
So erstellst du ein Azure Databricks Lakehouse inkl. Unity Catalog, DataLake und KeyVault – Schritt für Schritt
In dieser Schritt-für-Schritt-Anleitung beschreibe ich, wie man in der Azure Cloud eine Databricks Lakehouse Umgebung innerhalb von 30 Minuten erstellt. Diese Anleitung richtet sich an Personen, welche neu im Thema Databricks sind und eine Umgebung für einen Proof of Concept oder zum Üben erstellen möchten.
Weiterlesen: So erstellst du ein Azure Databricks Lakehouse inkl. Unity Catalog, DataLake und KeyVault – Schritt für SchrittNatürlich kann man die erste Schritte mit Databricks mit der Community Edition von Databricks unternehmen, welche gratis zur Verfügung gestellt wird. Jedoch hat diese Umgebung verschiedene Limitationen, zum Beispiel kein Unity Catalog und verschiedene andere Funktionalitäten fehlen ebenfalls. Darum empfehle ich jeweils, ein Databricks Setup in der eigenen Umgebung zu erstellen, in welcher man alle Funktionalitäten testen kann. Für den Betrieb werden keine grossen Kosten generiert, da für die meisten Tests kleine Cluster verwendet werden können.
Ich weise darauf hin, dass das Ziel dieser Anleitung ist, eine Umgebung schnell aufzubauen. In einer produktiven Umgebung würde man keine manuelle Setups machen, sondern die jeweiligen Ressourcen mit IaC Frameworks wie Terraform erstellen.
Bevor mit dem eigentlichen Setup begonnen wird, braucht es eine Azure Subscription, in welcher man die entsprechenden Ressourcen erstellen kann. Falls du noch nie mit Azure gearbeitet hast, lohnt es sich, diesen Artikel durchzulesen: https://stefanko.ch/erste-schritte-mit-der-azure-cloud/. Als Ausgangslage setze ich voraus, dass eine funktionierende Subscription in der Azure Cloud vorhanden ist.
Contents
- 1 Medallion Architektur
- 2 Ressourcengruppe
- 3 Databricks Workspace erstellen
- 4 Storage Account erstellen
- 5 Berechtigungen auf dem Data Lake setzen
- 6 Setup im Databricks Workspace
- 7 Metastore erstellen
- 8 Catalog Objekte erstellen
- 9 Externe Locations erstellen
- 10 Kataloge erstellen
- 11 Schema’s erstellen
- 12 Volumes erstellen
- 13 Dateien in ein Volume hochladen
- 14 Azure KeyVault erstellen
- 15 Secret Scope in Databricks erstellen
- 16 Cluster erstellen
- 17 Secrets vom KeyVault lesen
- 18 Fazit
Medallion Architektur
Beim Setup lehne ich mich an die Medallion-Architektur von Databricks an:

Die Architektur erweitere ich um zwei weitere Zonen, die “Landing-Zone” und die “Raw-Zone”. Diese werden, wie der Name es schon suggeriert entsprechend eingesetzt.
Landing-Zone: Anlieferung von Dateien von Dritt-Systemen. Diese Zone ist transient, das heisst die Daten werden nur zwischengespeichert, von der Datenpipeline verarbeitet und die Dateien entweder in Raw verschoben oder nur der Inhalt in Bronze gespeichert. Nach der Verarbeitung werden die Daten in der Landing-Zone gelöscht.
Raw-Zone: Hier werden die Rohdaten gespeichert. Das heisst, die Dateien, so wie sie angeliefert werden, gespeichert. Dies bietet den Vorteil, dass zu einem späteren Zeitpunkt immer auf die entsprechenden Original-Daten zugegriffen werden können.
Wann die Daten in Raw oder Landing geschrieben werden, hängt vom entsprechenden Use Case ab. Für bestimmte Szenarien können diese Zonen auch komplett übersprungen werden, und die Daten direkt in Bronze geschrieben werden. Nachfolgend eine schematische Darstellung der Zonen:

Beim nachfolgenden Setup werden wir für die jeweiligen Zonen einen eigenen Storage Container erstellen.
Ressourcengruppe
Als erster Schritt erstelle ich eine Ressourcengruppe, in welcher der Workspace und der Storage Account deployt werden. Zu diesem Zweck klicke ich auf “Create a resource”.
Im Suchfeld kann nach “resource group” gesucht werden, wo dann die Vorschläge eingeblendet werden. Mit einem Klick auf die entsprechende Ressourcen, geht es dann zu den Einstellungen.

Ich benenne die Ressourcengruppe als “rg-databricks”. Natürlich können andere Namen verwendet werden. Als Standort verwende ich die Region “North Europe”. Ich bin zwar in der Schweiz ansässig, somit wäre eine Region in “Switzerland North” oder “Switzerland West” zwar näher, jedoch sind die Regionen in Europa ein bisschen kostengünstiger. Alle nachfolgenden Ressourcen erstelle ich ebenfalls in dieser Region.
Ebenfalls muss man sich ein Konzept erstellen, wie die jeweiligen Azure Ressourcen benannt werden. Ich richte mich meistens nach den offiziellen Empfehlungen von Microsoft: https://learn.microsoft.com/en-us/azure/cloud-adoption-framework/ready/azure-best-practices/resource-abbreviations
In den nachfolgenden Schritte werde ich jeweils diese Namenskonvention einhalten.
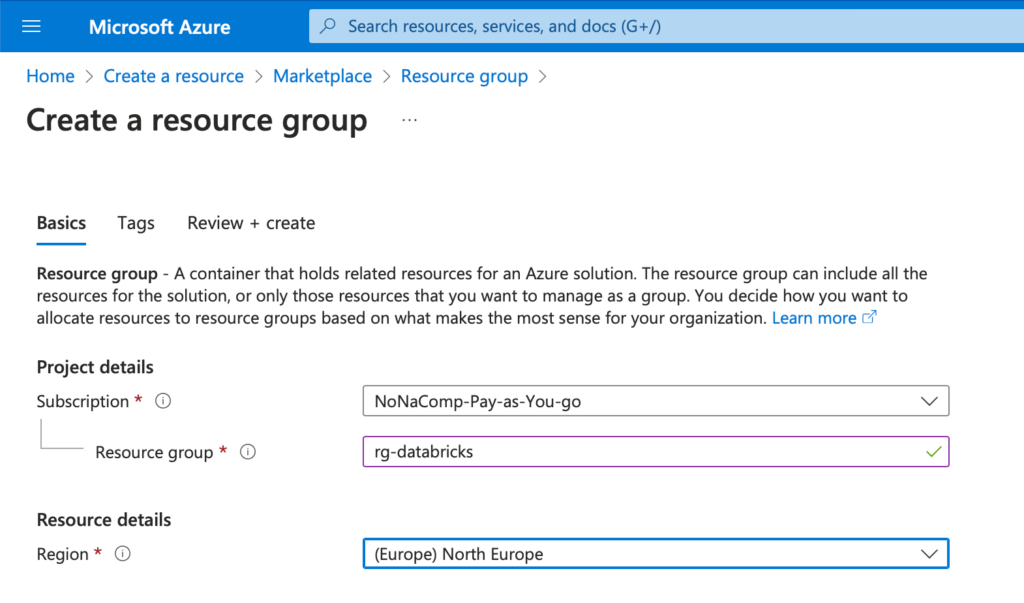
Alle weiteren Einstellungen kann man belassen und dann auf “Create” klicken.

Databricks Workspace erstellen
Nachdem die Ressourcengruppe erstellt worden ist, wechsle ich in die Ressourcengruppe. Oben Links befindet sich ein Button, mit welchem man neue Ressourcen erstellen kann.
Ich suche nach Databricks und wähle die Ressource “Azure Databricks” aus.

