How To: Wie man Wetterdaten von OpenWeather in das Databricks Lakehouse lädt, verarbeitet und visualisiert
In diesem HowTo zeige ich, wie man von der OpenWeather API Wetterdaten in das Databricks Lakehouse lädt. Dabei werden die Daten via REST API von OpenWeather geladen und anschliessend in der Medallion-Architektur im Lakehouse verarbeitet. Am Schluss baue ich ein simples Lakeview-Dashboard darauf.
Contents
Vorbereitung
Ich gehe davon aus, dass bereits eine Databricks Umgebung inklusive Unity Catalog vorhanden ist. Falls nicht, in einem früheren Artikel habe ich das Setup erklärt. Ebenfalls benötigt man einen Gratis-Account bei OpenWeather und einen Azure KeyVault, um den API-Key sicher zu speichern.
OpenWeather

OpenWeather ist ein Unternehmen, das Wetterdaten und -vorhersagen über eine Vielzahl von APIs (Application Programming Interfaces) zur Verfügung stellt. Diese APIs ermöglichen Entwicklern den Zugriff auf aktuelle Wetterdaten sowie Prognosen für verschiedene Orte auf der ganzen Welt.
Für gewisse API’s ist eine Subscription nötig, damit man die Daten herunterladen kann, es gibt aber auch einige, welche kostenlos sind. Unter anderem die “Current Weather Data”. Eine Übersicht der API’s erhälst du hier: https://openweathermap.org/api
Damit man die API anzapfen kann, muss man zuerst ein kostenloses Konto erstellen. https://home.openweathermap.org/users/sign_up
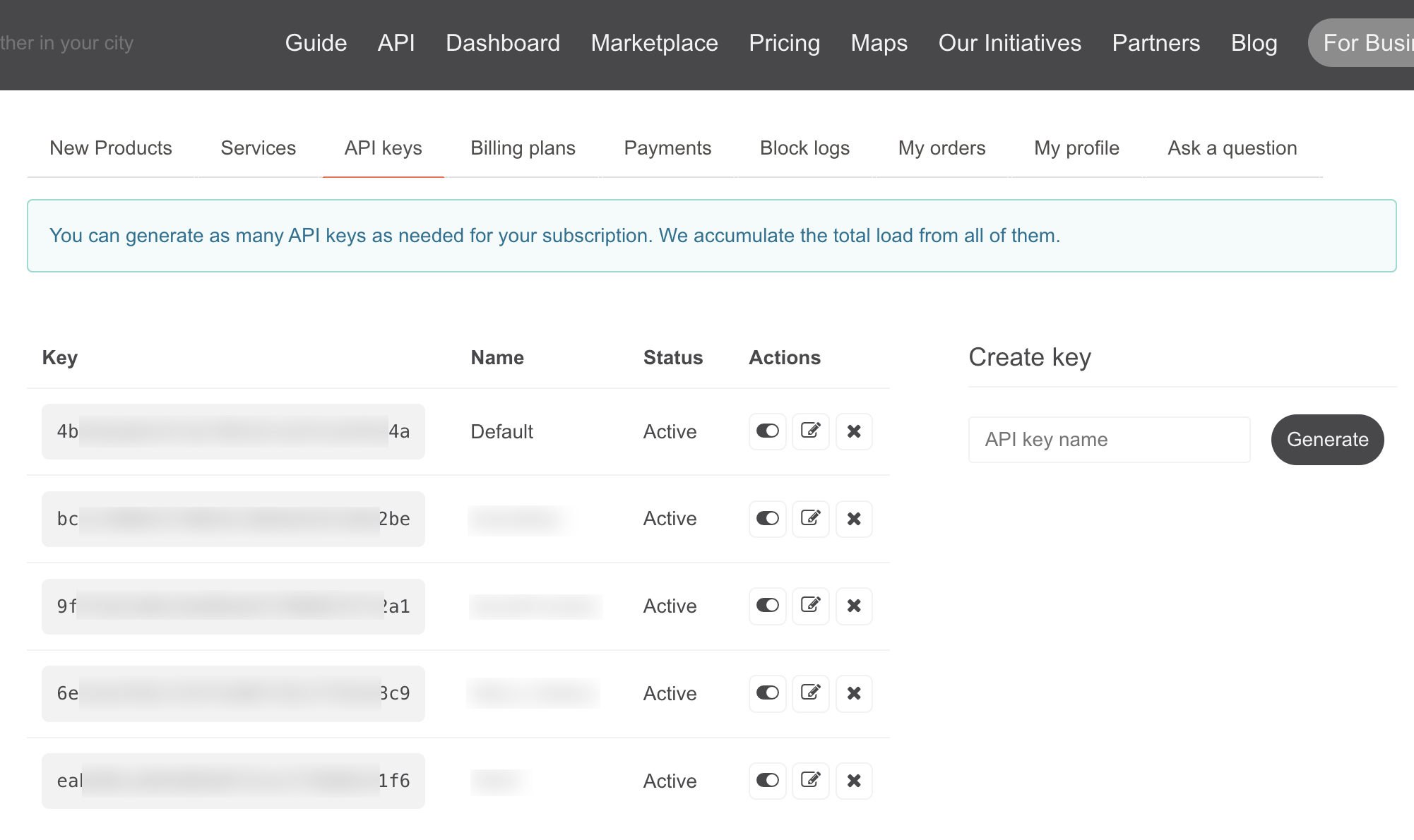
Nach der Registrierung kann man unter seinem Benutzeraccount zu den API gelangen.

Standardmässig ist schon ein API Key mit dem Namen Default vorhanden. Man kann sich natürlich noch weitere Keys erstellen, falls man verschiedene Applikationen betreibt.
Azure KeyVault
Den API Key in Klartext in einem Code zu verwenden, wäre fatal und stellt ein grosses Sicherheitsrisiko dar. Aus diesem Grund speichere ich den Key in einem Azure KeyVault, so dass ich in meinem Code nur referenzieren muss und den Code sicher in einem Repo einchecken kann.
Im Azure Portal navigiere ich zu meinem KeyVault und erstelle ein neues Secret.

Im Secrets Tab auf “Generate/Import” klicken.
