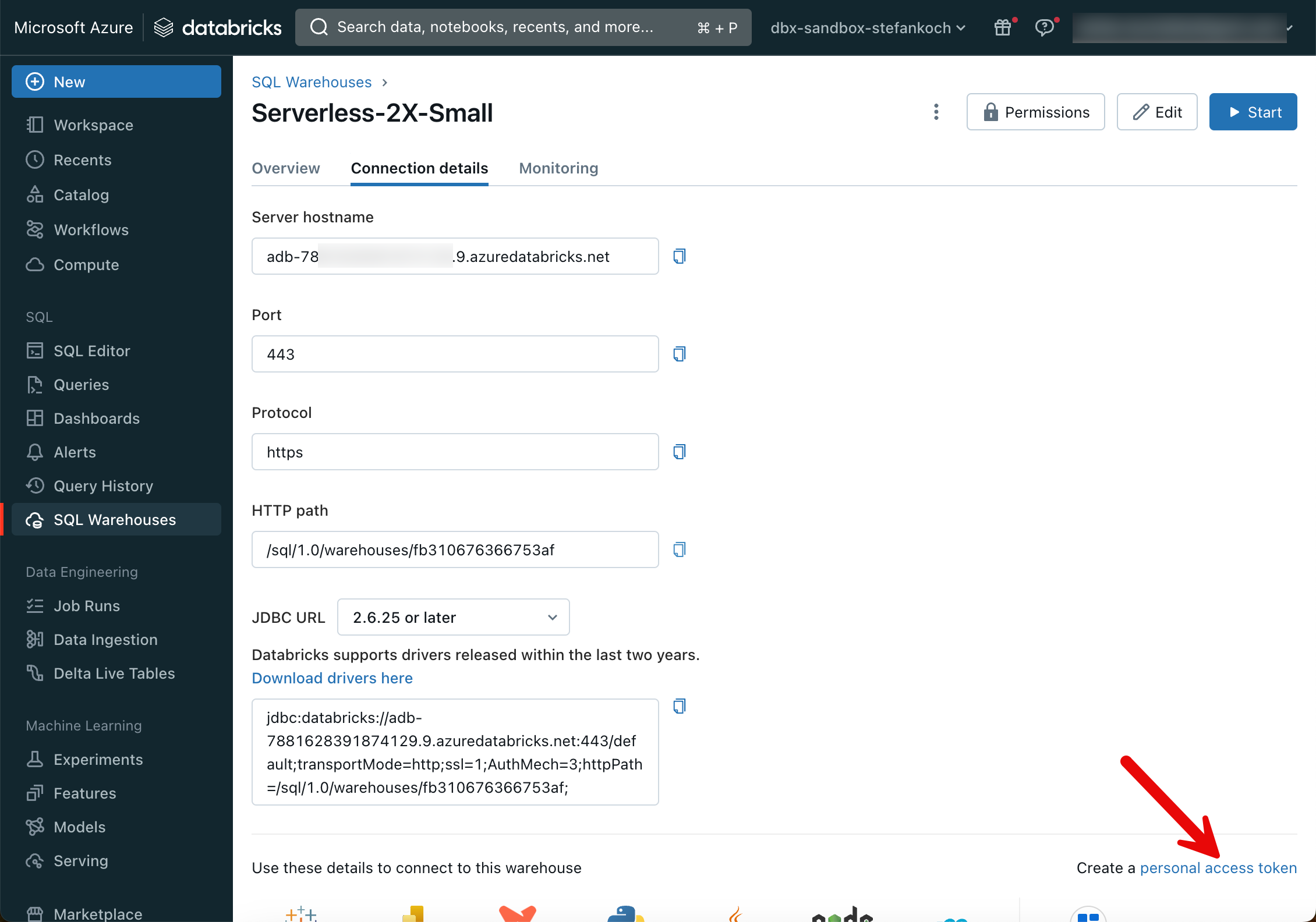
Anschliessend wird nach dem Host gefragt. Um diesen herauszufinden, logge ich mich im Databricks Workspace ein und wechsle zu den SQL Warehouses.

Am besten erstellt man einen Serverless-Cluster. Diese haben eine Startzeit von rund 8 Sekunden und sind deshalb ideal zum entwickeln. Bei der Grösse kann man die kleinste T-Shirt Grösse wählen von 2X-Small, das reicht vollkommen aus für die meisten Workloads. Wenn der Warehouse-Cluster erstellt ist, auf den Namen des Warehouses klicken und zu “Connection Details” wechseln.