Beim Workspace-Namen vergebe ich entsprechend einen sinnvollen Namen. Ich habe ein Beispiel einer fiktiven Firma “NoNameCompany”, welche ich abgekürzt “nonacomp” nenne. Die Region wie Vorgangs schon erwähnt, wähle ich aus wie die Ressourcengruppe.
🚨🚨🚨 Achtung! Beim Pricing-Tier umbedingt Premium auswählen! 🚨🚨🚨
Ansonsten stehen im Workspace nicht alle Funktionalitäten zur Verfügung und auch Unity Catalog kann man mit der Standard-Version nicht verwenden.
Bei der Erstellung vom Databricks Workspace wird eine zusätzliche, “Managed Resourcegroup” erstellt. In dieser befinden sich Ressourcen, welche automatisch erstellt und die für den Betrieb benötigt werden. Ich verwende einen ähnlichen Namen dafür wie die ursprüngliche Ressourcengruppe, indem ich ein m voranstelle, als “mrg-databricks”.
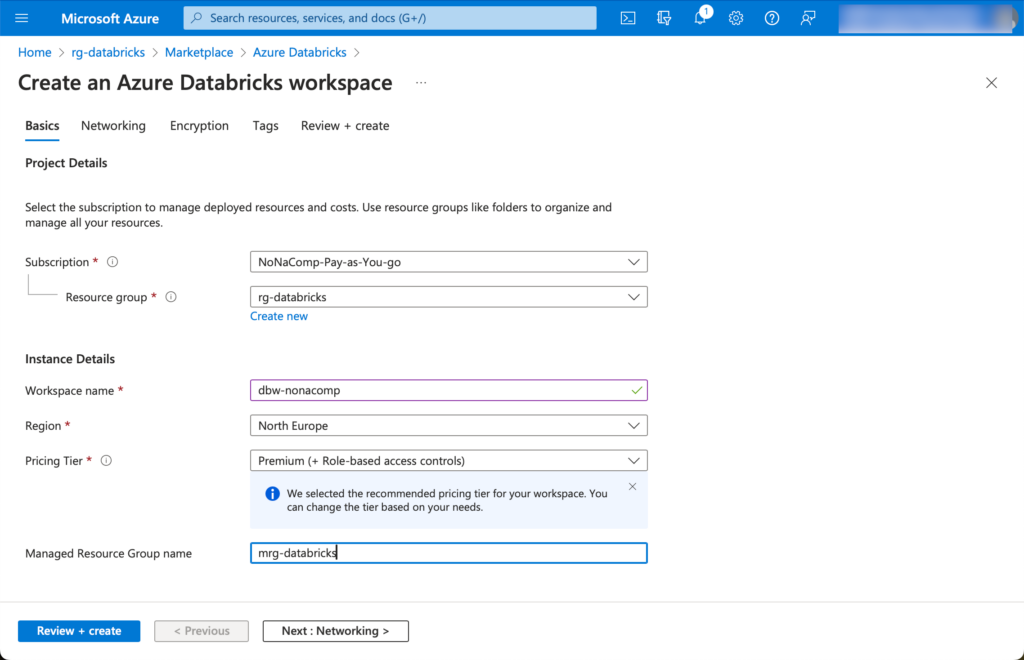
Die restlichen Einstellungen für den Workspace können so belassen werden, wie sie vorgeschlagen werden.

Storage Account erstellen
Für die Erstellung des Storage Accounts wechseln wir wiederum in die Ressourcengruppe und klicken auf “Create”.
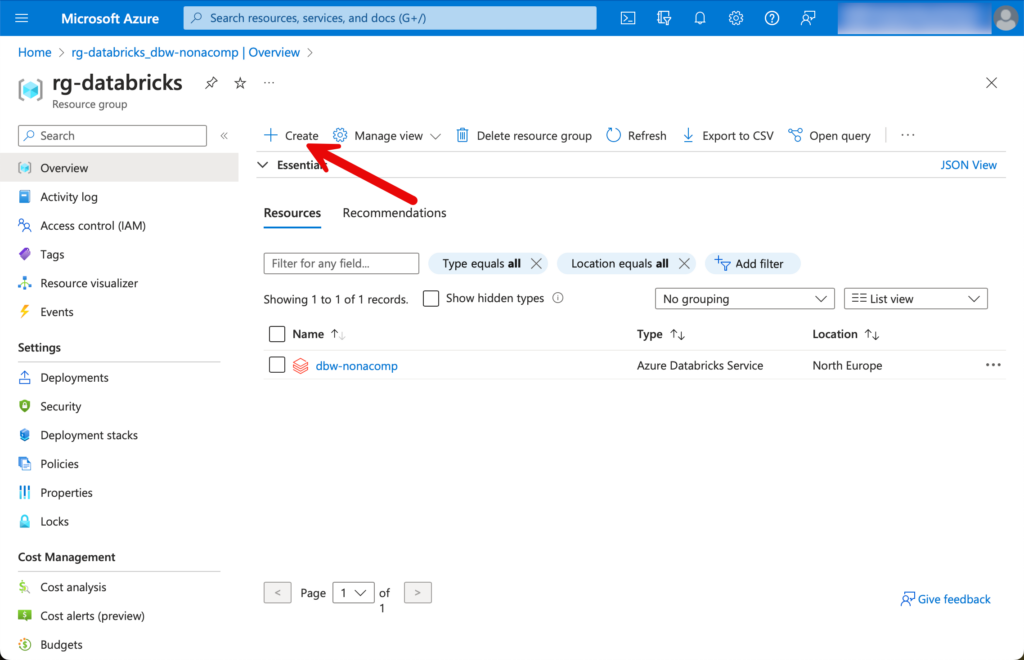
Ich suche nach “Storage Account” und wähle diese Ressource aus.
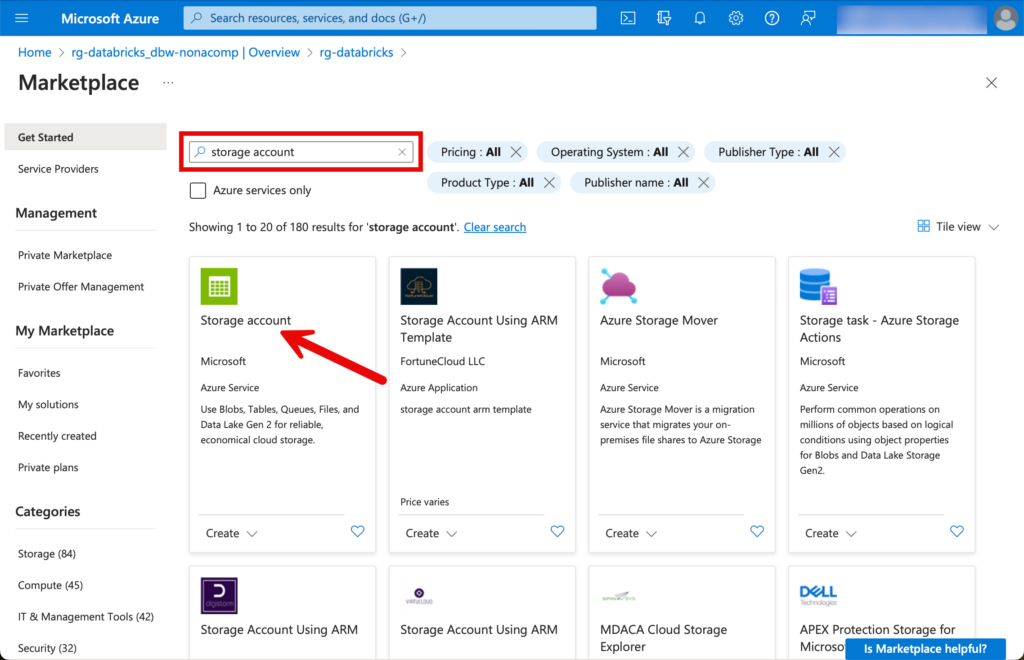
Beim nachfolgenden Setup handelt es sich um ein einfaches Beispiel. In einem PoC oder einer Übungs-Umgebung ist das völlig ausreichend. In einer produktiven Umgebung sollten zusätzliche Security-Überlegungen einbezogen werden.
Aus Kostengründen wähle ich bei der Performance “Standard” und bei der Redundancy LRS.

🚨🚨🚨 Wichtig: “Enable hierarchical namespace” muss zwingend aktiviert werden! 🚨🚨🚨
Alle weiteren Einstellungen übernehme ich wie vorgeschlagen und klicke dann auf “Create”.

Wenn der Storage Account deployt wurde, müssen als nächstes die Container erstellt werden. Dazu kann im Kontext vom Storage Account auf den Reiter “Containers” gewechselt werden.

Hier im Beispiel erstelle ich den Container für die Landing-Zone.

Der Schritt wird für alle Container wiederholt. Zusätzlich zu den erwähnten Zonen erstelle ich auch noch einen Container “temp” und einen Container “catalogs”. temp, wie der Name es schon suggeriert, wird für temporäre Objekte benutzt. Den Container catalogs verwende ich, um diese als Storage für die Kataloge in Databricks zur Verfügung zu stellen.

Berechtigungen auf dem Data Lake setzen
Damit mit den Daten in den Containern gearbeitet werden kann, müssen entsprechende Berechtigungen gesetzt werden. Die Governance und der Zugriff hierbei wird mit Unity Catalog realisiert. Somit müssen die jeweiligen Benutzer nicht direkt auf dem Datalake berechtigt werden, sondern können zentral in Unity Catalog administriert werden. Damit Unity Catalog die Berechtigungen verwalten kann, muss die Ressource “Access Connector for Azure Databricks” auf den Storage berechtigt werden. Diese Ressource wurde automatisch mit dem Setup von Databricks erstellt und befindet sich in der “Managed Resourcegroup”. Man findet die Ressource, wenn man in diese Ressourcengruppe hineinschaut.