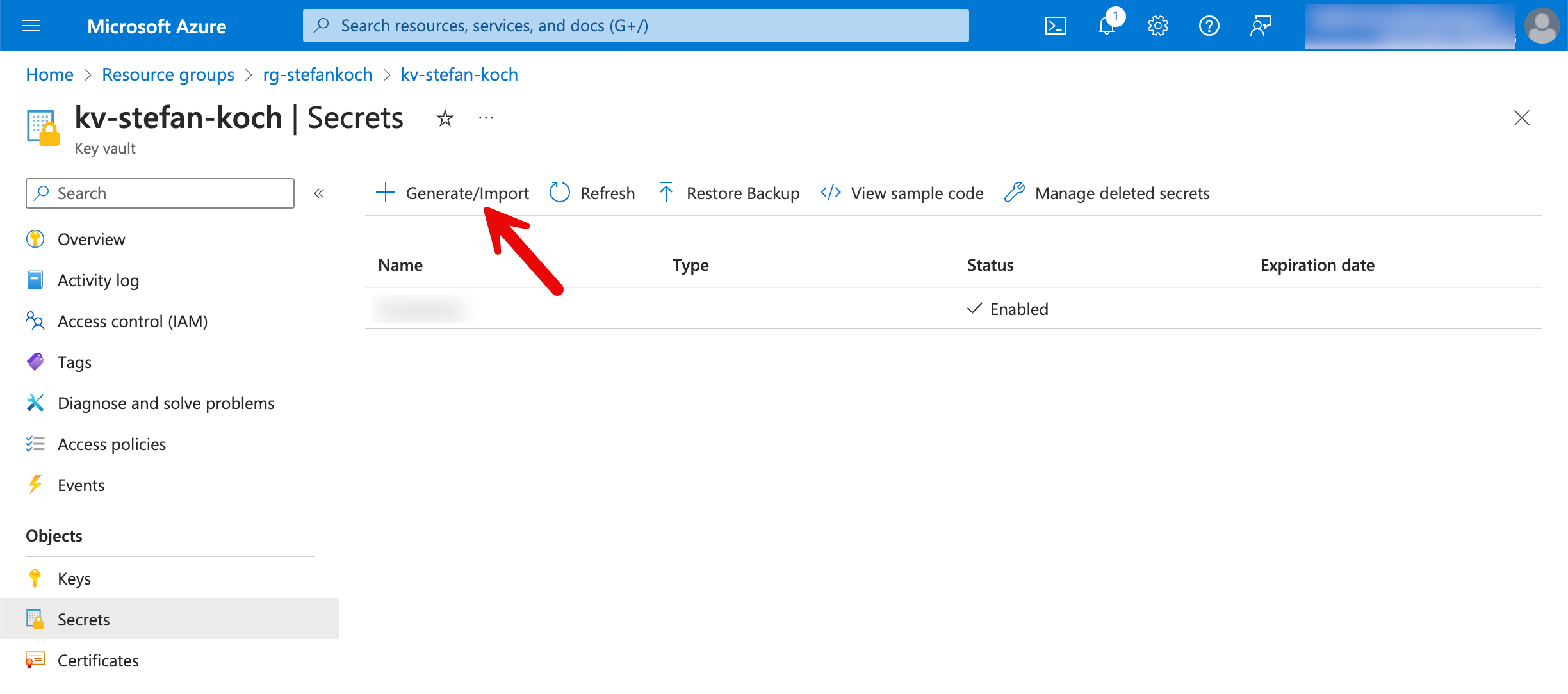
Für das neu zu erstellende Secret vergebe ich einen sprechenden Namen, damit man später am Namen erkennt, für was dieses Secret erstellt wurde.
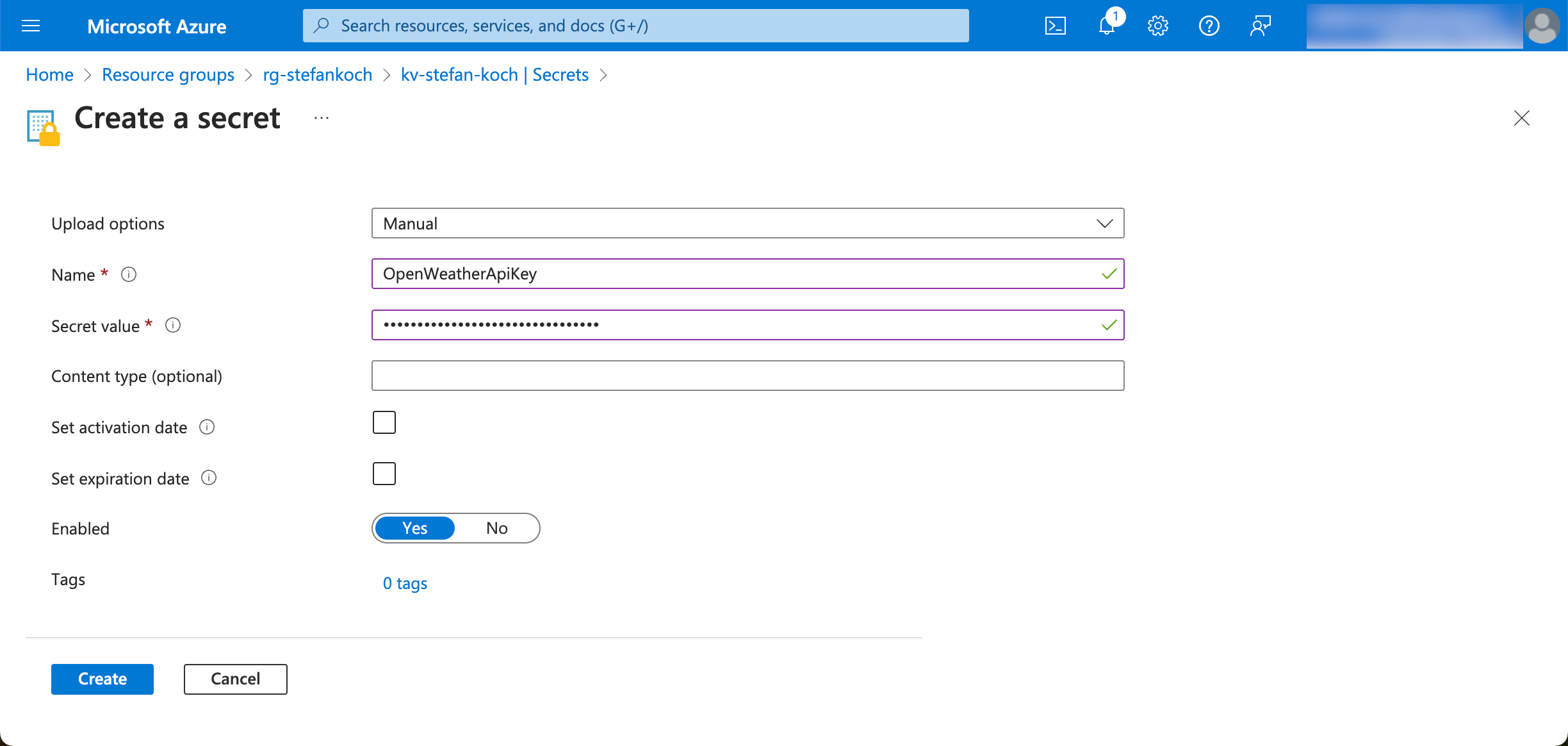
Das Secret kann später über den Namen angesprochen werden.