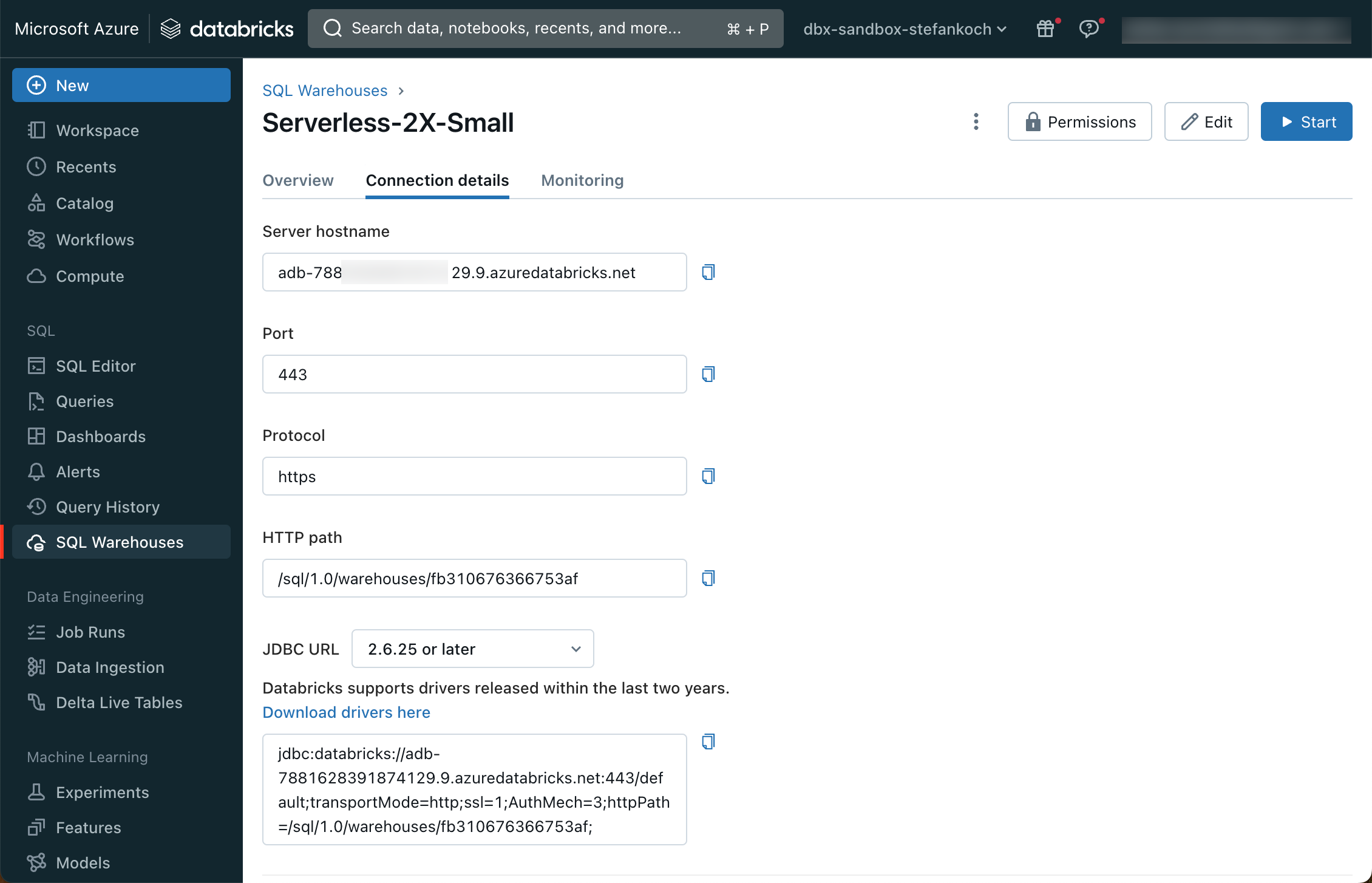
Hier sieht man den Server Hostname, welcher im Dialog-Fenster von der dbt Initialisierung eingefügt werden kann. Ebenfalls den HTTP path, welcher im nächsten Schritt erfragt wird. Als nächstes muss man einen Personal Access Token einfügen, welchen man im Databricks Workspace erstellen kann.
Ich erstelle einen neuen Token.

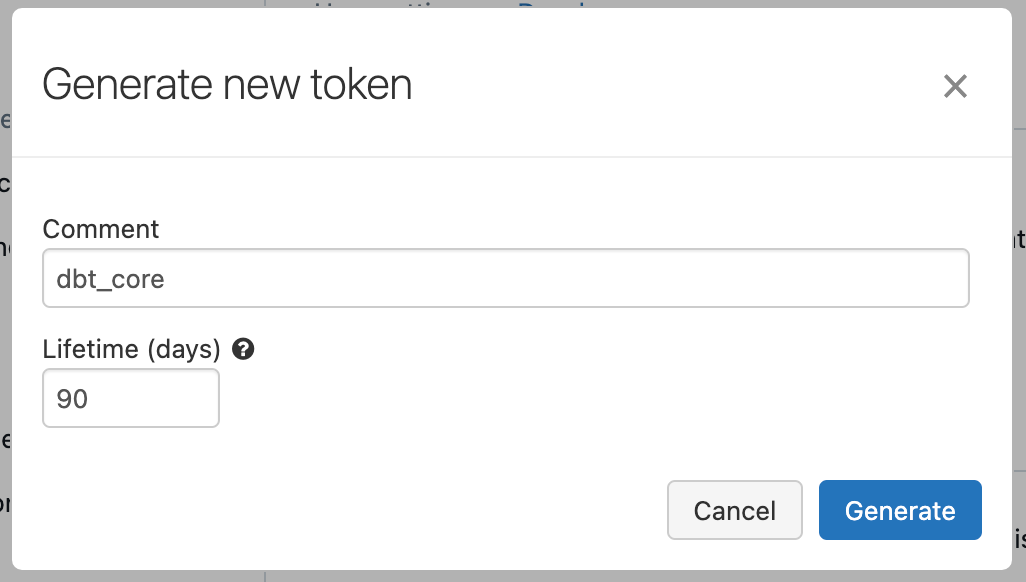

Den PAT kann man kopieren und dann im Terminal unter der entsprechenden Option einfügen.