Ich wechsle zurück zu dem Storage Account und wechsle auf den Tab “Access Control (IAM)”. Dort klicke ich auf “Add” und dann “Role Assignment”.
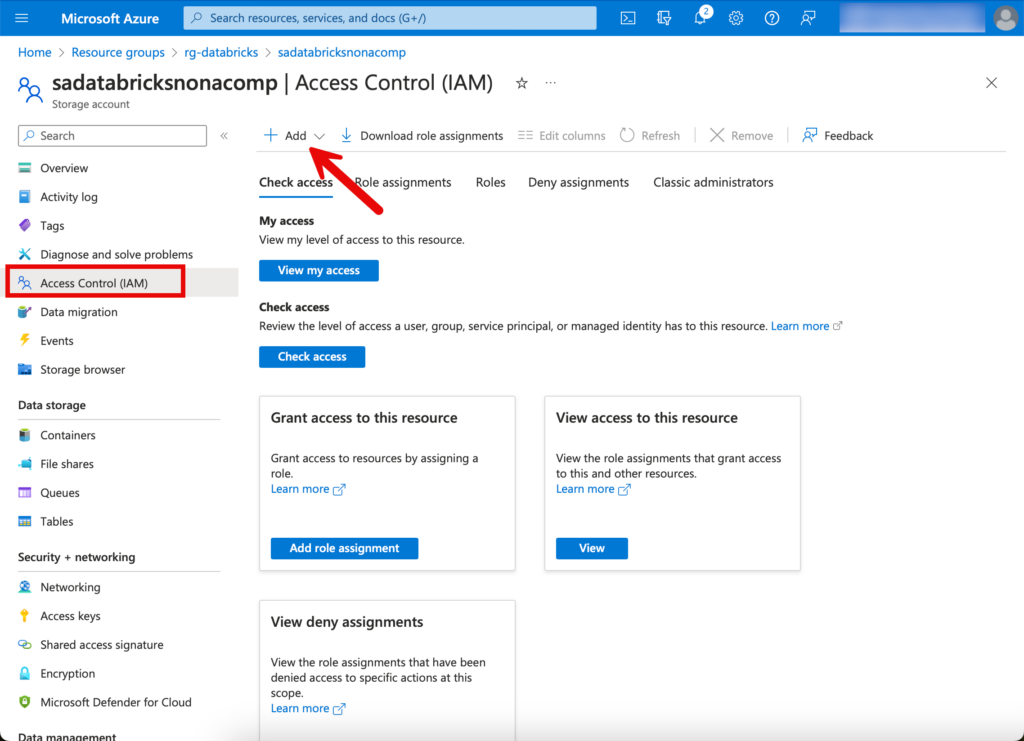

Ich suche nach der Rolle “storage blob data contributor”.

Beim Tab Members klicke ich auf “Managed Identity”, Select members und suche nach dem Access Connector.
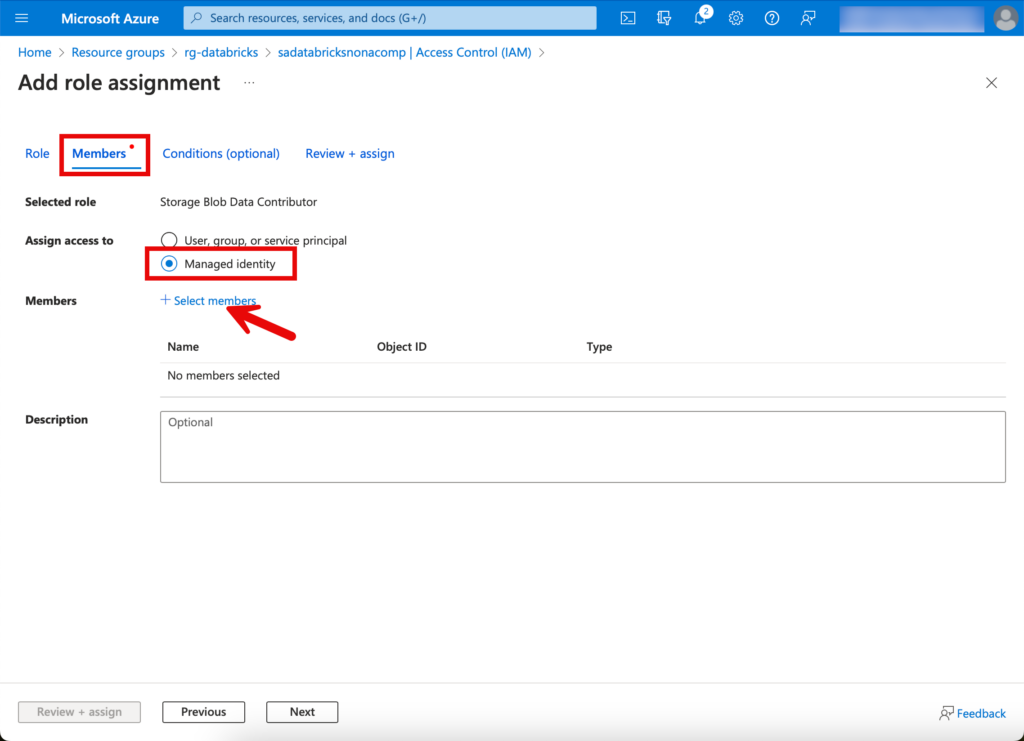
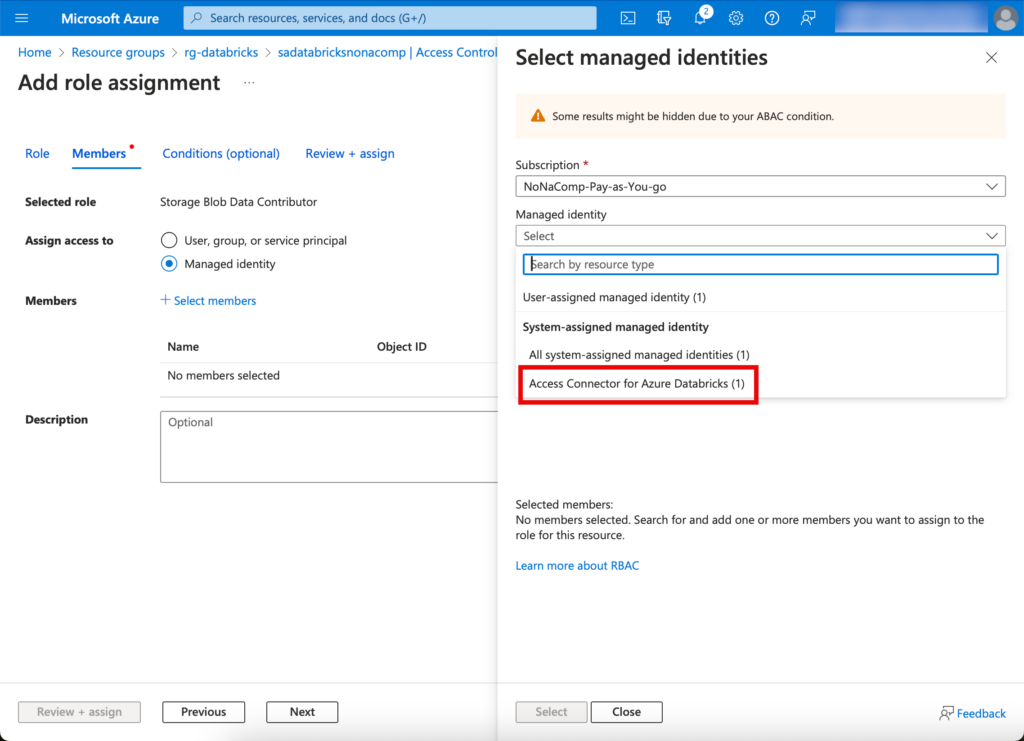

Abschliessend auf “Review & Assign” klicken, somit haben wir die entsprechenden Berechtigungen schon gesetzt.
Setup im Databricks Workspace
Nun logge ich mich in den Databricks Workspace ein. Dies kann via der Ressource im Azure Portal gemacht werden.

Es öffnet sich ein weiterer Browser-Tab, in welchem sich die GUI des Workspaces befindet.