Databricks Unity Catalog vorbereiten
In Databricks erstelle ich für mein Beispiel einen neuen Catalog, welchen ich “weather” nenne. Innerhalb dieses Catalog erstelle ich ich dann 4 Schemas:
- bronze
- silver
- gold
- elt
Innerhalb vom Schema silver erstelle ich ein Volume, in welches ich Dateien speichern kann. In meinem Fall werden dort checkpoints gespeichert, darum nenne ich die Volumes entsprechend. Das ganze sieht dann folgendermassen aus.
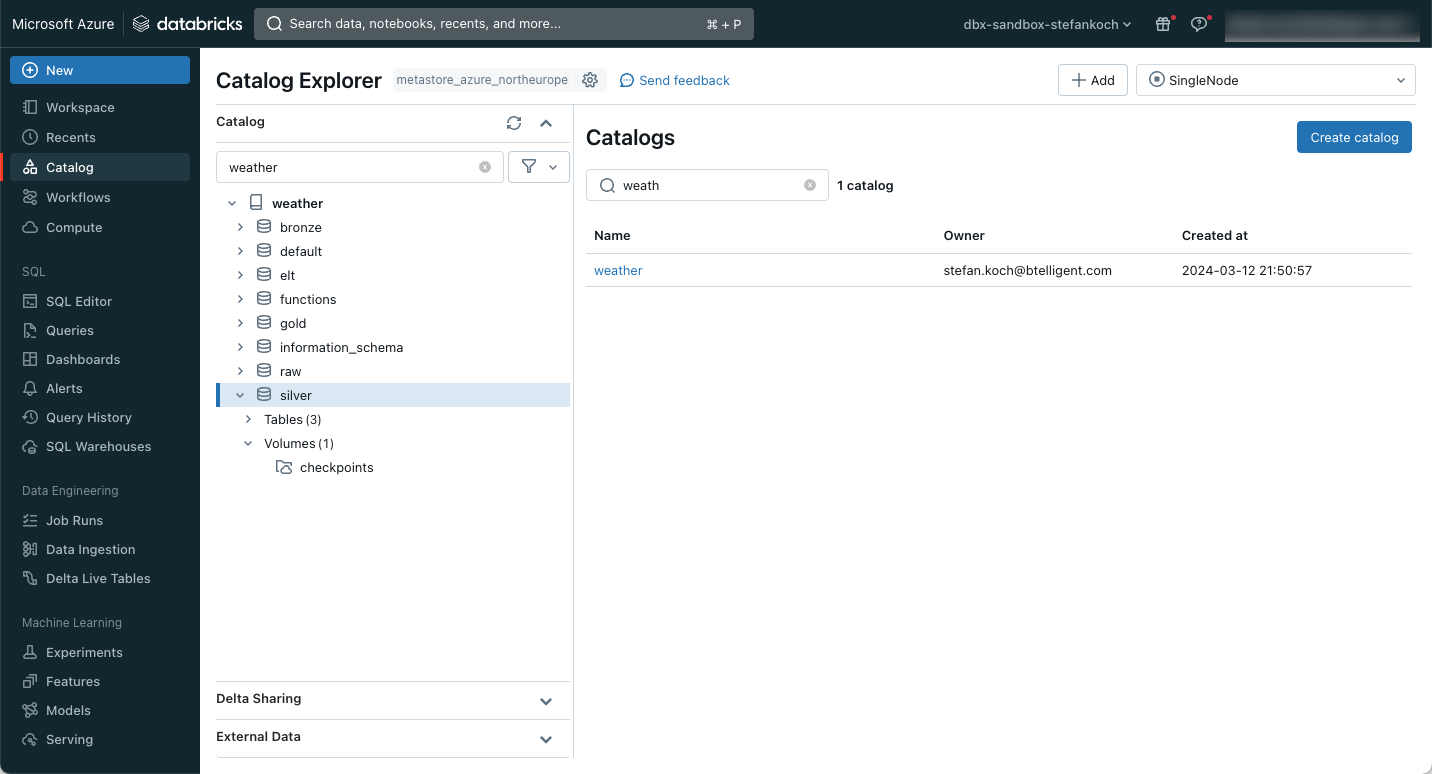
Falls du nicht weiss, wie man einen Catalog, die Schemas und ein Volume erstellst, dann schaue hier nach.
Databricks Cluster erstellen
API-Daten mit einem Spark Cluster herunterzuladen ist eigentlich wie mit Kanonen auf Spatzen geschossen. Eigentlich, aber… Natürlich kann man einen Serverless-Service benutzer wie eine Azure Function, oder ein PaaS-Angebot wie die Azure Factory. Es direkt mit einem Databricks Cluster zu machen, kann aber auch durchaus Sinn machen. Wenn man nämlich den Cluster für die nachträgliche Verarbeitung gebraucht, dann ist der Cluster schon hochgefahren, das herunterladen der Daten vor der Verarbeitung dauert nur ein paar Sekunden. Man kann Geld sparen, indem man einen Single-Node Cluster mit der kleinsten Ausführung wählt. Aus diesem Grund habe ich einen kleinen Single-Node-Cluster erstellt mit einem F4s_v2-Node, dieser hat 8 GB Memory und 4 Kerne. Bei der Runtime wähle ich die letzte LTS-Version. Photon kann man für den Anwendungszweck ruhig weglassen. Den Cluster verwende ich hauptsächlich für die Entwicklung, also stelle ich ein, dass er nach 30 Minuten Inaktivität automatisch herunterfährt.

Github Repository in Databricks verbinden
Den Code für dieses Beispiel werde ich in einem Github Repository speichern. Dieses lässt sich einfach in Databricks einbinden.

Weitere Informationen zu Repos in Databricks findet man hier: https://docs.databricks.com/en/repos/index.html
Der Code von diesem Beispiel findet man in diesem Github-Repo.
Architektur
Die Architektur für dieses kleine Setup sieht folgendermassen aus:
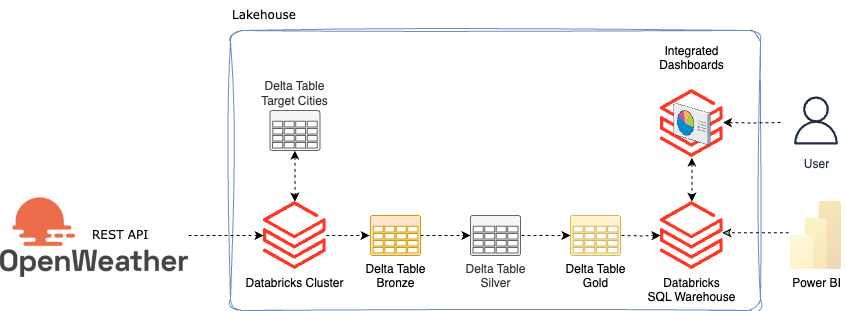
Da ich das Wetter für mehrere Städte herunterladen will, erstelle ich eine Delta Table, in welcher ich Städtenamen schreibe. So können beliebige Städte im Nachhinein hinzugefügt werden, ohne dass der Source-Code angepasst werden muss.