Bei der nächsten Option wähle ich Unity Catalog. Man kann dann einen Namen für den Catalog und ein Schema angeben.

Um das Setup zu testen, wechsle ich in das neu erstellt Verzeichnis, welches während der Initialisierung erstellt wurde und führe dbt debug aus.
cd dbt_playground
dbt debug
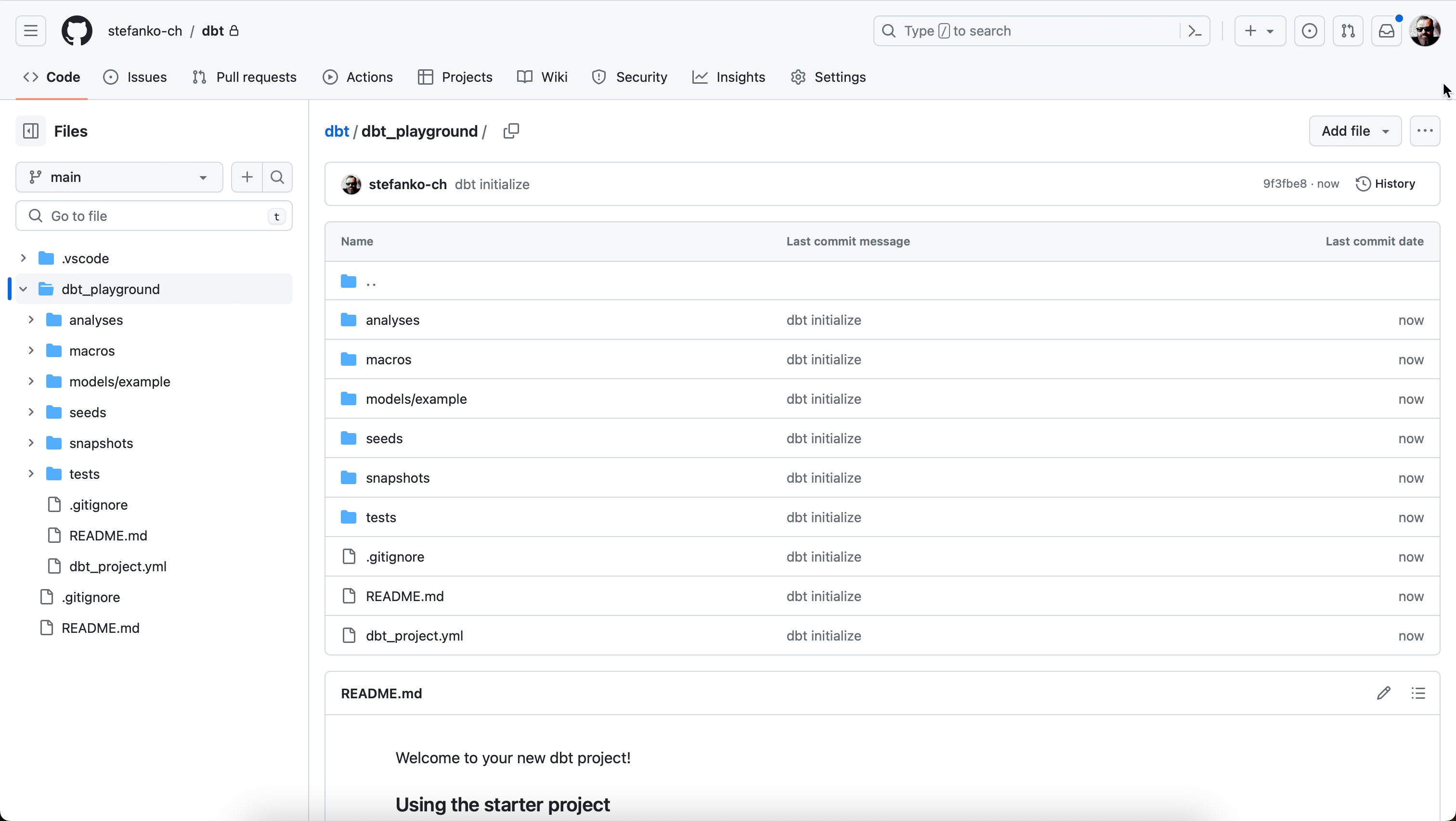
Wie zu sehen ist, ist mein Projekt erfolgreich erstellt worden. Weiter wurden bereits 2 Beispiel-Modelle erstellt:

Falls man zu einem späteren Zeitpunkt Anpassungen an den Connection-Settings machen muss, kann man hierfür das Profile bearbeiten.