Damit das Setup von Unity Catalog gemacht werden kann, muss man sich in den Databricks Account einloggen. Dies geschieht, indem auf den entsprechenden Menü-Punkt von meinem Benutzer geklickt wird.
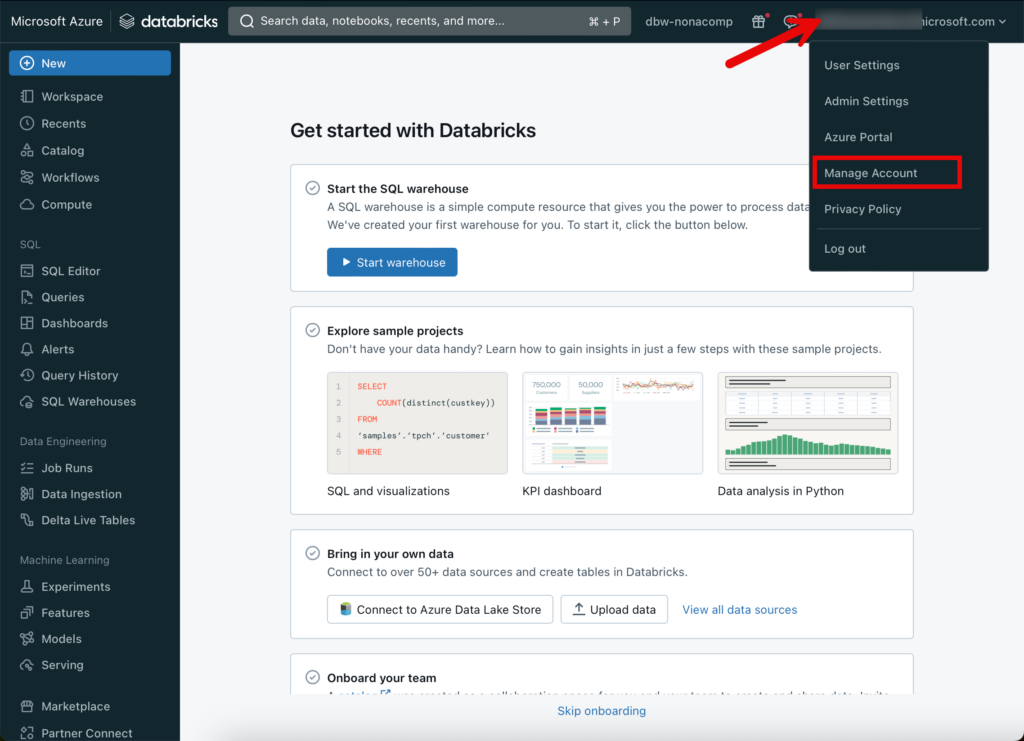
Wiederum öffnet sich ein weiterer Tab, in welchem sich die Account Console befindet. Der Übersichtlichkeit halber stelle ich ein, dass das Menü auf der linken Seite immer expandiert wird.


Mit dieser Einstellung werden die Menü-Punkte immer schön eingeblendet.
Metastore erstellen
Das oberste Objekt im Unity Catalog ist der Metastore. Dieser kann unter dem Menü “Data” erstellt werden.

Pro Region kann nur ein Metastore erstellt werden. Ich wähle dieselbe Region wie meine Azure Ressourcen.
Der Pfad zu einem ADLS Gen 2 path lasse ich aus, ebenfalls die Access Connector id.