In einem ersten Schritt werden die Städte ausgelesen. Anschliessend hole ich mir ebenfalls bei Openweather ein paar zusätzliche Informationen zu den jeweiligen Städten und speichere diese in einer Bronzetabelle. Das Wetter und noch eine API für Luftverschmutzung werden in der Bronze Table gespeichert. Anschliessend werden die Daten nach Silber verarbeitet und veredelt. In Gold werden Sie dann als View zur Verfügung gestellt, so dass sie entweder mit integrierten Dashboards in Databricks visualisiert werden können, oder mit externen Tools wie Power BI von Databricks bezogen werden können.
ELT Tabellen erstellen
Die Tabelle “target_cities” mit den Ziel-Städtenamen speichere ich im Schema “elt” ab. Dafür habe ich ein kleines Notebook mit dem Namen “00_Setup_Environment” geschrieben.
In einem ersten Schritt erstelle ich die Tabelle und befülle sie mit den Städtenamen.
CREATE TABLE IF NOT EXISTS weather.elt.target_cities (
id INT NOT NULL PRIMARY KEY,
city VARCHAR(100)
);
INSERT INTO weather.elt.target_cities (id, city)
VALUES
(1, 'Lucerne'),
(2, 'Zurich'),
(3, 'Geneva'),
(4, 'Basel'),
(5, 'Zug'),
(6, 'Bern'),
(7, 'Winterthur'),
(8, 'Chur'),
(9, 'Lugano'),
(10, 'Lausanne'),
(11, 'Thun'),
(12, 'Sitten'),
(13, 'Olten'),
(14, 'Schaffhausen'),
(15, 'Aarau'),
(16, 'Oberrueti'),
(17, 'Davos'),
(18, 'Interlaken'),
(19, 'Kloten'),
(20, 'Ascona')API Load
In einem weiteren Notebook “02_OpenWeather_API_2_Bronze” lade ich die entsprechenden Daten von der API herunter.
Es gibt mehrere Möglichkeiten, wie man die Daten herunterladen kann. Zum Beispiel könnte man die Daten als JSON im Datalake abspeichern und anschliessend weiterverarbeiten. Ich habe mich aber entschieden, die Daten direkt ab der API in eine Delta Table zu speicher, so spare ich mir den Schritt mit der Speicherung der Daten im Data Lake. Das spart nebst Processing auch Storage-Kosten.
Für die nachfolgenden Schritte werden ein paar Python Libraries benötigt.
import requests
import json
import uuid
from datetime import datetime
from pyspark.sql.functions import lit, colDen API-Key habe ich wie schon erwähnt in einem KeyVault gespeichert, den hole ich mir ab und speichere ihn in einer Variable. Diesen Schritt muss man entsprechend an die eigene Umgebung anpassen.
api_key = dbutils.secrets.get("kv", "OpenWeatherApiKey")Die Daten werde ich noch mit einem aktuellen Zeitstempel anreichern und eine Load-ID vergeben. Die Load-ID erstelle ich via uuid.
load_id = str(uuid.uuid4())
utc_timestamp = datetime.utcnow()Die Bronze Tabellen erstelle ich für das Wetter (current) und die Luftverschmutzung (air_pollution) ohne Schema. Das Schema wird dann im Nachhinein via Schema-Evolution erstellt.
CREATE TABLE IF NOT EXISTS weather.bronze.current;
CREATE TABLE IF NOT EXISTS weather.bronze.air_pollution;Bei der Städtetabelle vergebe ich ein Schema, weil ich die Daten in einem Merge verarbeiten möchte, und dafür brauche ich schon ein Schema.
CREATE TABLE IF NOT EXISTS weather.bronze.cities
(Response MAP<STRING, STRING>,
LoadID STRING,
LoadTimeStamp TIMESTAMP,
City STRING,
Longitude STRING,
Latitude STRING
);Für den REST-Call habe ich mir eine kleine Funktion geschrieben.
def get_response(url):
try:
response = requests.get(url)
return response
except Exception as e:
print(e)
raiseDie Städtenamen lese ich aus der target_cities_tabelle in ein Dataframe und erstelle daraus dann eine Liste.
df_target_cities = spark.read.table(target_cities_table)
target_cities = df_target_cities.select("city").rdd.flatMap(lambda x: x).collect()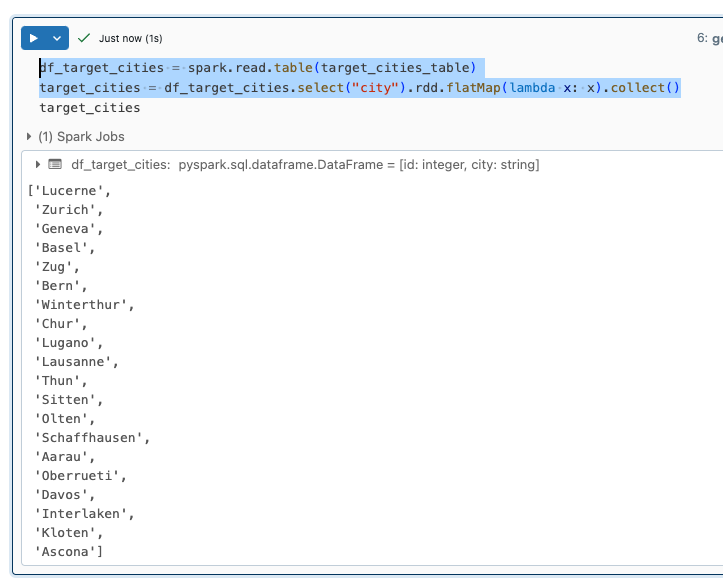
Anschliessend iteriere ich über die Städtenamen und mache für jede Stadt einen REST-Call. Innerhalb des Loops erstelle ich aus der Response ein Dataframe. Hierfür habe ich ebenfalls eine kleine Funktion geschrieben, in welcher zusätzlich noch der Ladezeitstempel und die Load-Id hinzugefügt werden. In SQL ist es so, dass man Daten in Batch verarbeiten sollte und nicht einzelne Rows. Also packe ich alle Dataframes aus dem Loop in ein einziges Dataframe zusammen. Die Daten für die Städte lade ich mir von folgender API: https://openweathermap.org/api/geocoding-api
def create_dataframe(response):
response_dict = json.loads(response.content)
df = spark.createDataFrame([response_dict])
df = (df
.withColumn("LoadID", lit(load_id))
.withColumn("LoadTimeStamp", lit(utc_timestamp))
)
return df
df_cities = None
for city in target_cities:
print(f"Load metadata for: {city}")
url = f"http://api.openweathermap.org/geo/1.0/direct?q={city}&&appid={api_key}"
response = get_response(url)
df = create_dataframe(response)
if df_cities is None:
df_cities = df
else:
df_cities = df_cities.unionByName(df, allowMissingColumns=True)Nachdem ich nun ein Dataframe für alle Responses für die Städte erstellt habe, transformiere ich das Dataframe so, dass der Städtename, Longitude und Latitude als zusätzliche Spalte hinzugefügt werden.