nano /Users/[username]/.dbt/profiles.yml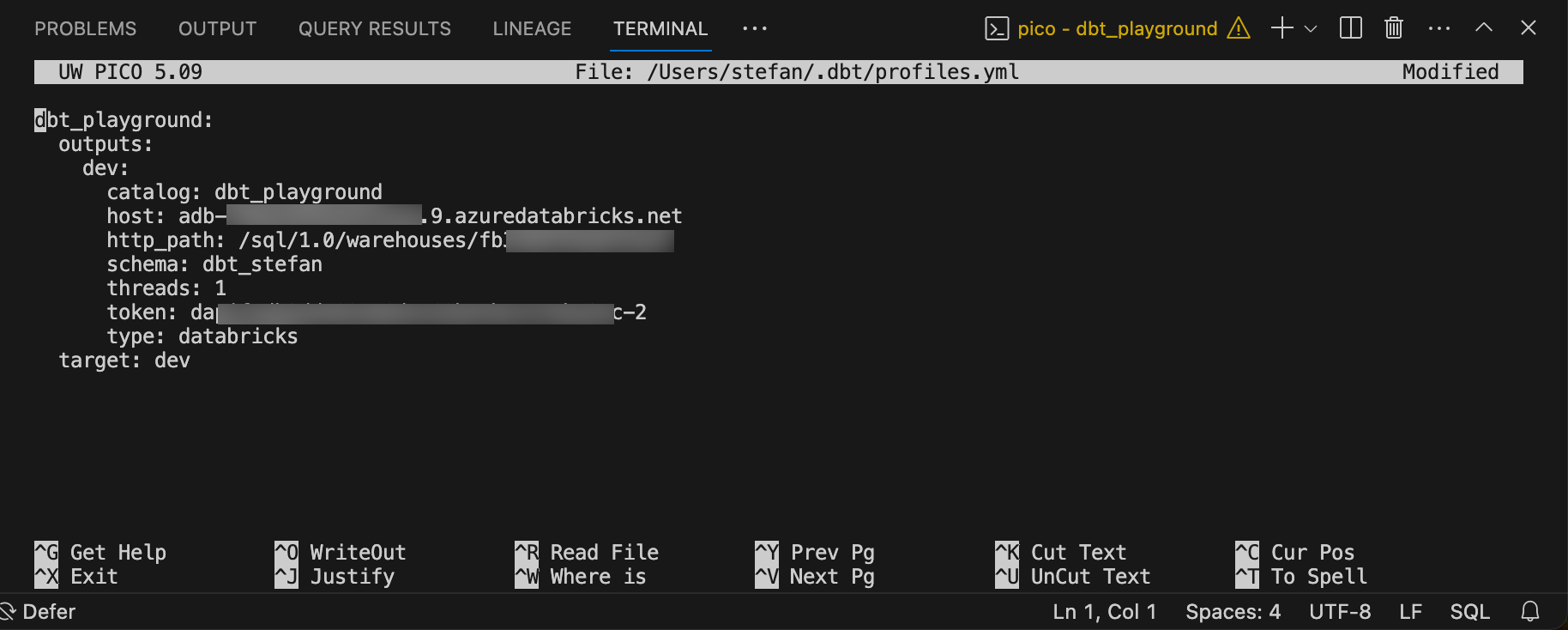
Catalog für dbt erstellen
Ich verwende Unity Catalog und möchte meine dbt Modelle im Catalog “dbt_playground” deployen. Hierfür muss zuerst der entsprechende Catalog in Databricks erstellt werden.

VS Code dbt Extension installieren
Für Visual Studio Code gibt es eine Extension, welche die Arbeit mit dbt core vereinfacht. Diese kann man sich im Marketplace von VS Code installieren.