Im nächsten Schritt werde ich den neu erstellten Metastore dem Databricks Workspace zuordnen, welchen ich vorrangig erstellt habe.
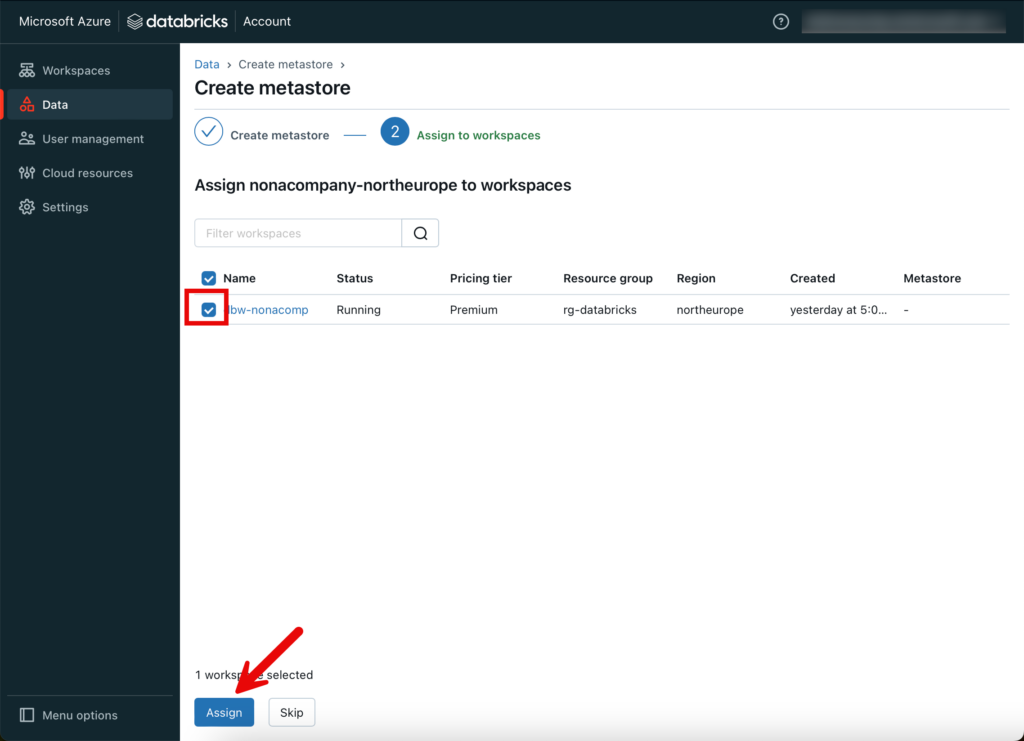
Catalog Objekte erstellen
Nachdem der Metastore erstellt worden ist, wechsle ich wieder in den Databricks Workspace. Für das erstellen der Catalog-Objekte wechsle ich auf den entsprechenden Menü-Punkt. Da ich einstellen möchte, wo sich welche Objekte befinden, werde ich entsprechende Objekte in “External Data” erstellen.
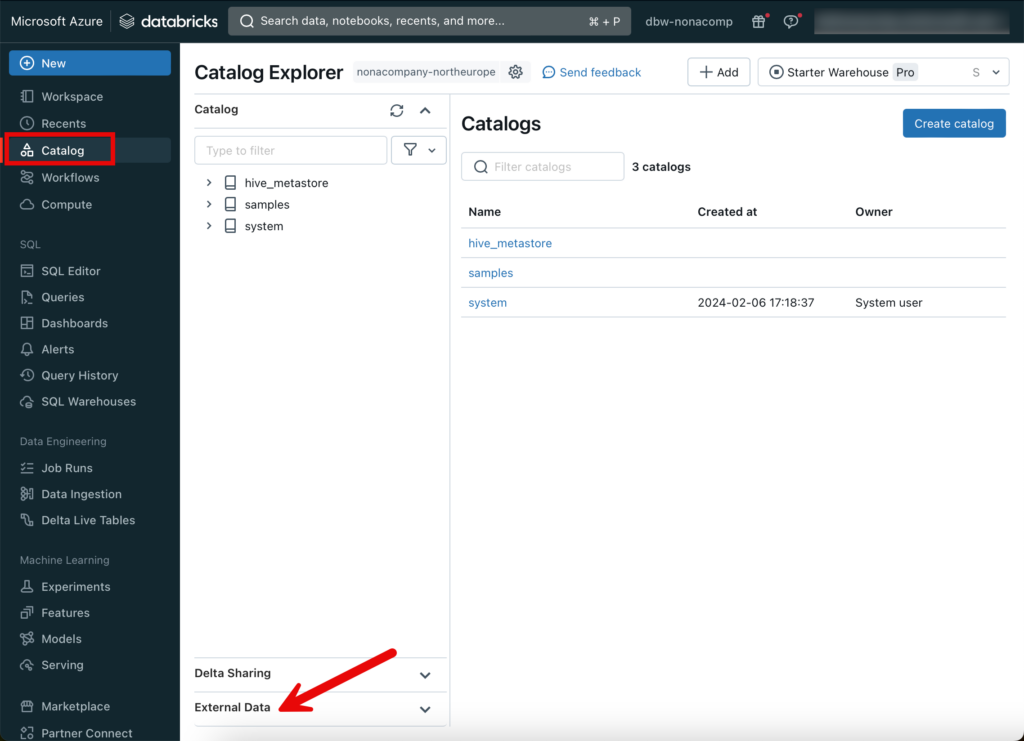
Als erstes benötige ich ein “Storage Credential”.
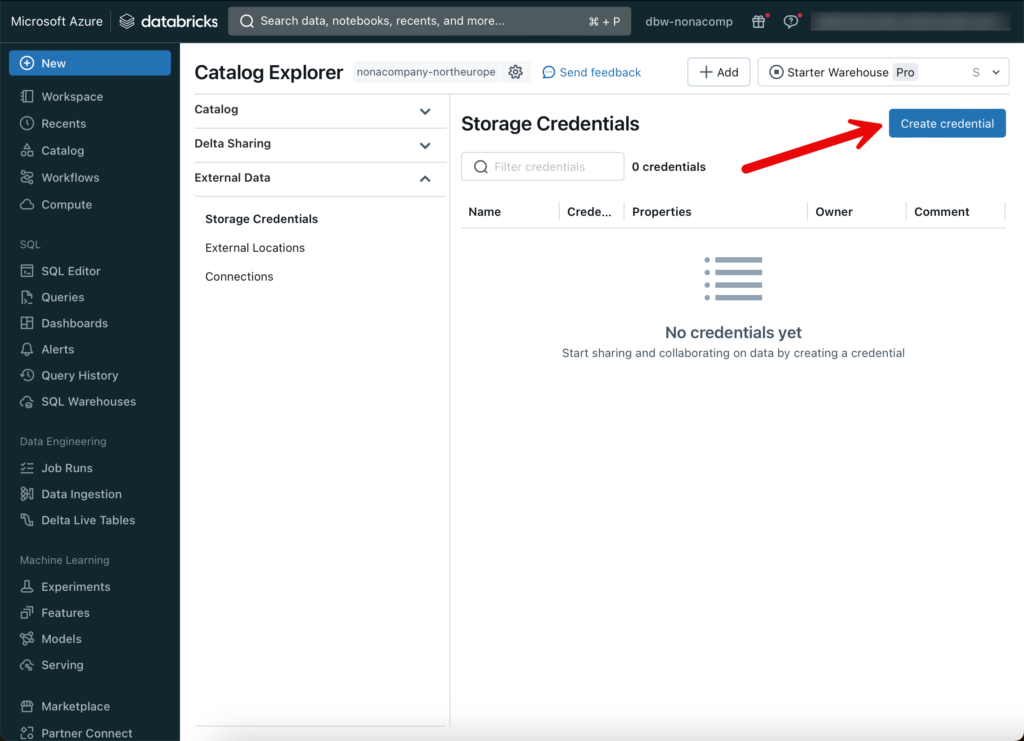
Hier trage ich die Details von der Ressource “Access Connector for Azure Databricks” ein.
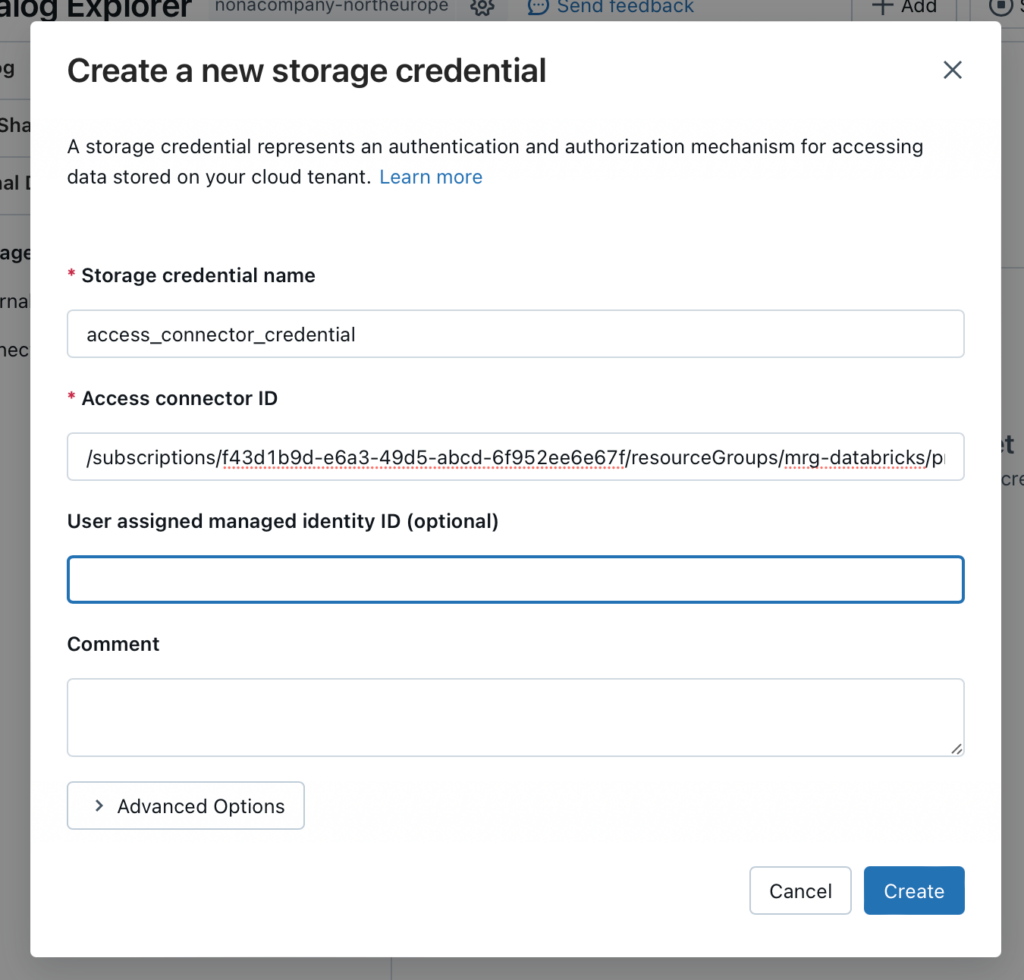
Die Access Connector ID sieht man, wenn man in den Properties von der Access Connector Ressource in der Managed Resource Group nachschaut:
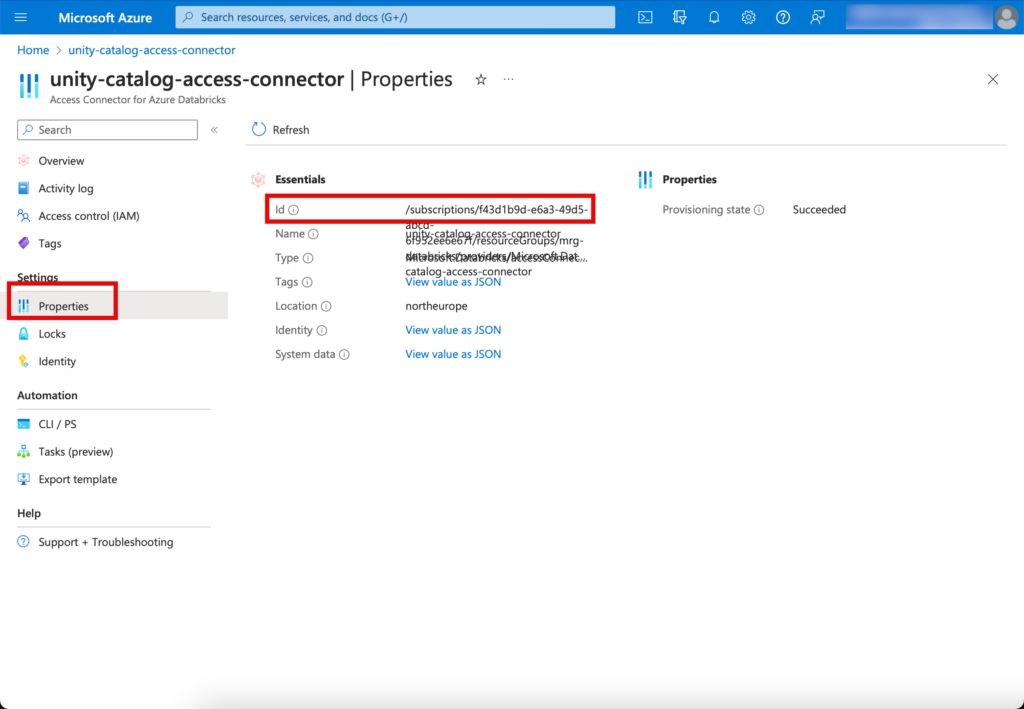
Anschliessend auf “Create” klicken, wenn die entsprechenden Informationen eingetragen wurden.
Externe Locations erstellen
Für sämtliche Zonen erstelle ich eine separate, externe Location.

Die URL für die externe Location wird nach folgendem Muster erstellt:
abfss://[container_name]@[storage_account_name].dfs.core.windows.net/[path]
Die Werte für [container_name], [storage_account_name] und [path] müssen dem jeweiligen Storage Account angepasst werden. In meinem Beispiel sieht es dann so aus:
abfss://raw@sadatabricksnonacomp.dfs.core.windows.net/
Den Wert für [path] lasse ich weg, da ich direkt auf dem Root-Verzeichnis des jeweiligen Containers aufsetze.