df_cities = (df_cities
.withColumnRenamed("_1", "Response")
.withColumn("City", col("Response")["name"])
.withColumn("Longitude", col("Response")["lon"])
.withColumn("Latitude", col("Response")["lat"])
)
display(df_cities)In der Regel ändern sich die Daten für die Städte nicht, darum will ich nicht alle Daten der Tabelle hinzufügen. Jedoch könnte sich etwas ändern, dann will ich die Änderungen in der Bronzetabelle haben. Oder es kommen neue Städte hinzu, dann sollen diese Daten hinzugefügt werden. Für diesen Anwendungsfall eignet sich ein SQL-Merge hervorragend. Den Merge könnte man entweder in PySpark oder in SQL schreiben. Ich bevorzuge SQL, da es ein bisschen weniger Code-Zeilen benötigt.
Dafür erstelle ich aus dem Dataframe einen Temporären View.
df_cities.createOrReplaceTempView("TempViewCities")Dieser View kann dann für den Merge verwendet werden.
%sql
MERGE INTO weather.bronze.cities AS target
USING TempViewCities AS source
ON target.City = source.City
AND target.Longitude = source.Longitude
AND target.Latitude = source.Latitude
WHEN MATCHED THEN
UPDATE SET *
WHEN NOT MATCHED THEN
INSERT *Wie aus dem Code ersichtlich, werden neue Städtedaten hinzugefügt, und bestehende updated.
Aus dieser Tabelle erstelle ich nun eine Liste mit den Städtenamen, Longitude und Latitude.
# Create a list of cities from the bronze.weather.cities table, containing Longitude and Latitude
cities_list = spark.sql("SELECT City, Longitude, Latitude FROM weather.bronze.cities").collect()
Diese Liste kann ich verwenden, um darüber zu iterieren und das Wetter abzufragen. Hierfür werden Longitude und Latitude benötigt. Ich rufe dafür die folgende API auf: https://openweathermap.org/current
Ähnlich wie bei den Städtedaten erstelle ich daraus ein Dataframe.
df_current = None
for c in cities_list:
print(f"Load current weather data for: {c.City}")
url = f"https://api.openweathermap.org/data/2.5/weather?lat={c.Latitude}&lon={c.Longitude}&appid={api_key}&units=metric"
response = get_response(url)
df = create_dataframe(response)
if df_current is None:
df_current = df
else:
df_current = df_current.unionByName(df, allowMissingColumns=True)Das Dataframe speichere ich nun direkt in eine Deltatable. Ich wähle die Option “mergeSchema” als true, so passt sich das Schema der Tabelle dem Dataframe an. Zusätzlich stelle ich ein, dass der Mode “append” ist, also die Daten hinzugefügt werden.
(
df_current.write.format("delta")
.mode("append")
.option("mergeSchema", "true")
.saveAsTable("weather.bronze.current")
)Das Prozedere wiederhole ich nun auch für die Luftverschmutzung.
df_air_pollution = None
for c in cities_list:
print(f"Load air pollution data for: {c.City}")
url = f"http://api.openweathermap.org/data/2.5/air_pollution?lat={c.Latitude}&lon={c.Longitude}&appid={api_key}"
response = get_response(url)
df = create_dataframe(response)
df = df.withColumn("City", lit(city))
if df_air_pollution is None:
df_air_pollution = df
else:
df_air_pollution = df_air_pollution.unionByName(df, allowMissingColumns=True)(
df_air_pollution.write.format("delta")
.mode("append")
.option("mergeSchema", "true")
.saveAsTable("weather.bronze.air_pollution")
)Bei den Bronzetabellen habe ich bewusst auf sämtliche Transformationen verzichtet und speichere die Daten so, wie sie ankommen. Hier das Beispiel für die Wetterdaten:

Bronze zu Silver
Bei der Verarbeitung von Bronze zu Silver werde ich die Daten transformieren. Ich muss zuerst ein paar Libraries importieren.
from pyspark.sql.functions import col, from_unixtime, to_timestampFür die Transformationen schreibe ich jeweils eine Funktion. Auch hier gibt es wieder mehrere Möglichkeiten. Man könnte zum Beispiel eine dynamische Funktion schreiben, welche alle verschachtelten Spalten ausglättet. Aber darauf habe ich bewusst verzichtet und glätte die Spalten manuell. Da die Originaldaten immer noch im Bronze gespeichert sind, könnte ich die Transformation im Nachhinein anpassen und neu in den Silver Layer laden.
def transform_columns_current(df):
"""
transforms the input dataframe for current weather data
- converts columns
- adds data from nested columns as additional columns
"""
df = (
df
.select(
col("base").alias("Base"),
# "clouds",
col("clouds")["all"].alias("Clouds_All"),
col("cod").alias("Cod"),
# "coord",
col("coord")["lon"].alias("Coord_Lon"),
col("coord")["lat"].alias("Coord_Lat"),
# "dt",
to_timestamp(from_unixtime(col("dt"))).alias("Weather_TimeStamp"),
col("id").alias("ID"),
# "main",
col("main")["feels_like"].alias("Main_Feels_Like"),
col("main")["temp_min"].alias("Main_Temp_Min"),
col("main")["pressure"].alias("Main_Pressure"),
col("main")["humidity"].alias("Main_Humidity"),
col("main")["temp"].alias("Main_Temp"),
col("main")["temp_max"].alias("Main_Temp_Max"),
col("name").alias("City"),
# "rain",
col("rain")["1h"].alias("Rain_1h"),
# "sys",
col("sys")["country"].alias("Sys_Country"),
col("sys")["id"].alias("Sys_ID"),
to_timestamp(from_unixtime(col("sys")["sunrise"])).alias("Sys_Sunrise"),
to_timestamp(from_unixtime(col("sys")["sunset"])).alias("Sys_Sunset"),
col("sys")["type"].alias("Sys_Type"),
col("timezone").alias("Timezone"),
col("visibility").alias("Visibility"),
# "weather",
# col("weather")[0],
col("weather")[0]["icon"].alias("Weather_0_Icon"),
col("weather")[0]["description"].alias("Weather_0_Description"),
col("weather")[0]["main"].alias("Weather_0_Main"),
col("weather")[0]["id"].alias("Weather_0_ID"),
# "wind",
col("wind")["speed"].alias("Wind_Speed"),
col("wind")["deg"].alias("Wind_Deg"),
"LoadID",
"LoadTimeStamp"
)
)
return dfDie auskommentierten Spalten dienten zum erstellen der Funktion, die habe ich mal so stehen gelassen. Ebenfalls sieht man die Transformation des Unix-Zeit-Stempels in einen timestamp-Type.