dbt run
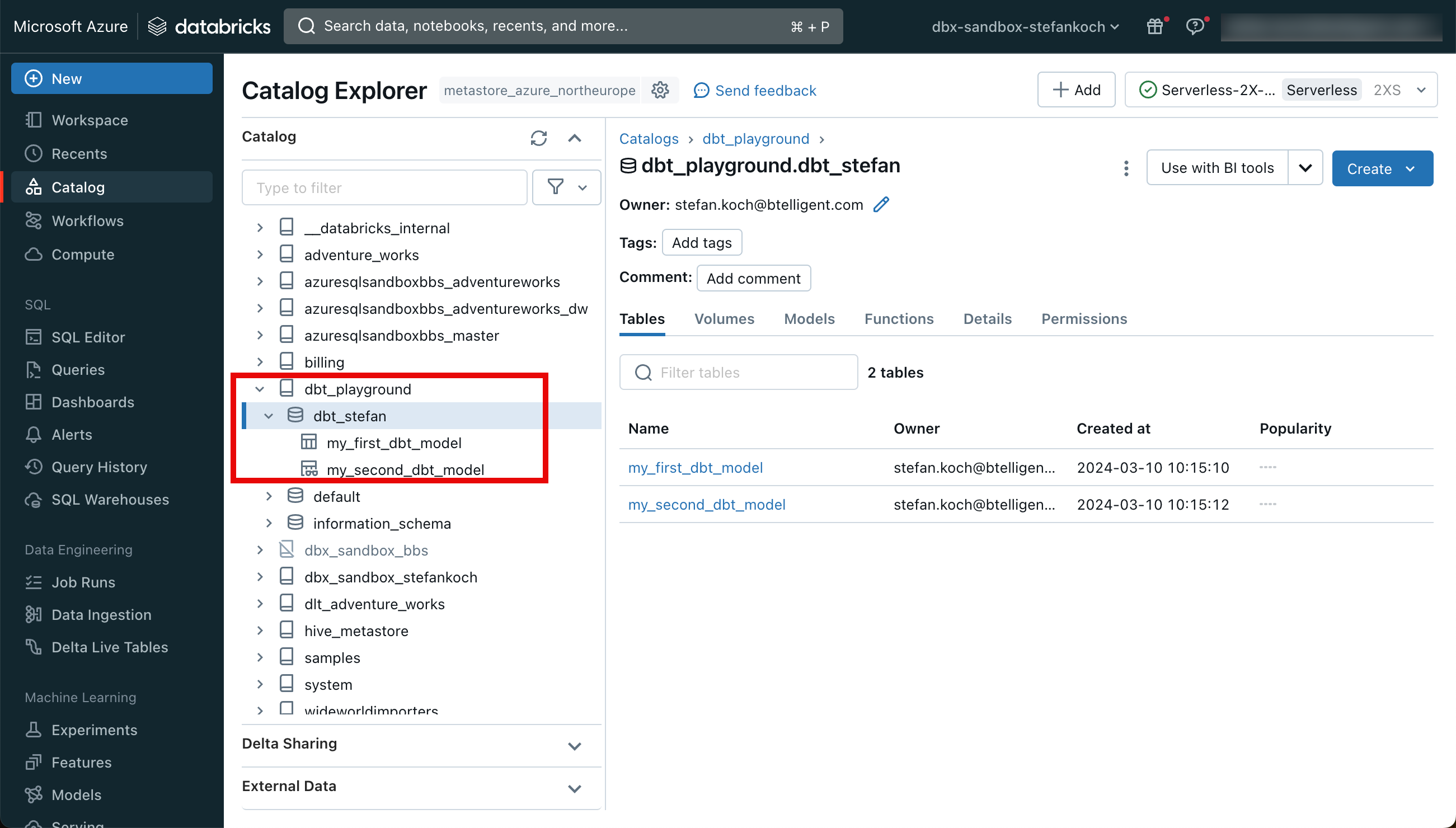
Nun werde ich die beiden Beispiel-Modelle deployen, indem ich dbt run ausführe.
dbt runBei diesem Befehl wird im Hintergrund der Warehouse Cluster gestartet und die Modelle deployt.

Wenn man im Databricks Workspace zum entsprechenden Catalog wechselt, sieht man die neu erstellten Objekte.
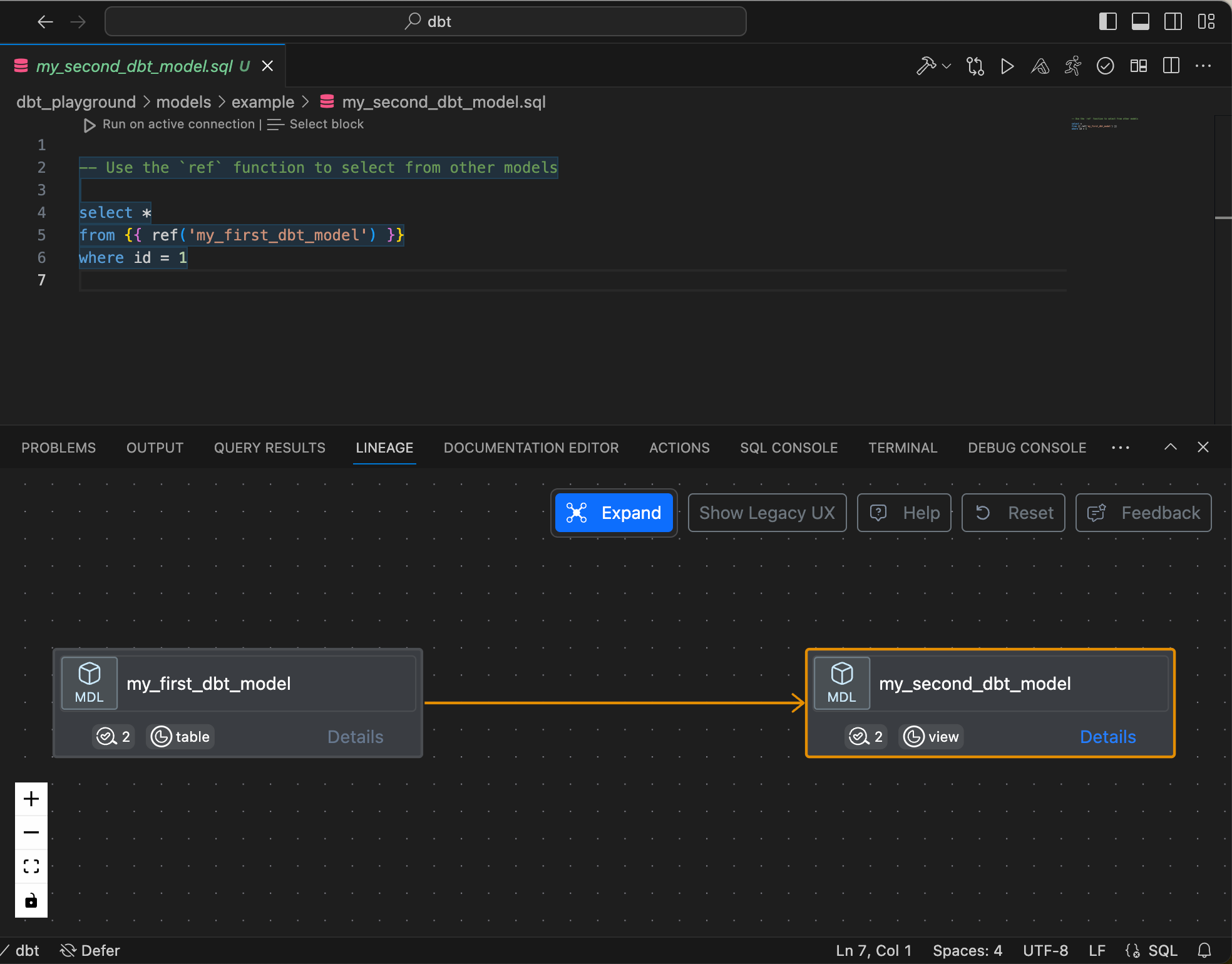