Um zu testen, ob alles richtig konfiguriert wurde, kann auf “Test connection” geklickt werden.

Wenn alles korrekt aufgesetzt wurde, wird eine entsprechende Meldung generiert.

Jetzt wiederhole ich den Schritt für alle external Locations. Am Schluss sollten folgende External Locations vorhanden sein:

Kataloge erstellen
In meinem Beispiel werde ich einen Katalog erstellen. Diesen benenne ich nach meiner fiktiven Unternehmung NoNaCompany.

Bei der Storage Location wähle ich die Storage Location “catalogs” aus.
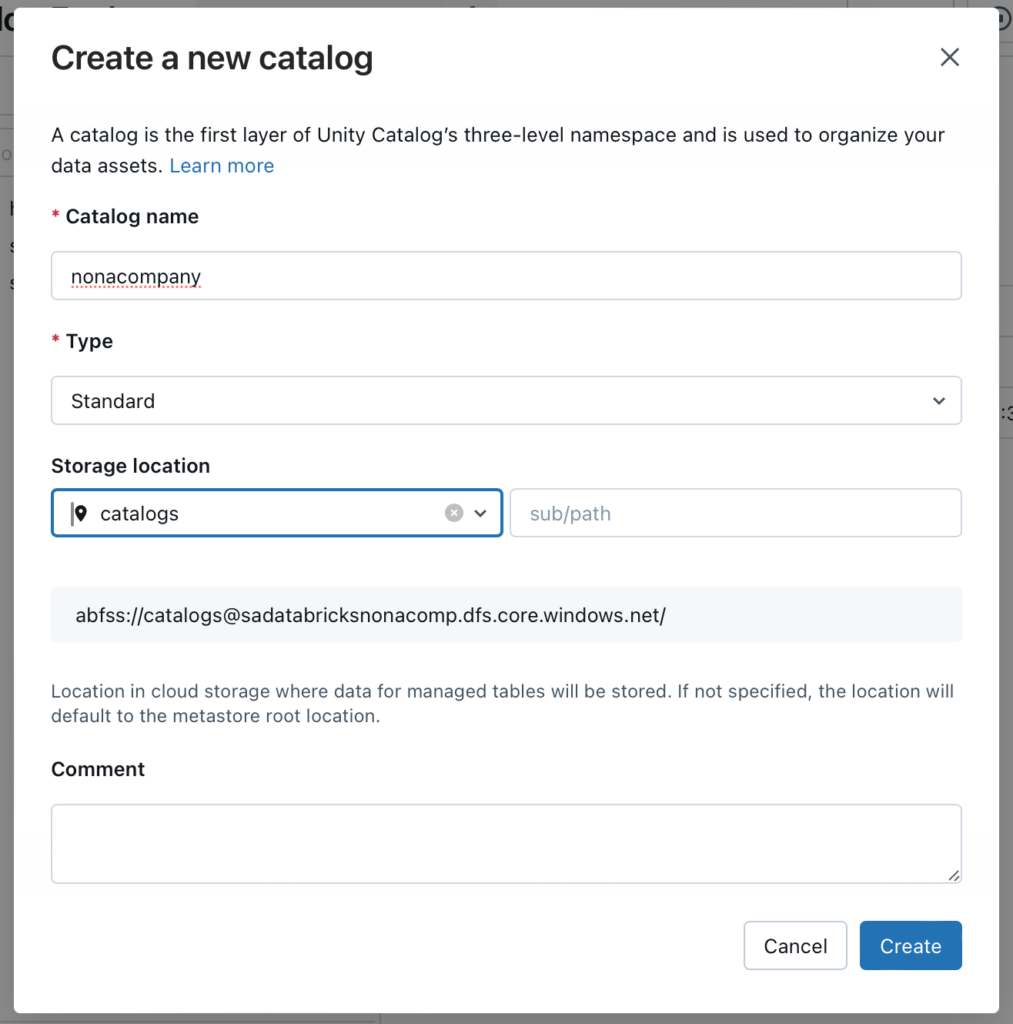
Schema’s erstellen
Innerhalb des Catalogs erstelle ich nun meine verschiedenen Schema’s analog dem Zonen-Modell, oder auch Medallion-Architecture. Ich klicke auf den entsprechenden Catalog und dann “Create schema”.
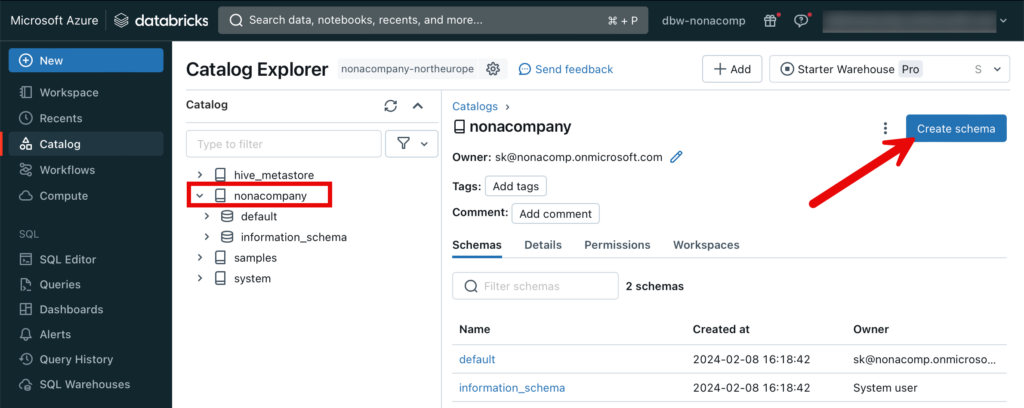
Ähnlich wie beim Catalog wähle ich die entsprechende Storage location aus.

Diesen Schritt wiederhole ich für alle Schema’s, bis es so aussieht:
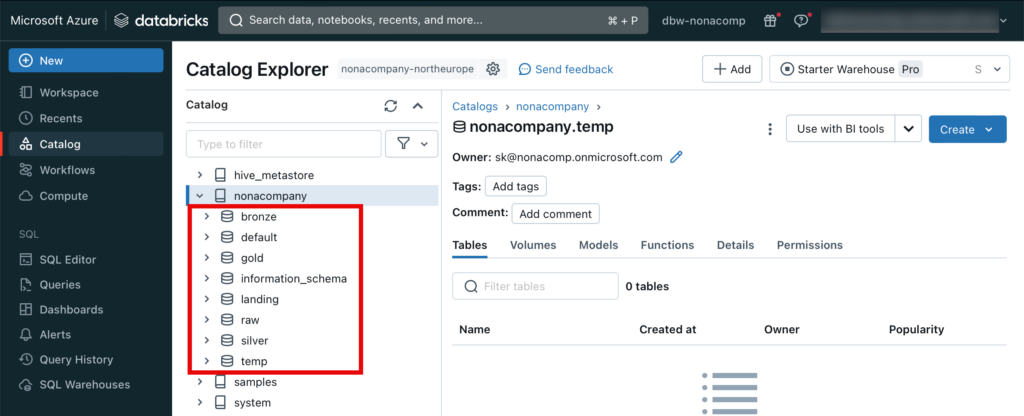
Volumes erstellen
Für Raw und Landing wollen wir mit Dateien direkt arbeiten, welche im Datalake gespeichert sind. Damit wir die Dateien direkt in Unity Catalog ansteuern können, verwenden wir sogenannte Volumes. Dazu wechsle ich zum Schema raw. Oben rechts befindet sich der Button “Create”, unter welchem sich ein Volume erstellen lässt.