to_timestamp(from_unixtime(col("dt"))).alias("Weather_TimeStamp"),Bei den Transformationen für die Luftverschmutzung bin ich gleich vorgegangen.
def transform_columns_air_pollution(df):
"""
transforms the input dataframe for air_pollution
- converts columns
- adds data from nested columns as additional columns
"""
df = (
df
.select(
col("City"),
# col("coord").alias("Coord"),
col("coord")["lon"].alias("Coord_Lon"),
col("coord")["lat"].alias("Coord_Lat"),
# col("list")[0].alias("list"),
col("list")[0]["dt"].alias("List_dt"),
# col("list")[0]["components"].alias("List_Components"),
col("list")[0]["components"]["pm2_5"].alias("List_Components_pm2_5"),
col("list")[0]["components"]["pm10"].alias("List_Components_pm10"),
col("list")[0]["components"]["no2"].alias("List_Components_no2"),
col("list")[0]["components"]["co"].alias("List_Components_co"),
col("list")[0]["components"]["nh3"].alias("List_Components_nh3"),
col("list")[0]["components"]["o3"].alias("List_Components_o3"),
col("list")[0]["components"]["no"].alias("List_Components_no"),
col("list")[0]["components"]["so2"].alias("List_Components_so2"),
col("list")[0]["main"]["aqi"].alias("List_main_aqi"),
"LoadID",
"LoadTimeStamp")
)
return dfUnd ebenfalls für die Städte-Informationen ein paar kleine Transformationen.
def transform_columns_cities(df):
"""
transforms the input dataframe for cities
- converts columns
- adds data from nested columns as additional columns
"""
df = (
df
.select(
col("City"),
col("Longitude"),
col("Latitude"),
col("Response").alias("Response"),
col("Response")["state"].alias("State"),
col("Response")["country"].alias("Country"),
"LoadID",
"LoadTimeStamp")
)
return dfDie Funktionen können nun aufgerufen werden, nachdem die Daten aus der Bronzetabelle in ein Dataframe geladen werden, um sie zu transformieren und dann das transformierte Dataframe in eine Silbertabelle gespeichert werden.
Der Punkt hier ist, dass bei einem klassischen Batch-Ansatz immer die gesamte Bronze-Tabelle geladen werden muss, transformiert wird, und dann die Silber-Tabelle überschrieben werden muss. Oder man müsste einen Mechanismus implementieren, welcher nur die Daten aus der Bronze lädt, welche noch nicht in die Silber-Tabelle verarbeitet wurden. Das könnte man entweder mit Zeitstempeln oder der Load-ID bewerkstelligen. Das ist aber aufwändiger. Und wie gesagt, möchte ich nur das Delta verarbeiten und nicht immer die gesamte Tabelle. Das würde die Ausführungszeit immer länger werden lassen. Aus diesem Grund habe ich mich entschieden, die Daten mittels Spark Structured Streaming zu verarbeiten. Dabei werden nur die Daten verarbeitet, welche noch nicht in die Silber-Tabelle transformiert wurden. Mittels Streaming merkt sich das System selber, wo es beim letzten Load aufgehört hat zu arbeiten. Dies ist auch der Grund, wieso ich am Anfang ein Volume erstellt habe. Im Volume gebe ich einen Pfad an, wo Spark sich die Checkpoints vom Stream abspeichert.
Im ersten Schritt wird die Bronze-Tabelle als Stream eingelesen.
bronze_stream_weather = (spark
.readStream
.table("weather.bronze.current")
)Dann wird die Transformation auf das Streaming-Dataframe angewendet.
bronze_stream_weather = transform_columns_current(bronze_stream_weather)Und in einem 3. Schritt werden die Daten als Stream in eine Silber-Delta Tabelle gespeichert.
silver_stream_weather = (bronze_stream_weather
.writeStream
.format("delta")
.outputMode("append")
.option("checkpointLocation", f"/Volumes/weather/silver/checkpoints/currrent_weather/_checkpoint")
.trigger(once=True)
.toTable("weather.silver.current")
)
silver_stream_weather.awaitTermination()Sobald alle Daten verarbeitet wurden, beendet sich der Stream von selbst.
Dasselbe Prozeder wiederhole ich dann für die anderen Tabellen.
bronze_stream_air_pollution = (spark
.readStream
.table("weather.bronze.air_pollution")
)
bronze_stream_air_pollution = transform_columns_air_pollution(bronze_stream_air_pollution)
silver_stream_air_pollution = (bronze_stream_air_pollution
.writeStream
.format("delta")
.outputMode("append")
.option("checkpointLocation", f"/Volumes/weather/silver/checkpoints/air_pollution/_checkpoint")
.trigger(once=True)
.toTable("weather.silver.air_pollution")
)
silver_stream_air_pollution.awaitTermination()bronze_stream_cities = (spark
.readStream
.table("weather.bronze.cities")
)
bronze_stream_cities = transform_columns_cities(bronze_stream_cities)
silver_stream_cities = (bronze_stream_cities
.writeStream
.format("delta")
.outputMode("append")
.option("checkpointLocation", f"/Volumes/weather/silver/checkpoints/cities/_checkpoint")
.trigger(once=True)
.toTable("weather.silver.cities")
)
silver_stream_cities.awaitTermination()Silver zu Gold
Den Benutzern gebe ich nicht direkten Zugriff auf die Silber Tabellen. Dafür sind die Views und Tabellen in Gold angedacht. Man kann auch unterschiedliche Gold-Tabellen anlegen auf die zugrundeliegenden Silber-Tabellen, je nach Use Case. Ich könnte jetzt wiederum die Daten von Silber nach Gold streamen und als Tabelle speichern. Aber für diesen kleinen Use-Case werde ich mich mit einem kleinen View begnügen. Falls die Performance nicht ausreicht, kann im Nachhinein immer noch eine persistierte Tabelle erstellt werden.
Weitere Anmerkungen: In meinem Beispiel habe ich bewusst auf eine dimensionale Modellierung verzichtet. Das heisst, ich habe keine Fakten- und Dimensions-Tabellen implementiert sondern die Tabellen als einen gejointen View zusammengezogen. Das wäre ein anderes Kapitel, welches ich mal in einem Blog-Post beschreiben werde. Im Zentrum des Posts liegt hier der Fokus auf der OpenWeather-API.