Die Extension bietet viele Annehmlichkeiten, wenn man mit dbt core arbeitet. Es gibt eine Befehlspalette, mit welcher man z.B. das Resultat einer Query eines Models bekommt.
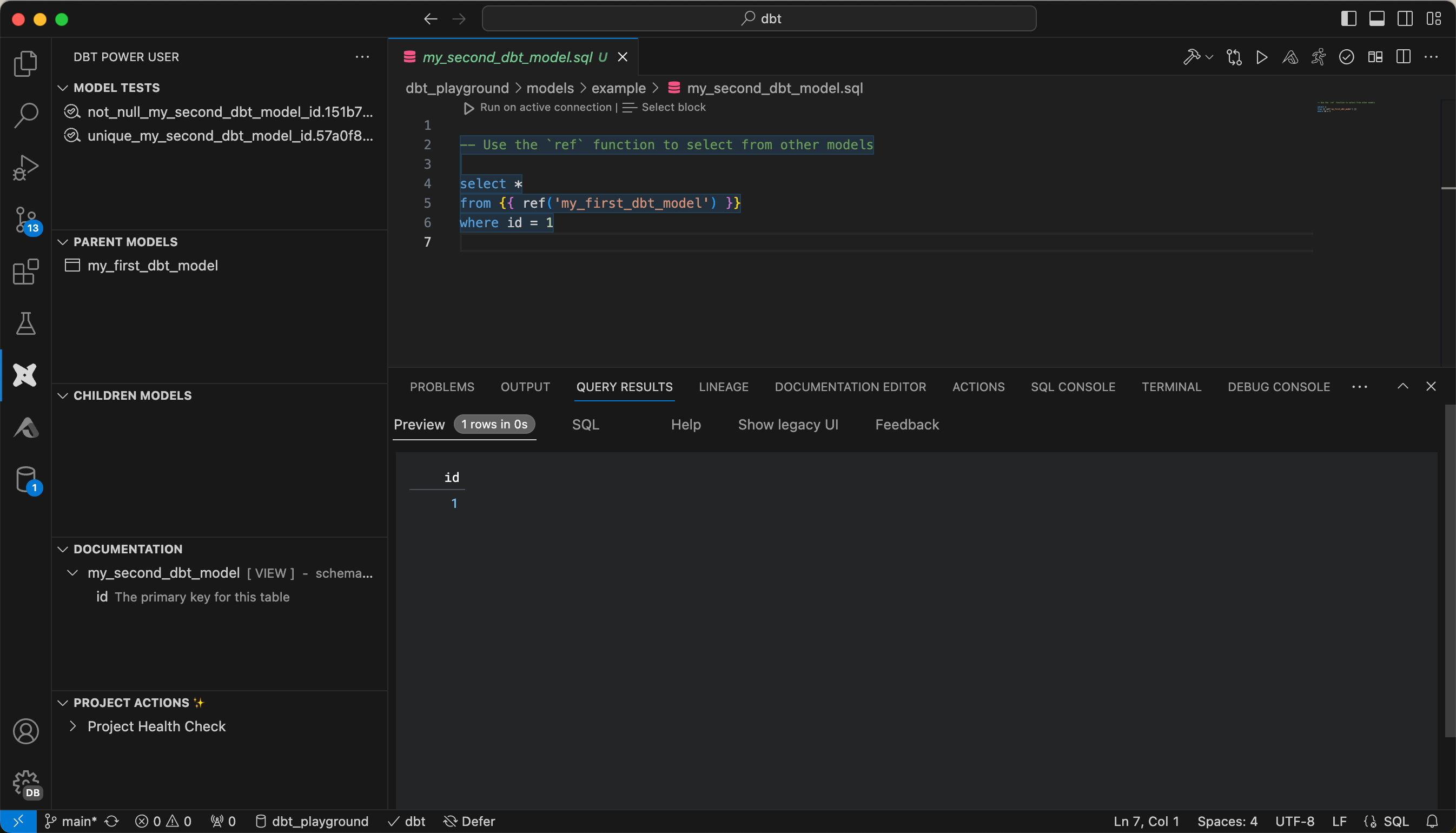
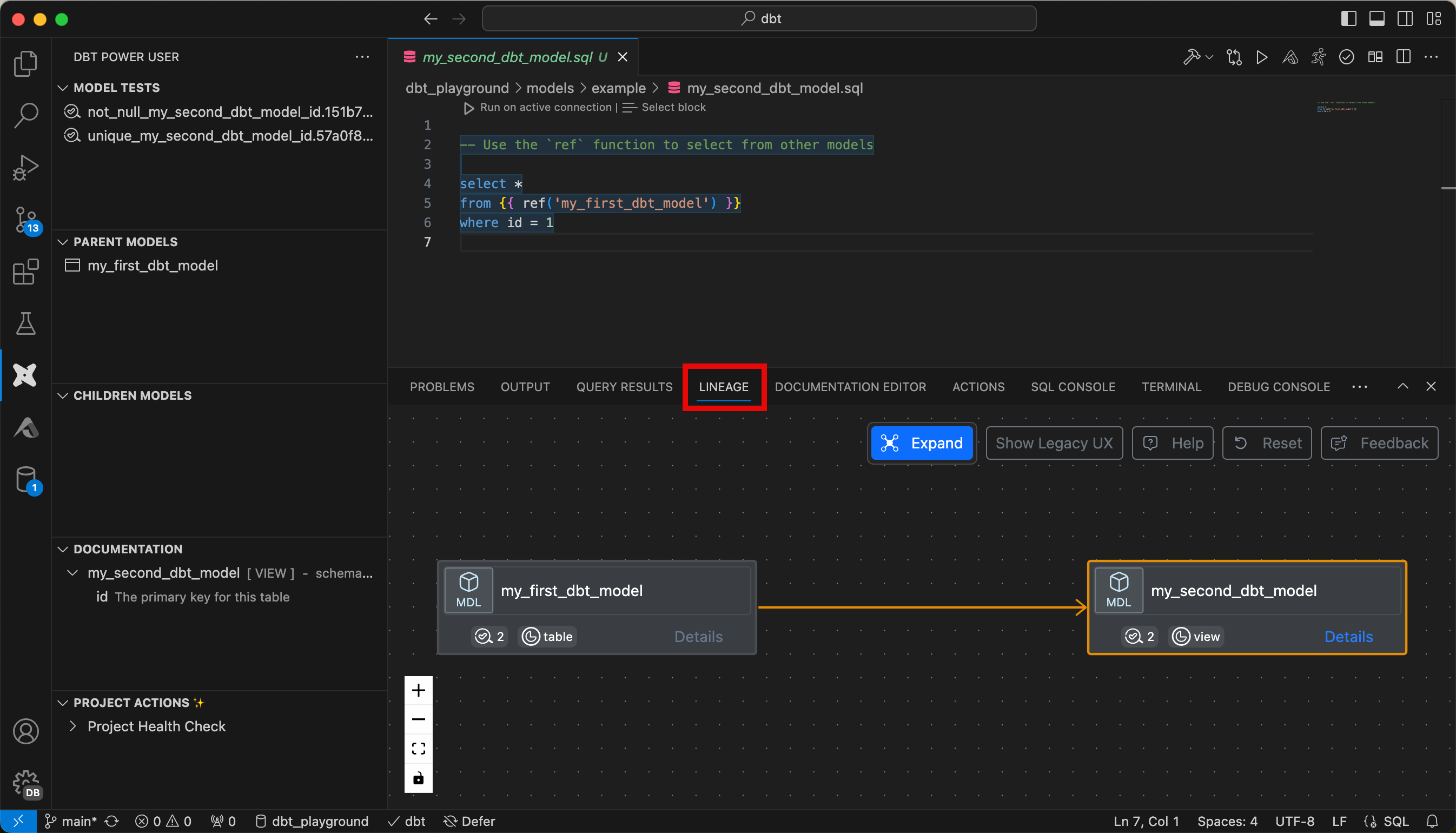
Oder man kann sich die Lineage anzeigen lassen.
Weiter ist auch ein Dokumentations-Editor vorhanden.

Für weitere Features dieser Extension empfehle ich die Dokumentation zu konsultieren: https://docs.myaltimate.com
Databricks SQL Extension in VS Code installieren
Damit ich während der Entwicklung nicht immer zwischen VS Code und dem Databricks Workspace hin und her wechseln muss, kann ich in VS Code eine Extension installieren, um die Daten direkt in der IDE abfragen zu können. Hierfür installiere ich die Extension “Databricks Driver for SQLTools”.