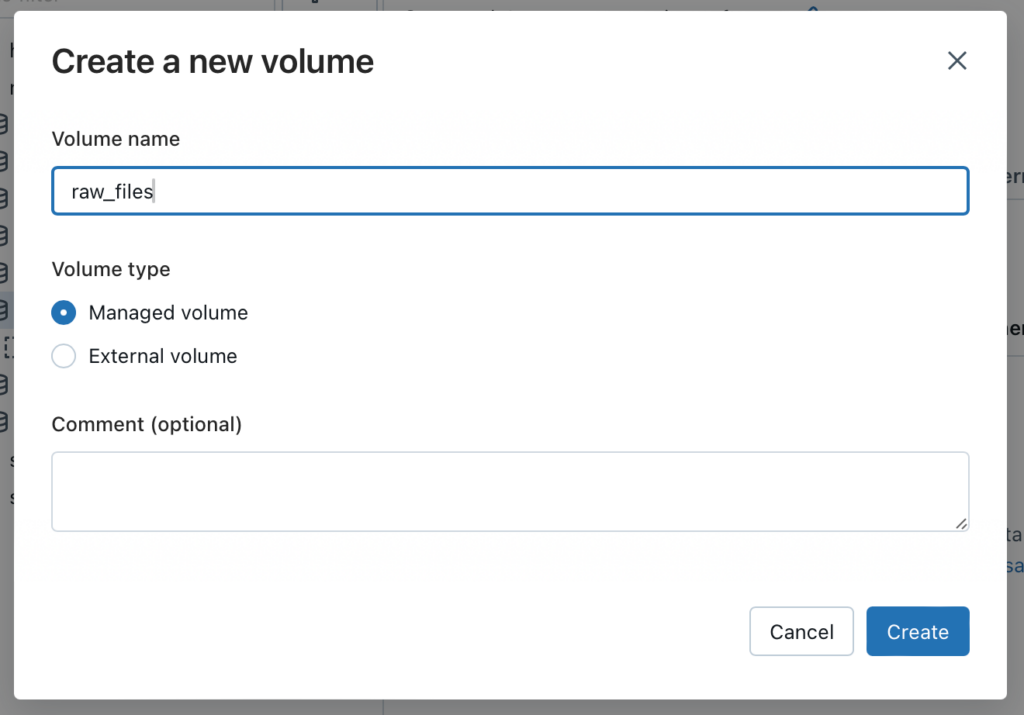
Denselben Schritt wiederhole ich auch für das Volumen für den Landing Container. Dateien, welche sich in dem Container befinden, können innerhalb von Databricks mit dem entsprechenden Pfad angesprochen werden. Im Beispiel Landing wäre das:
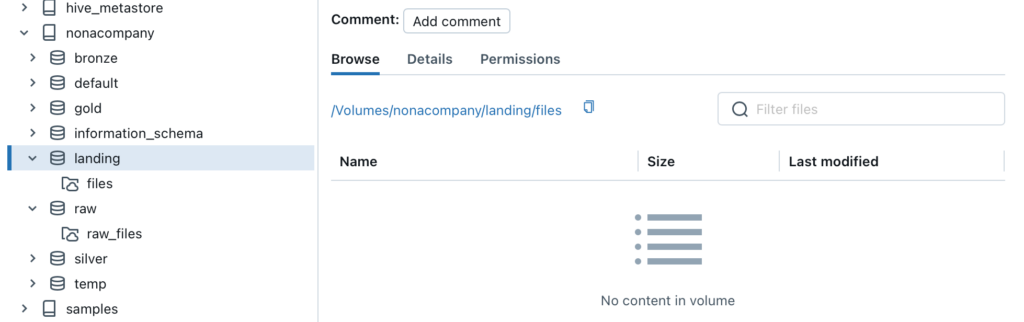
/Volumes/nonacompany/landing/files/[path]/[filename]
Der Pfad wird auch im entsprechenden Volume angezeigt.
Dateien in ein Volume hochladen
Es gibt mehrere Möglichkeiten, wie Dateien in ein Volume hochgeladen werden können. Zum einen kann zum Beispiel eine Data Factory verwendet werden, welche Dateien direkt in den Storage Account Container hochlädt. Oder es gibt auch die Möglichkeit, direkt im Databricks Workspace Dateien hochzuladend. Dies ist aber ein manueller Prozess und dementsprechend “umständlich”.


Möchte ich nun den Pfad für das hochgeladene File ermitteln, kann ich das über die GUI im Workspace tun.

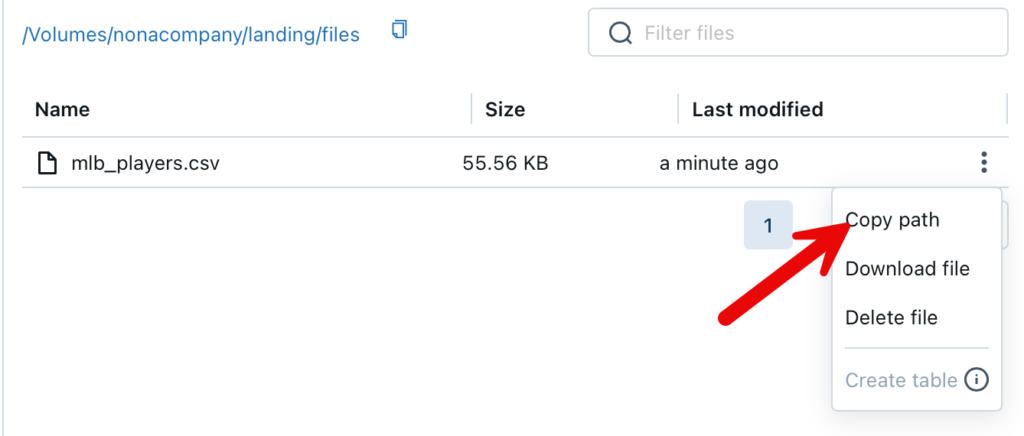
Das File kann nun über diese Pfad angesprochen werden:
/Volumes/nonacompany/landing/files/mlb_players.csv
Azure KeyVault erstellen
Wenn man eine Datenpipeline erstellt, gibt es immer wieder Situationen, in welchen man Secrets verwendet. Dabei handelt es sich um Passwörter, API-Key’s und so weiter. Diese sollte man auf gar keinen Fall im Klartext innerhalb des Codes speichern, wie zum Beispiel in einem Notebook. Für diesen Zweck kann man un Databricks einen Secret Scope verwenden. In Azure Databricks kann man den Secret Scope mit Azure KeyVault verbinden. So wird eine Verlinkung hergestellt zum KeyVault. Die Secrets können im KeyVault verwaltet und in Databricks angesprochen werden.
Zu diesem Zweck erstelle ich in der Ressourcengruppe einen neuen KeyVault.

Beim “Pricing Tier” wähle ich Standard.

Den Rest kann man auf Standard-Einstellungen belassen.
Als nächstes müssen die Berechtigungen auf den Key Vault vergeben werden. Diejenigen Gruppen/Personen, welche Secrets erstellen, erhalten die Rolle “Key Vault Secrets Officer”. Die Berechtigungen für den KeyVault können unter “Access Control (IAM)” gesetzt werden.

Bei den Rollen suche ich nach “Key Vault Secrets Officer”.
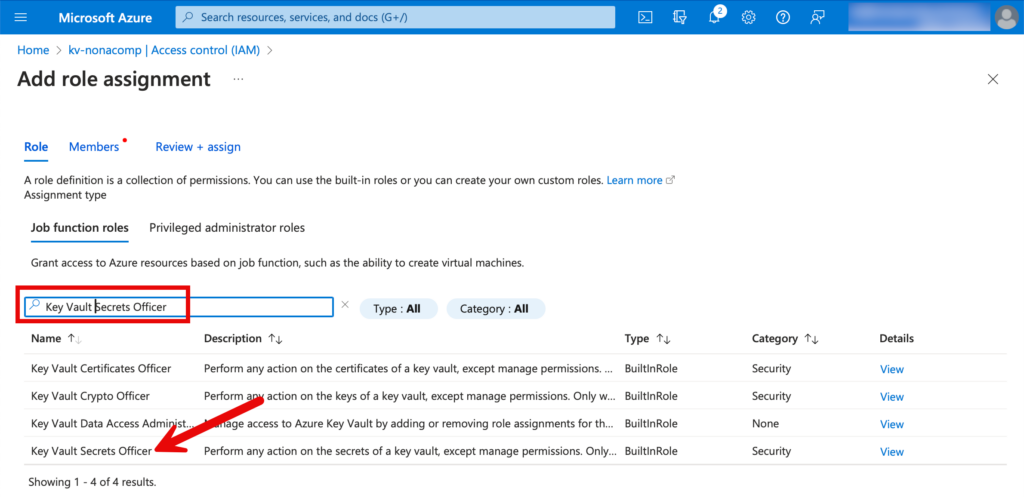
Dann suche ich die entsprechenden User/Gruppen in Entra-ID und weise sie der Rolle zu.

Für Gruppen/User, welche nur Leserechte haben sollten, vergeben wir die Rolle “Key Vault Secrets User”.