Das Notebook für die Erstellung des Views ist denkbar klein, und ich habe es in SQL erstellt.
CREATE OR REPLACE VIEW weather.gold.weather
AS
SELECT
c.City,
c.Longitude,
c.Latitude,
c.State,
c.Country,
w.Clouds_All,
w.Weather_TimeStamp,
w.Main_Feels_Like,
w.Main_Temp_Min,
w.Main_Temp,
w.Main_Temp_Max,
w.Rain_1h,
w.Sys_Sunrise AS Sunrise,
w.Sys_Sunset AS Sunset,
w.Visibility,
w.Wind_Speed,
w.Wind_Deg
FROM weather.silver.current AS w
INNER JOIN weather.silver.cities AS c
ON c.City = w.CityHier könnte man sicher noch diverse Verbesserungen machen.
Job erstellen
Damit ich regelmässig die Daten von der API laden kann, packe ich meine 3 Notebooks in einen Job. Hierfür gehe ich in den Tab Workflows und klicke “Create Job”.

Für jedes Notebook erstelle ich einen separaten Task, welche nacheinander ausgeführt werden.
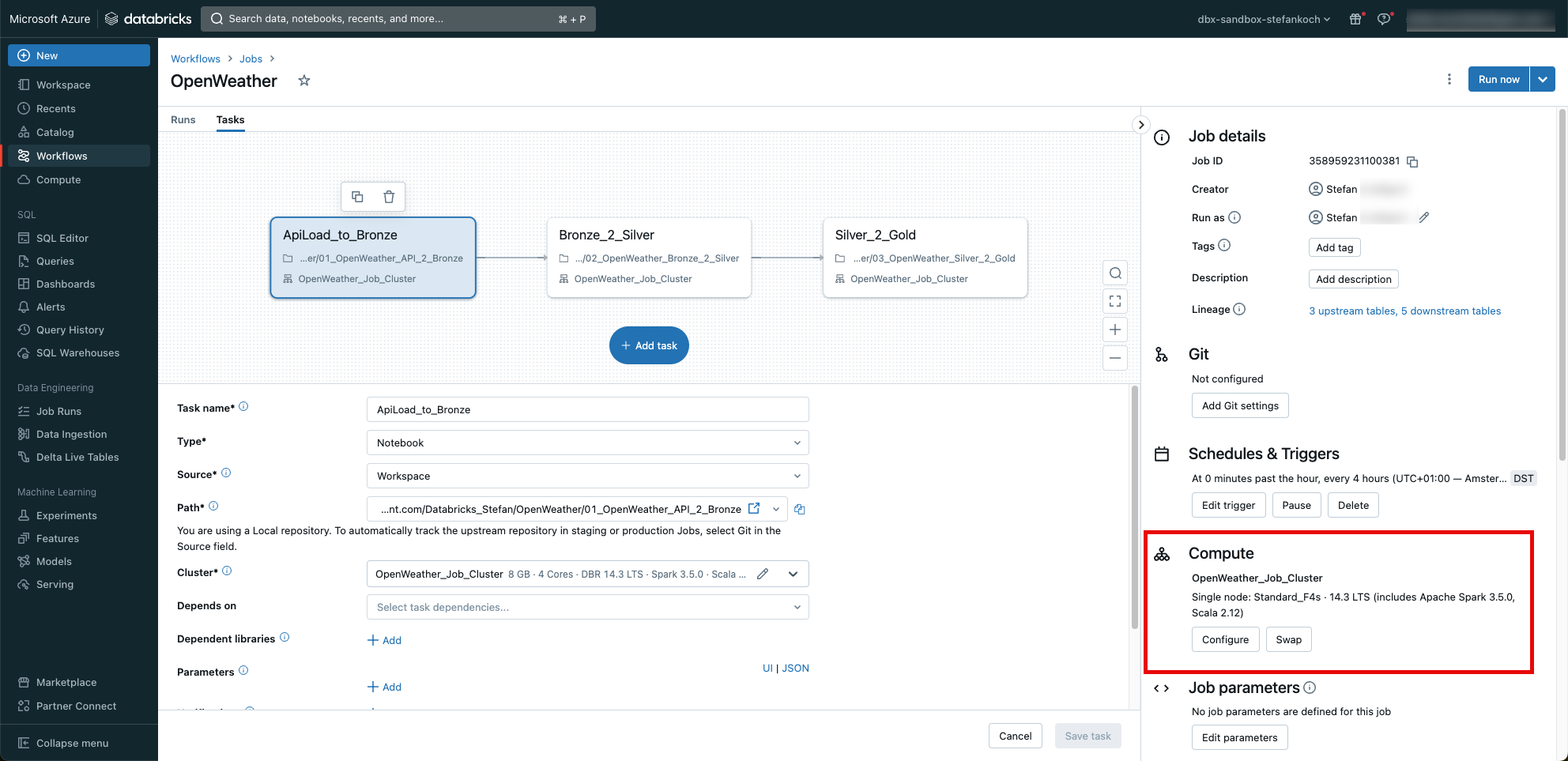
Den Job triggere ich alle 4 Stunden. Und ganz wichtig, ich verwende nicht den “General-Purpose”-Cluster, sondern einen Job-Cluster. Dieser terminiert sich nach dem Job automatisch und generiert keine weiteren Kosten.
Natürlich werden sämtliche Runs protokolliert und können überwacht werden.