Nach der Installation erscheint auf der linken Seite ein neues Icon für die Extension. Wenn ich zur Extension wechsle, kann ich eine neue Connection erstellen.

Bei der Konfiguration werden verschiedene Details abgefragt, unter anderem die Verbindungsdetails zu dem SQL Warehouse. Diese sind analog dem Setup von dbt und können entsprechend übernommen werden.
Nachdem die Connection eingerichtet ist, kann man direkt von VS Code aus SQL-Abfragen an das Warehouse senden.

Projekt commiten und nach Git pushen
Nun, da ich das Projekt fertig eingerichtet habe, möchte ich die neu erstellten Artefakte commiten und ins Github Repo pushen. Jedoch muss ich noch schauen, dass gewisse Files nicht mithochgepusht werden. Wenn ich in VS Code zur “Source Control” wechsle, sehe ich alle Änderungen.
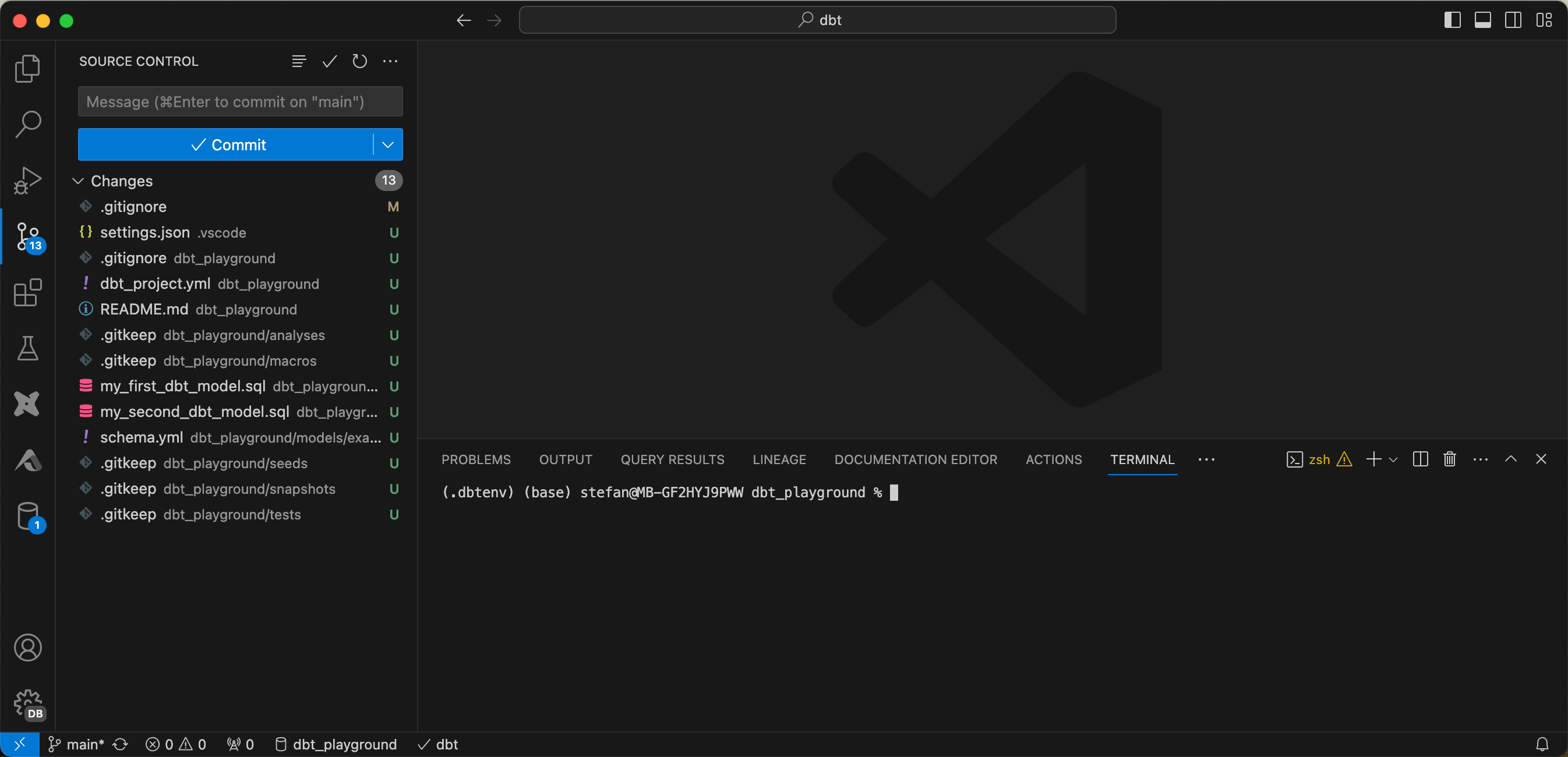
Man kann die einzelnen Files anklicken und die Änderungen sehen. Wenn alles wie gewünscht vorhanden ist, kann man commiten und pushen.
Die Änderungen sind anschliessend im Github Repo ersichtlich.