Via Databricks wollen wir ja ebenfalls die Secrets lesen, also fügen wir bei den Members ebenfalls den Memeber “Azure Databricks” hinzu.
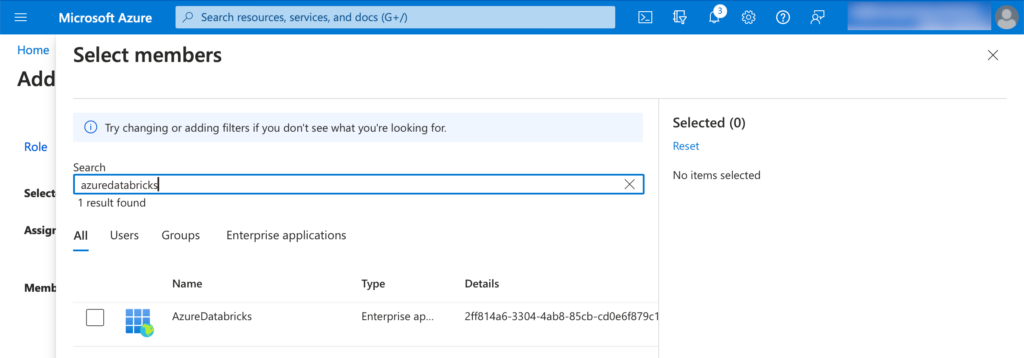
Secret Scope in Databricks erstellen
Wie ein Secret Scope in Databricks erstellt werden kann, ist ausführlich dokumentiert: https://learn.microsoft.com/en-us/azure/databricks/security/secrets/secret-scopes
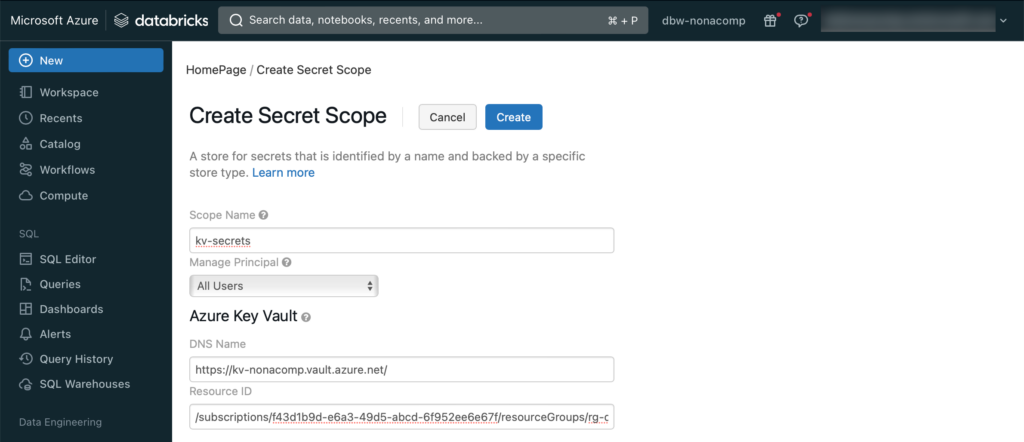
Damit manuell ein Secret Scope erstellt werden kann, muss die entsprechende URL eingegeben werden. Ich kopiere die URL von meinem Workspace und passe die URL an. Als Beispiel:
https://adb-6353763293941605.5.azuredatabricks.net/#secrets/createScope
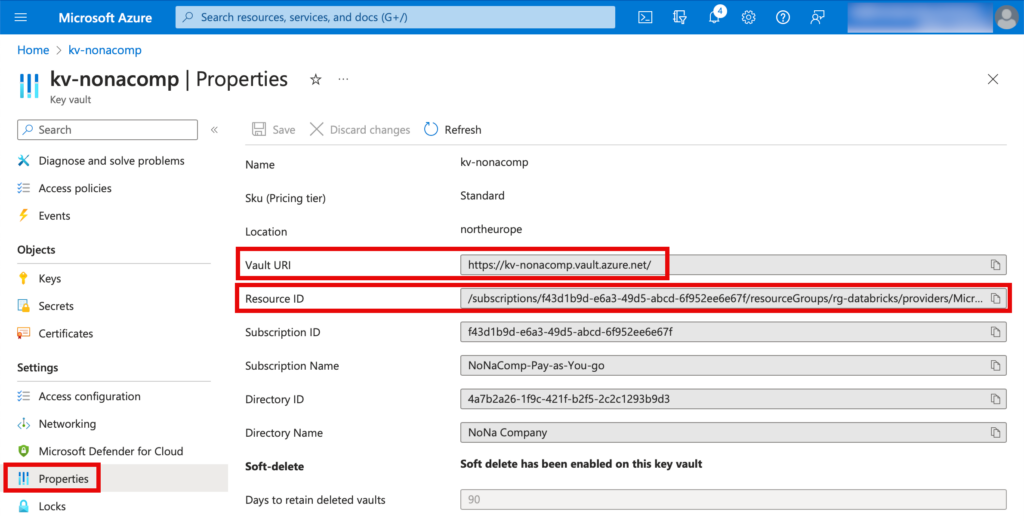
Die Details vom KeyVault können im Azure Portal entnommen werden:
Cluster erstellen
Zentraler Bestandteil vom Databricks Lakehouse sind Cluster. Ich erstelle einen simplen Cluster, indem ich in Databricks auf den Menüpunkt “Compute” wechsle.
Zum Thema der Cluster könnte ein eigener Artikel geschrieben werden. Ich beschränke mich hier in diesem Beitrag auf die Erstellung eines simplen “All-purpose compute” Clusters.

Bei der Runtime sollte man in der Regel eine LTS-Version wählen. Für kleinere Tests und Datenset genügt es, einen Single-Node Cluster zu erstellen mit einem kleinen Node Typ. In Azure ist dies das Image “Standard_F4s”. Falls nötig, kann der Cluster später vergrössert werden, oder ein zusätzlicher Cluster kann hinzugefügt werden.
🚨🚨🚨Wichtig: Damit keine unnötigen Kosten verursacht werden, sollte unbedingt die Einstellung vorgenommen werden, dass der Cluster sich nach einer bestimmten Zeit selbst terminiert! 🚨🚨🚨
Ich habe dies mal auf 30 Minuten eingestellt.

Secrets vom KeyVault lesen
Um zu testen, dass die Verlinkung vom KeyVault mit dem Databricks Secret Scope ordnungsgemäss funktioniert, mache ich einen kleinen Test. Im KeyVault selbst erstelle ich ein einfaches Secret.

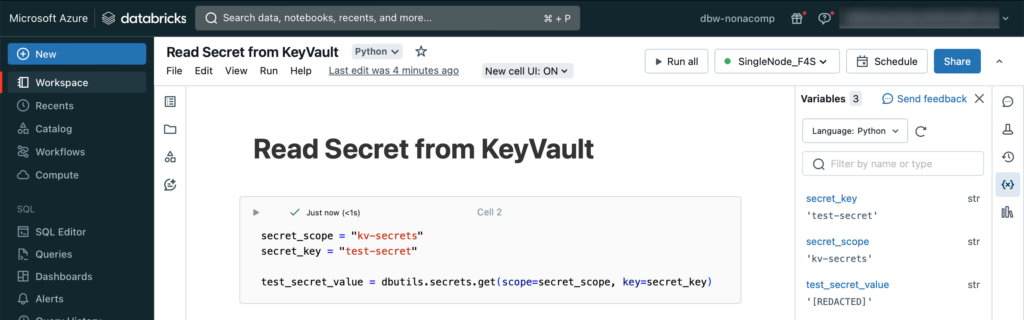
Innerhalb vom Databricks Workspace erstelle ich ein Notebook, in welchem ich das Test-Secrets einbinde.
secret_scope = "kv-secrets"
secret_key = "test-secret"
test_secret_value = dbutils.secrets.get(scope=secret_scope, key=secret_key)Diese Zelle im Notebook sollte erfolgreich ausgeführt werden. Überprüfen kann man dann im Variablen-Explorer, ob das Secret geholt wurde. Aus Sicherheitsgründen wird der Inhalt von Variablen, welche mit Secrets gefüllt werden, nicht im Klartext angezeigt, sondern es erscheint eine Meldung “REDACTED”.
Fazit
Mit der vorliegenden Schrit-für-Schritt-Anleitung sollte es auch für weniger erfahrene Personen möglich sein, eine komplette Databricks Lakehouse-Umgebung in Azure zu erstellen.
Wie schon erwähnt, ist dies ein einfaches Setup welches sich eignet um damit zu trainieren, Use Cases zu testen oder einen einfachen Proof of Concepts zu erstellen. Falls du einen Schritt weitergehen möchtest, und ein Lakehouse in einer produktiven Umgebung bereitstellen möchtest, gibt es verschiedene andere Punkte zu beachtet, unter anderem Security, Monitoring, Benutzer/Gruppenverwaltung, und so weiter.
Weiter möchte ich anmerken, dass viele Schritte, welche ich hier in einem manuellen Prozess gezeigt habe, automatisiert werden sollte. Unter anderem das Deployment der Ressourcen sollte via “Infrastructure as Code” automatisiert werden. Ebenfalls kann die Erstellung der Objekte im Unity Catalog via Code erfolgen. In einem zukünftigen Beitrag werde ich entsprechende Beispiele zur Verfügung stellen.