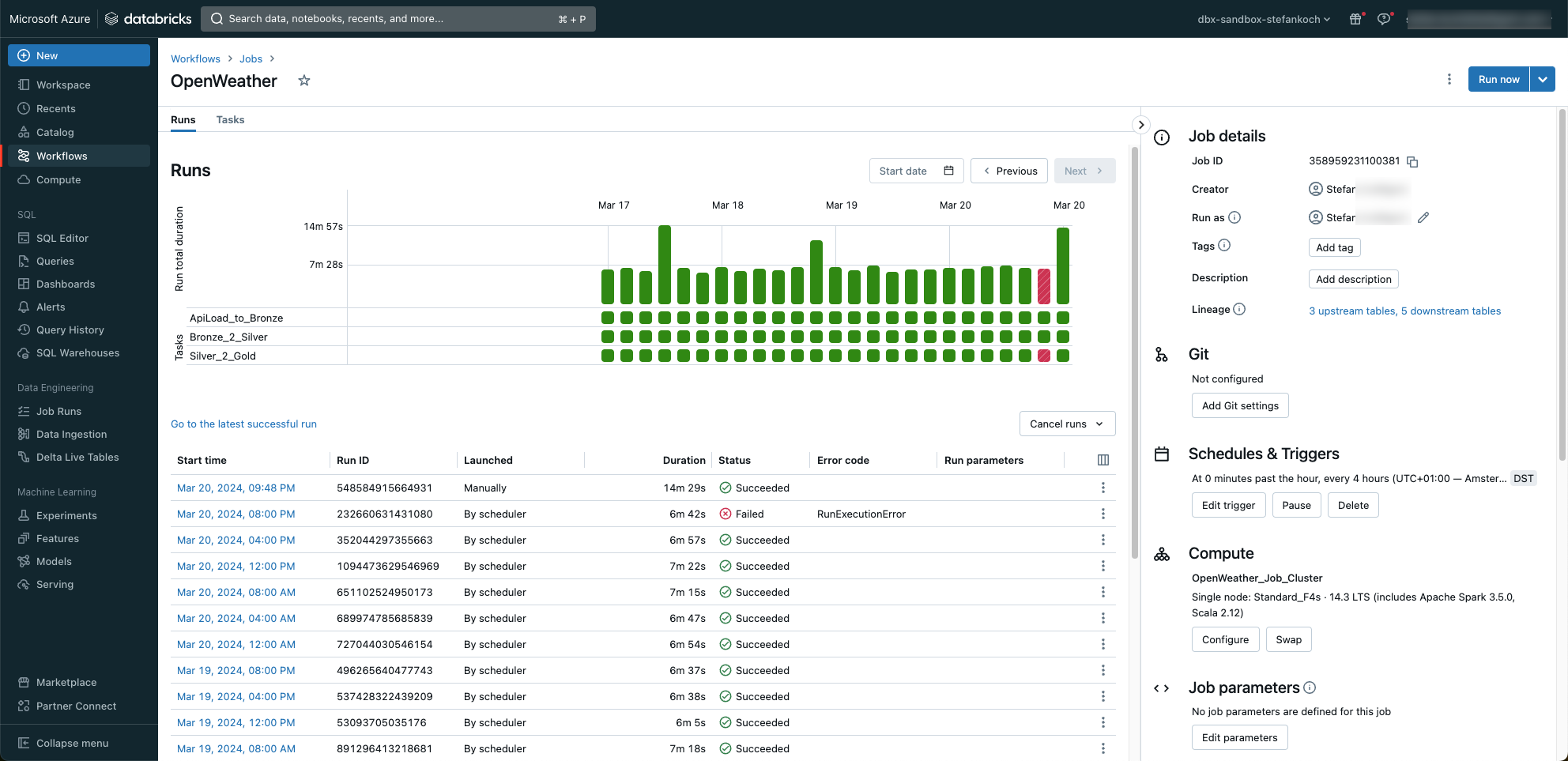
Wie zu erkennen ist, habe ich an einem Notebook herumgebastelt, als ein Job gestartet wurde. 😉
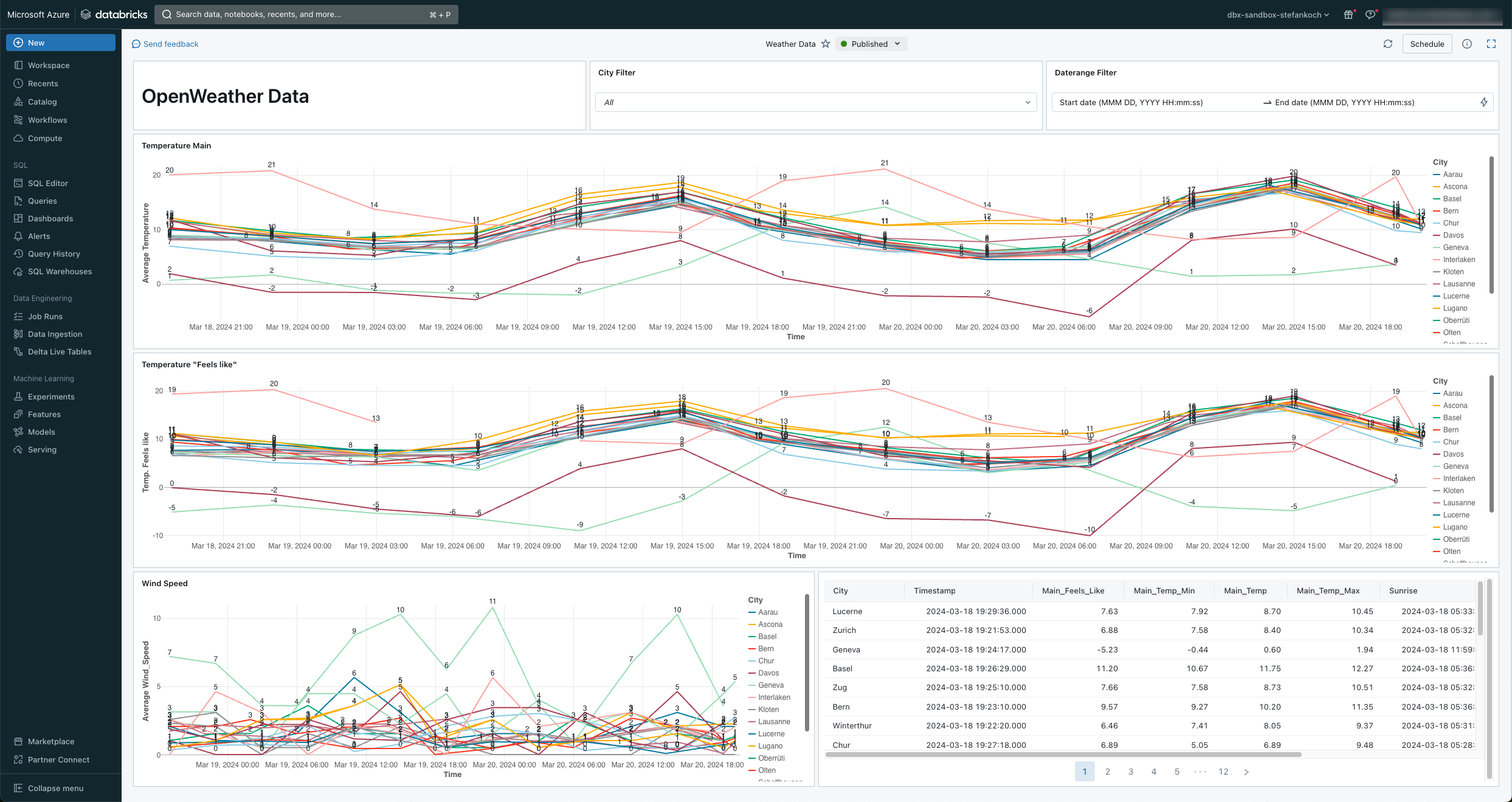
Lakeview Dashboard
Am Schluss habe ich mir noch ein einfaches Lakeview Dashboard direkt auf meine Daten gesetzt.